-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 2.6.4
-
Component/s: Sharding
-
None
-
Sharding
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Hi
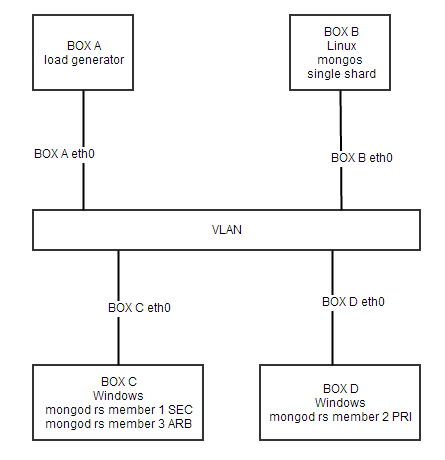
During some lab testing to measuring the failover response time and behaviour, we created diferent scenarios:
1) Graceful failover (replSetStepDown)
2) Process aborted (killed externally in this simulation by task manager)
3) System outage (removing network cable)
We were using a 2 node replica set with an extra arbitrer and a mongos on top of them (servers were started with --shardsvr and --replset). Mongos was running in a linux box, while the mongod were running in windows, all using 2.6.4.
In scenarios 1 and 2, updates were aborted with errors, and started working once the new primary was elected.
In the 3rd scenario the client gets stuck in the update command (using c# driver latest stable version). we could overcome the issue by setting the socketTimeoutMS option in the connection string, but in principle the preferred behaviour is the one shown in scenarios 1 and 2.
Test has been repeted several times to avoid mistakes.
As a side note times were: 3, 16 and 23 seconds, for the three scenarios.