-
Type:
New Feature
-
Resolution: Won't Do
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.7.5
-
Component/s: Sharding
-
Sharding EMEA
-
None
-
None
-
None
-
None
-
None
-
None
-
None
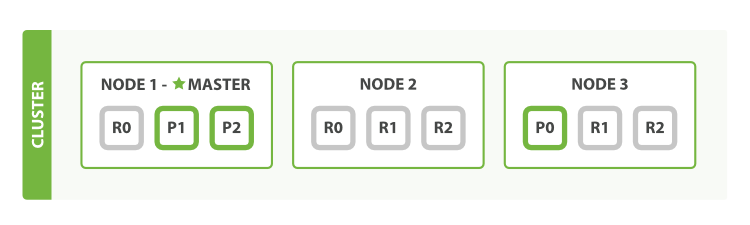
In ElasticSearch, each "index" (equivalent to a database in our parlance) is split across multiple "shards", each of which holds a portion of the data. Shards can be either primary shards, or replica shards (redundant copies of the data).
When you create a ES index, you can specify both the number of shards, and the number of replicas to create. For example, the below will create a index called "blogs", which has 3 shards, and 1 replica for each shard:
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
As you add and remove nodes from a cluster, ES will transparently handle re-balancing the shards, as well as re-creating replica-shards to maintain the specified number of replicas. ES will not put a primary shard and a replica for that primary shard on the same node - if you don't have enough nodes for it to re-balance properly, it will report the cluster status as degraded (e.g. yellow), until you add another node.
There is a description of the operational semantics in ES's Life in a Cluster document, as well as a discussion of it in Exploring ElasticSearch's Advanced Topics chapter.
So from an operational point of view, it is much simple to manage adding/removing nodes, and changing the number of replicas versus in MongoDB.
Another advantage is that it makes it seamless to multiplex multiple shards onto one node. That is, ES will automatically arrange things so that each node will automatically contain both a primary shard, as well as replica shards for other primary shards:
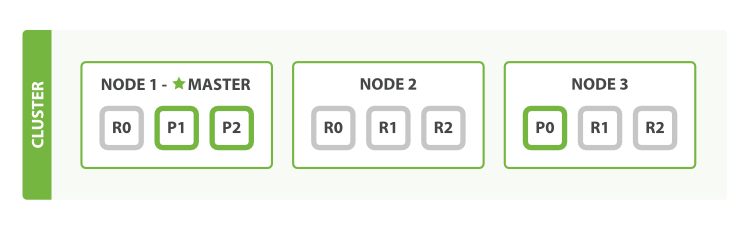
Cassandra 2.0 does something similar using a replication factor, which is defined per keyspace, however, it's nowhere near as automated and transparent to the end-user as ES.