-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
Affects Version/s: 1.4.0, 1.4.1
-
Component/s: None
-
None
-
Environment:MongoHQ, semi-dedicated environment, 2 replicas and an arbiter (orchid)
Ruby 1.9.2, mongo/bson/bson_ext 1.4.1, Mongoid 2.0.2
-
None
-
Major Change
-
None
-
None
-
None
-
None
-
None
-
None
The short story is that upgrading to 1.4.0 and then 1.4.1 made our production environment (almost) toast.
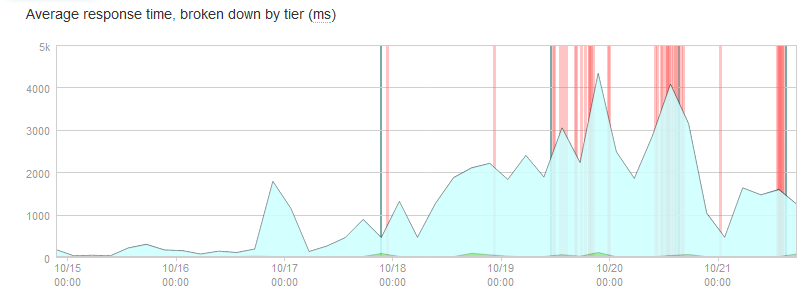
- new-relic.png: shows the query performance right after deployment w/ 1.4.0 and then 1.4.1 until the problem went away, downgrade to 1.3.1
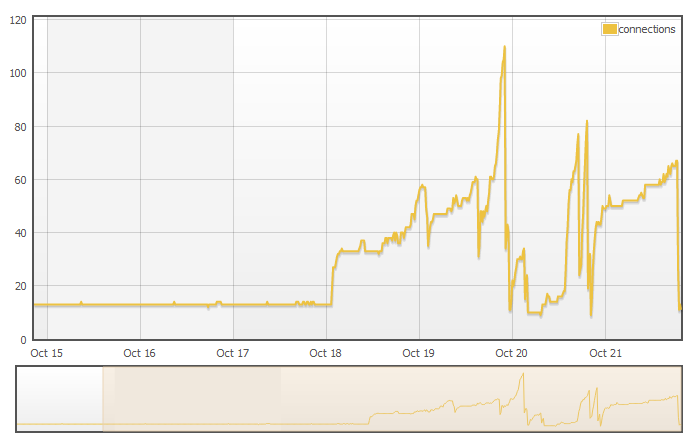
- mongohq-conncount.png: shows the number of connections from the rails app to mongo varying significantly up to 77, downgrading to 1.3.1 put it back in a stable number of 11
- mongostat.png shows nothing unusual while queries timeout from ruby
a random sampler
30.times { puts Benchmark.realtime
{ Mongoid.master.connection.active? }; sleep(1) }) which executes db.runCommand(
{ ping: 1 }).
0.024342775344848633
0.08080220222473145
2.113878011703491 <-------- not ok
0.023059368133544922
0.03187060356140137
- at the same time we're experiencing timeouts between replicas, but with 1.3.1 it doesn't affect performance, mongodb log
Fri Oct 21 20:50:01 [ReplSetHealthPollTask] EINTR retry
Fri Oct 21 20:50:01 [ReplSetHealthPollTask] DBClientCursor::init call() failed
Fri Oct 21 20:50:01 [ReplSetHealthPollTask] replSet info arbiter0.orchid.mongohq.com:10001 is down (or slow to respond): DBClientBase::findOne: transport error: arbiter0.orchid.mongohq.com:10001 query:
Fri Oct 21 20:50:05 [ReplSetHealthPollTask] replSet info arbiter0.orchid.mongohq.com:10001 is up