-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
-
(copied to CRM)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
We're running Rails application on latest mongoid with mongo ruby driver (2.16.0).
We're using Atlas managed database (primary + two replicas).
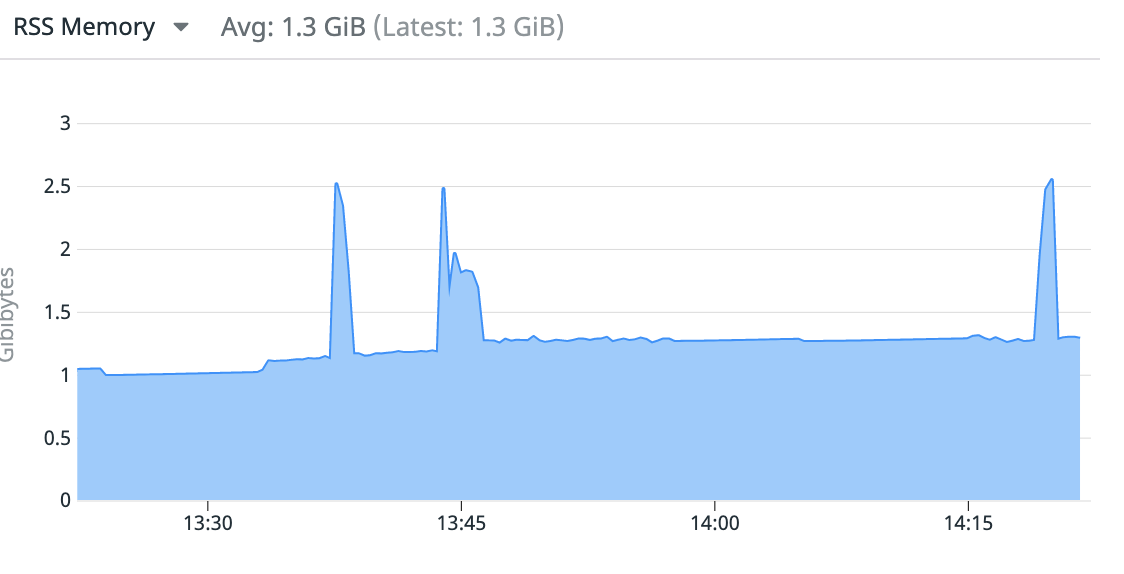
Whenever primary goes down, due to either scheduled maintenance or "Test Failover" option we've noticed increased memory usage in our applications. Memory use goes from 1.2GB to 2.5GB for a minute or two when primary is down. It recovers shortly after old primary reconnects as secondary and goes back to 1.2GB.
When primary goes down, mongoid logs around 7k messages in 1 minute from single puma worker, all of them are "Error running awaited hello on ..." pointing to the very same node of the cluster. This suggests the heartbeat is initiated 7k times in 1 minute (We're on default setting so it should be 1 heartbeat per 10seconds).
Log timings coincide with memory use spikes from the application, here you can clearly see 3 primary restarts: 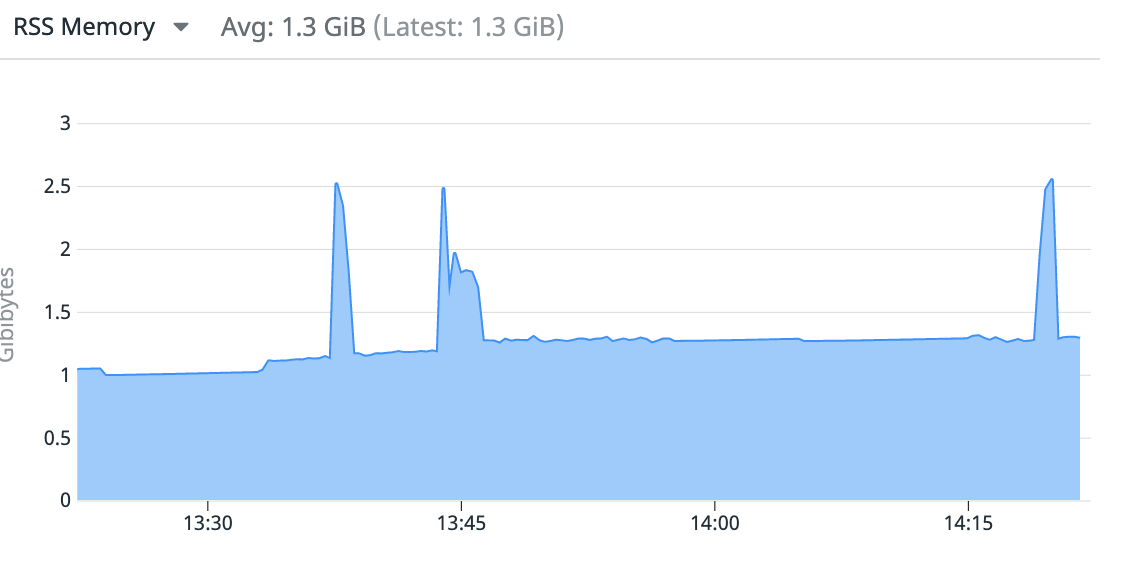
Since memory use spikes are so short it was hard to check heapdump but I was lucky enough to get it, reported suspicious values were:
retained memory by class
-----------------------------------
6294912 Thread
retained memory by location
-----------------------------------
6297024 /X/vendor/bundle/ruby/2.6.0/gems/mongo-2.16.0/lib/mongo/background_thread.rb:112
Again, it wasn't easy to track down what exactly retained the memory, as background_thread is an abstract class for background jobs, but with some more logging of the call stack I narrowed the cause down to publish_heartbeat function from lib/mongo/monitoring.rb and ServerHeartbeatFailed event being published 7k times in a minute: https://github.com/mongodb/mongo-ruby-driver/blob/master/lib/mongo/monitoring.rb#L333-L340
Adding simple sleep of 200ms into error reporting function and using the driver prevented the memory spikes from happening https://github.com/mongodb/mongo-ruby-driver/pull/2369/files
Application with fixes behaved much better and memory usage remained stable (AVG memory is higher as application was running for a bit longer):

This behaviour is explained by the comment in the code:
# The duration we publish in heartbeat succeeded/failed events is
# the time spent on the entire heartbeat. This could include time
# to connect the socket (including TLS handshake), not just time
# spent on hello call itself.
# The spec at https://github.com/mongodb/specifications/blob/master/source/server-discovery-and-monitoring/server-discovery-and-monitoring-monitoring.rst
# requires that the duration exposed here start from "sending the
# message" (hello). This requirement does not make sense if,
# for example, we were never able to connect to the server at all
# and thus hello was never sent.
but I believe it isn't the right approach to not count heartbeat time for heartbeats that were never able to connect to the server.
Probably sleep in that place isn't ideal and this should be handled somewhere higher in the abstraction, when the actual heartbeat is scheduled but I'm leaving it up to the maintainers.