-
Type:
Improvement
-
Resolution: Unresolved
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: BSON
We are been running into memory issues while pulling large Mongo result sets into memory, and after lots of memory profiling the issue seems to be related to ObjectId, specifically how memory inefficient Buffer/ArrayBuffer is when storing lots of small Buffers.
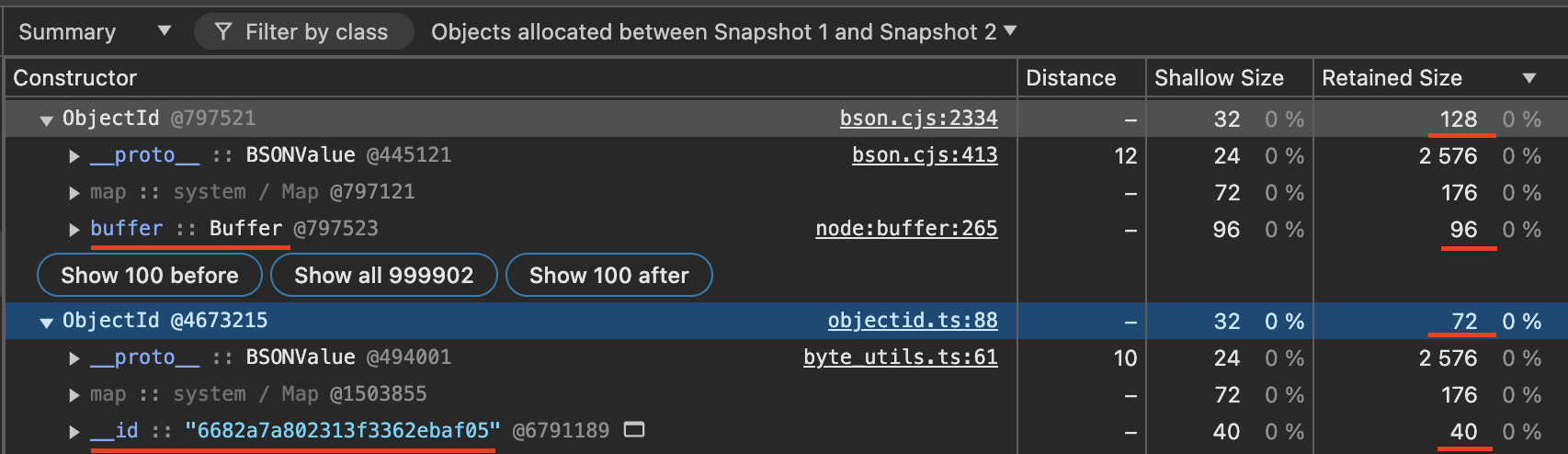
We were expecting an ObjectId to consume ~12bytes of memory (+ some overhead), but in reality this consumes 128 bytes per ObjectId (96 bytes for just the Buffer).
I opened an issue with the NodeJS Performance team but this appears to be working as designed: https://github.com/nodejs/performance/issues/173
Storing a string in Node/V8 is much more memory efficient since it's a primitive. A 24 character hex string only consumes 40 bytes of memory, AND it's much faster to serialize/deserialize.
Memory Usage
With this change, retained memory usage is reduced by ~45% (ObjectId size decreases from 128 bytes to 72 bytes) ** and young memory allocation is reduced by ~57% during deserialization. Currently, the hex string (40 bytes) already needs to be allocated in memory as ESON, then deserialized into BSON (which allocates 96 bytes for the buffer), then the string needs to be garbage collected. Since V8 uses string interning pool the string does not need to be reallocated if we persist it in the ObjectId.
By reducing the amount of memory that needs to be allocated we are further improving performance since garbage collection is quite expensive.
 Performance Tests
Performance Tests
I made the change to persist ObjectId as string in memory, and we only need to use Buffer to generate a new pk. Tested on M1 MacBook Pro
| Operation | ObjectId (ops/sec) | ObjectId STRING (ops/sec) | Relative Improvement (%) |
|---|---|---|---|
| new ObjectId() | 10,662,177 | 5,842,941 | -45.18% |
| new ObjectId(string) | 5,316,351 | 11,913,614 | 118.00% |
| deserialize | 3,630,156 | 11,401,144 | 214.06% |
| serialize | 11,498,443 | 82,022,643 | 613.54% |
| toHexString | 11,314,960 | 81,086,841 | 616.57% |
| equals | 39,653,912 | 44,413,312 | 11.99% |
new ObjectId() does appear to be slower at first glance because it still uses Buffer to generate an ObjectId then it has to convert the buffer to hex string, but once you consider most paths will have to serialize that ObjectId after creating a new PK then it still comes out marginally faster.
| Operation | ObjectId (ops/sec) | ObjectId STRING (ops/sec) | Relative Improvement (%) |
|---|---|---|---|
| new ObjectId() + serialize | 5,785,814 | 5,900,631 | 2% |
Example
Lets say we have a MongoDB collection with some user documents like this that points to another document.
{
_id: ObjectId,
name: string,
addressId: ObjectId
}
Let's say we want to grab a bunch of the documents. 1 million in this example. Lets project to just the ObjectIds so other types don't skew our numbers
const docs = await collection.find({}, { limit: 1000000, projection: { _id: 1, addressId: 1 } }).toArray() // lets grab 1 million documents
BEFORE: 471 MB used
AFTER: 262MB used
Use Case
The above example was a little contrived, but we do have use cases where we will pull in large numbers of documents into memory to build Directed Acyclic Graphs, where each document represents an edge in the graph (this is particularly needed since MongoDB $graphLookup is quite limited).
This could also occur frequently on a server where many users are requesting small batches of documents.
User Impact
- I believe this issue is greatly effecting all users of MongoDB in JS environments (NodeJS/browser) regardless of use case, just to different extents. By making this change I believe we would improve performance and reduce memory usage for all users.
Acceptance Criteria
Implementation Requirements
- ObjectId class should only persist hex string representation of ObjectId
- ObjectId class API should not have any breaking changes
- All currently ObjectId functionality should behave as it does today
- Performance for most use cases must not degrade
- cacheHexString property to be deprecated
- Optional: Add cacheBuffer option to cache buffer
Testing Requirements
- unit tests
- perf tests
Documentation Requirements
- DOCSP ticket, API docs, etc
Follow Up Requirements
- additional tickets to file, required releases, etc