-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: Index Maintenance
-
Storage Execution
-
Fully Compatible
-
ALL
-
Platforms 15 (06/03/16)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Running a longevity compact test I realized mongod memory usage increases all over the time until it eats a quantity of memory >= total available RAM and get kicked out of the scheduling by the OS.
The following test run continuously in a loop eventually reproduce the behavior described above.
var func = function(i) { var new_db = "foo" + i.toString(); db = db.getSiblingDB(new_db); var ns = "goo" + i.toString(); return db.runCommand({compact: ns}); } for (var k = 1; k <= 12; ++k) { var new_db = "foo" + k.toString(); db = db.getSiblingDB(new_db); var ns = "goo" + k.toString(); db[ns].ensureIndex({name: 1}); } for (var j = 1; j <= 12; ++j) { var start = new Date().getTime(); threads = []; for (var k = 1; k <= j; ++k) { t = new ScopedThread(func, k); threads.push(t); t.start(); } for (var k in threads) { var t = threads[k]; threads[k].join(); //printjson(t.returnData()); } var elapsed = new Date().getTime() - start; print(elapsed); }
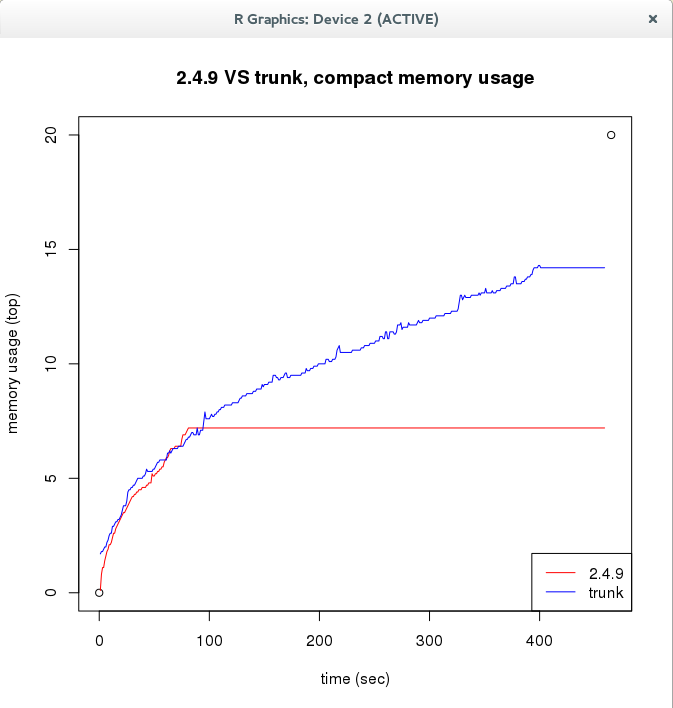
top/htop clearly show on a machine equipped with 48GB of RAM 98% of it eaten by mongod. Running the same test against 2.4.9 shows memory usage doesn't go over 7-8% in the same workload.
The dataset is made by 12 different collections sitting in 12 different databases – every collection is made by 1million documents of the form
{_id: ObjectId(), name: random_string}
The code used to generate the random strings can be found here
#!/bin/bash STRLENGTH=32 NUMFILES=16 RANGE=1000000 for i in `seq 1 $NUMFILES` do rm -rf output${i}.txt done for i in `seq 1 $NUMFILES` do for j in `seq 1 $RANGE` do base64 /dev/urandom | head -c ${STRLENGTH} >> output${i}.txt echo "" >> output${i}.txt done done
and the code to populate the database can be found attached (uses the C++ driver)
- is depended on by
-
SERVER-12332 choose std::sort or stable_sort for external sort
-
- Closed
-