-
Type:
Bug
-
Resolution: Fixed
-
Priority:
 Minor - P4
Minor - P4
-
Affects Version/s: 3.1.13
-
Component/s: None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
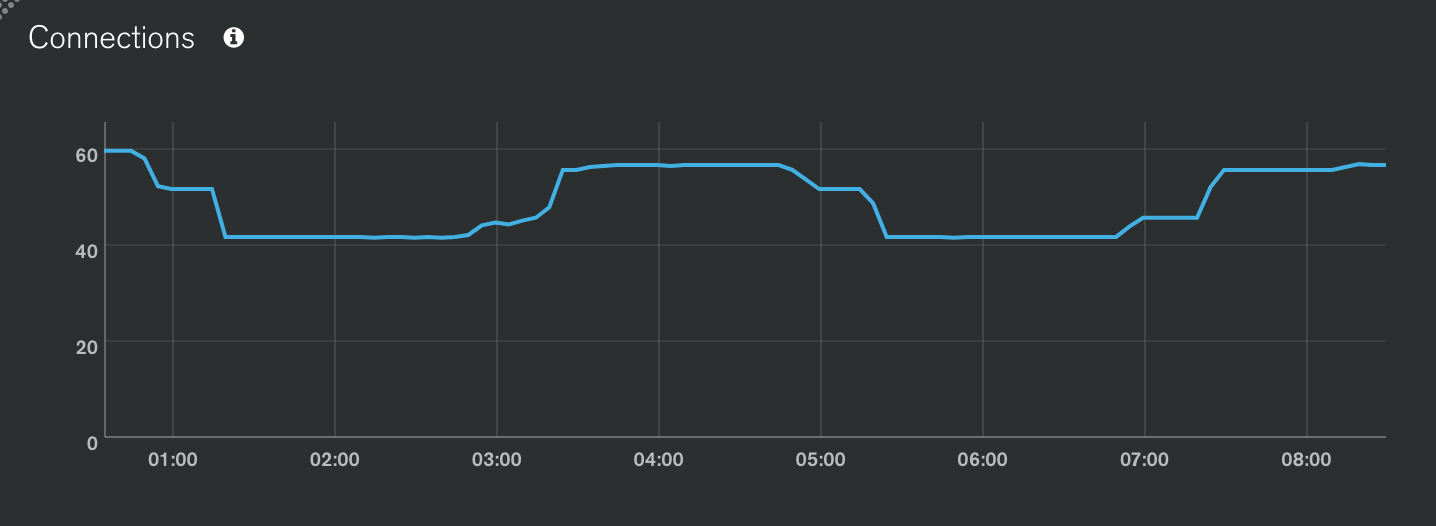
In our production environment, we have a mongo cluster with 10-100 inserts/updates per second and about 50-200 other operations per second. We have a cluster of node servers that do these operations, with the majority of operations going to the primary.
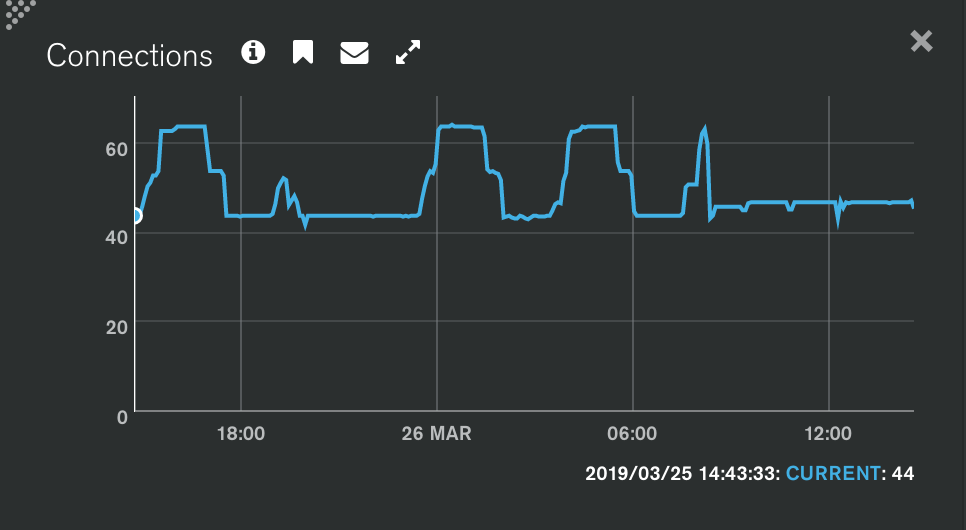
We noticed CPU levels rising slowly on our node servers. Over 1-2 days, CPU levels double and it appears that that is caused by increased garbage collection. This suggested a memory leak and we did a lot of analysis. We ultimately concluded that there is a slow leak in the mongo driver. If we restart our node process, everything returns immediately to normal and then slowly grows again over the next day.
Our application is structured nicely so that we are confident that we are closing every cursor that we open. After reviewing heap dumps, we saw significant growth in the number of NodeObject instances over time and the contents of these appear to be mongo Session objects. We do not use cursors with timeouts disabled.
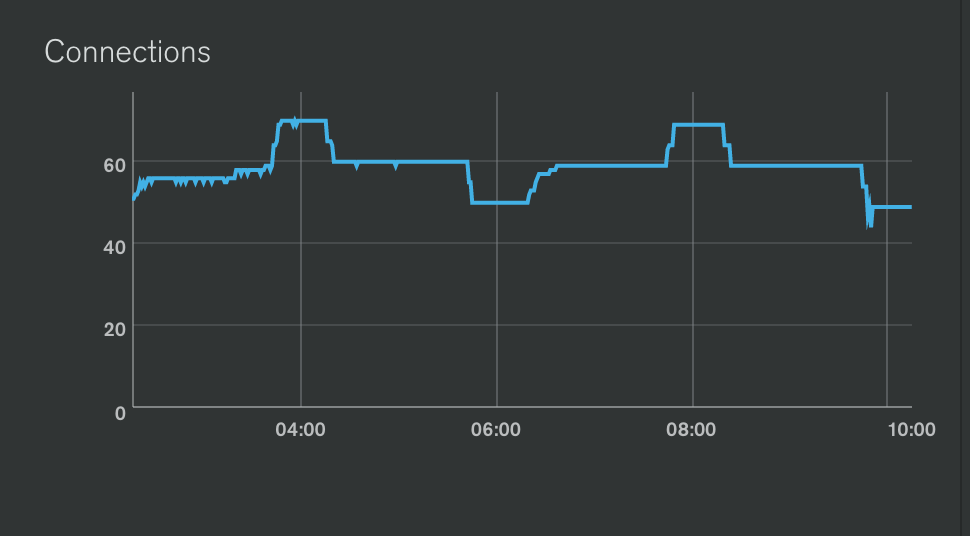
We are now cycling our mongo connections every 4 hours and this has resolved the issue for us. By "cycling", I mean that we start using a new connection and then after 2 hours, close the older connection and delete it.
This has resolved our issue for us. But I felt that we should report this to you.