-
Type:
Improvement
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.12.5, 2.13.2
-
Component/s: Performance
-
None
-
Environment:Driver 2.13.2
Oracle JDK 1.8
-
None
-
None
-
None
-
None
-
None
-
None
-
None
TL;DR
In the 2.13.x driver, the write command paths do not leverage the Mongo client's PoolOutputBuffer pool while the write protocol codepaths do.
Details
The Mongo client instance maintains a _bufferPool of 1000 PoolOutputBuffer's.
For write protocol operations
When talking to a <=2.4 mongod, or using UNACKNOWLEDGED writes to a >=2.6 mongod, this _bufferPool is used to provide a PoolOutputBuffer for both encoding the write as well as reading the response (OutMessage).
For write command operations
Sending the op to the mongod (sendWriteCommandMessage()) and receiving the response (receiveWriteCommandMessage(() creating a new DefaultDBDecoder) each create in a new unpooled PoolOutputBuffer.
The consequence is that while PoolOutputBuffer does contains a static pool of "extra" byte arrays which are used for growing, each PoolOutputBuffer instance still has a minimum 32KB allocation for the _mine and _chars buffers – a nontrivial amount per operation.
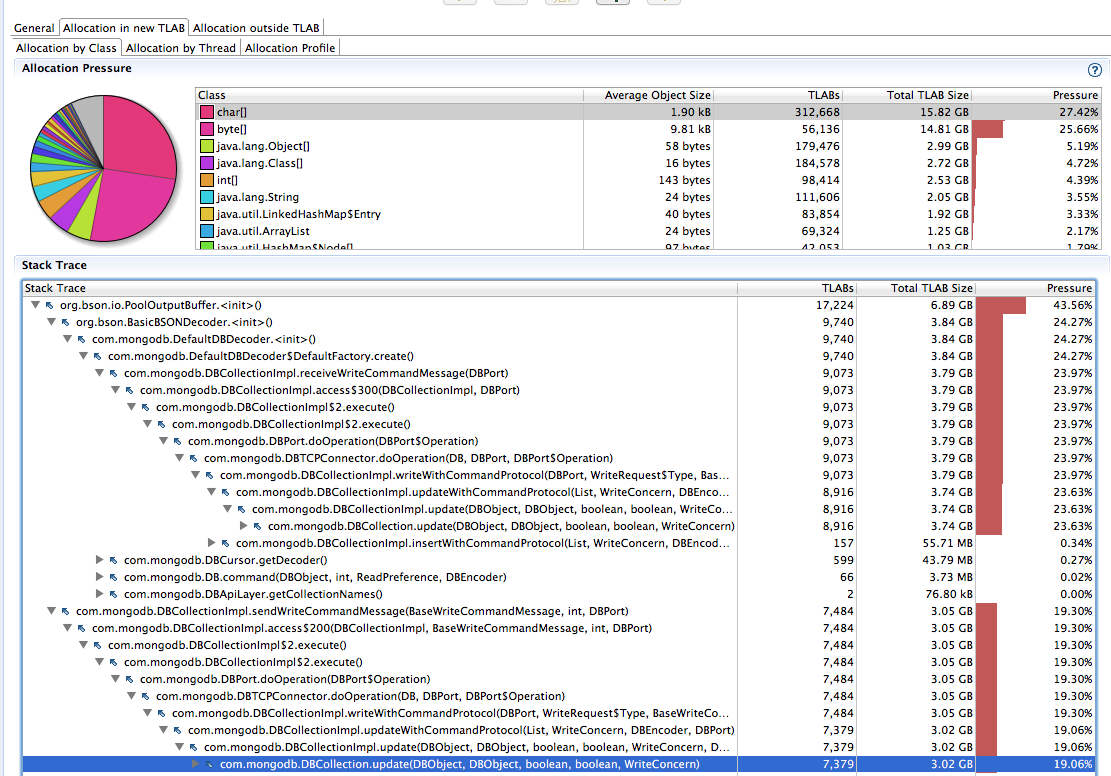
Consider the following flight recorder sample:
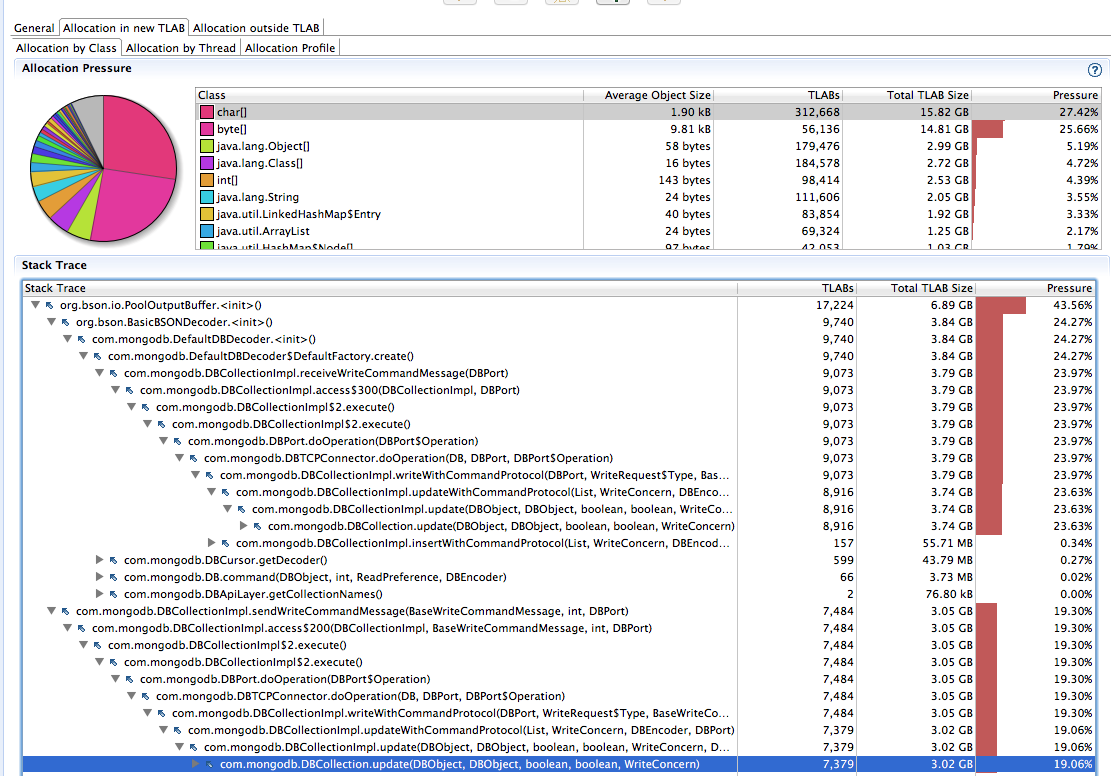
The above shows for allocations in TLAB by class, char[] and byte[] contribute to 50%+ of all allocation pressure. And for this application, 43% of the char[] allocations are from PoolOutputBuffer on the write command paths. (Not shown above, but 83% of byte[] is PoolOutputBuffer.)
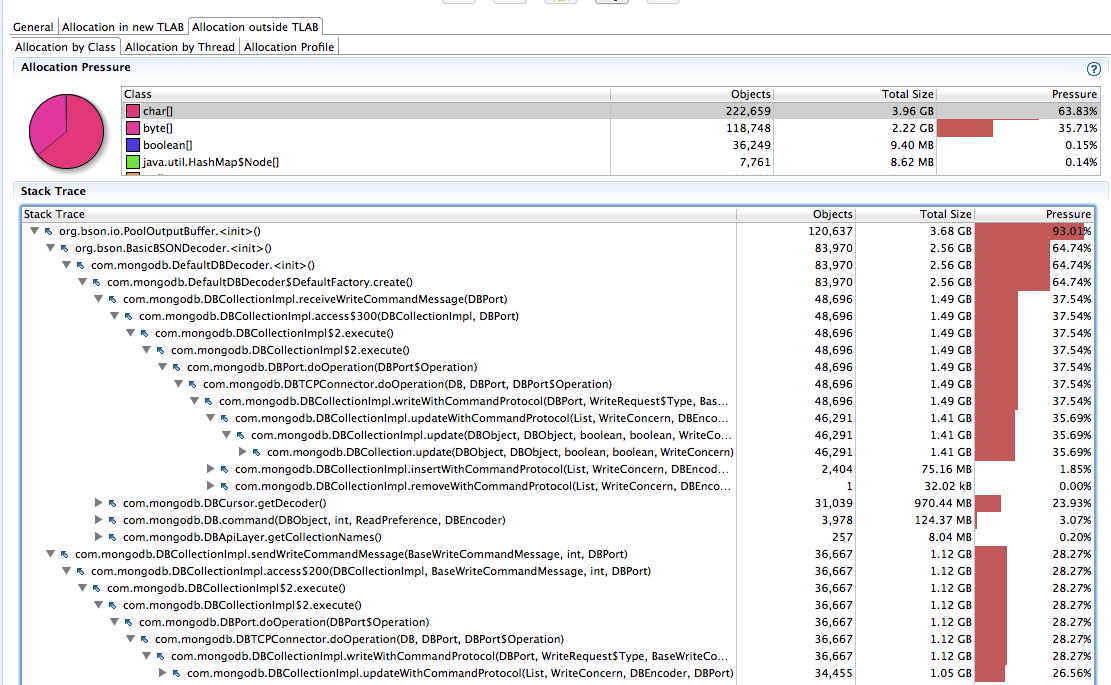
Again for this write-heavy application anyway, outside TLAB pressure shows even higher pressure:
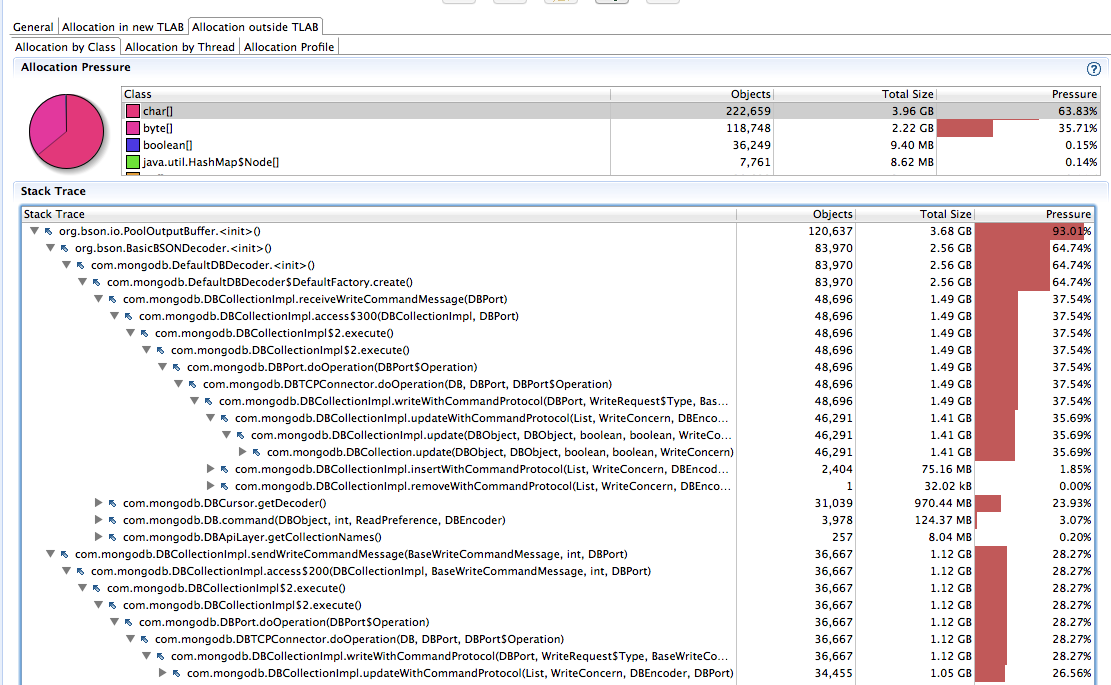
Here we see the byte[] and char[] combine to ~93% of all allocation pressure, and the majority of each again as PoolOutputBuffer on write command paths (83% and 93%, respectively).