-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.8.0-rc0
-
Component/s: Performance, Replication, Storage
-
Fully Compatible
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
This may be related to SERVER-16235, but filing as a separate ticket since my understanding is that a workaround is in place to prevent SERVER-16235 from impacting the oplog, plus the symptoms here are a bit different, so this may be a separate issue.
Tested on build from master this afternoon (365cca0c47566d192ca847f0b077cedef4b3430e).
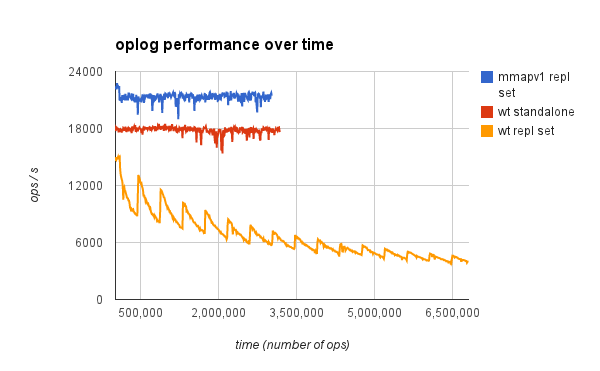
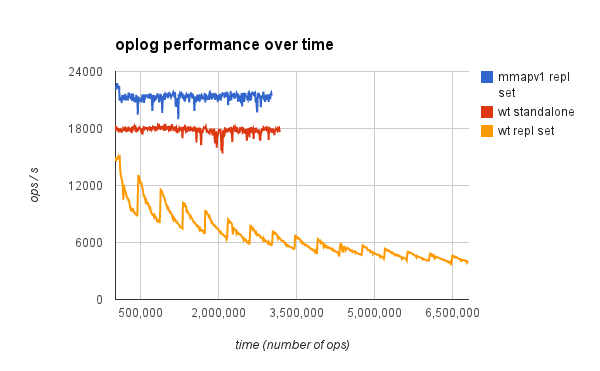
- Test on single-node replica set repeatedly updates the document in a single-document collection in order to generate a lot of oplog entries while minimizing work to actually perform each op, in order to emphasize oplog performance.
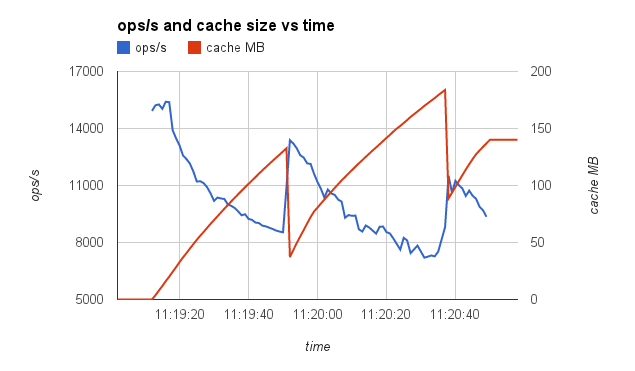
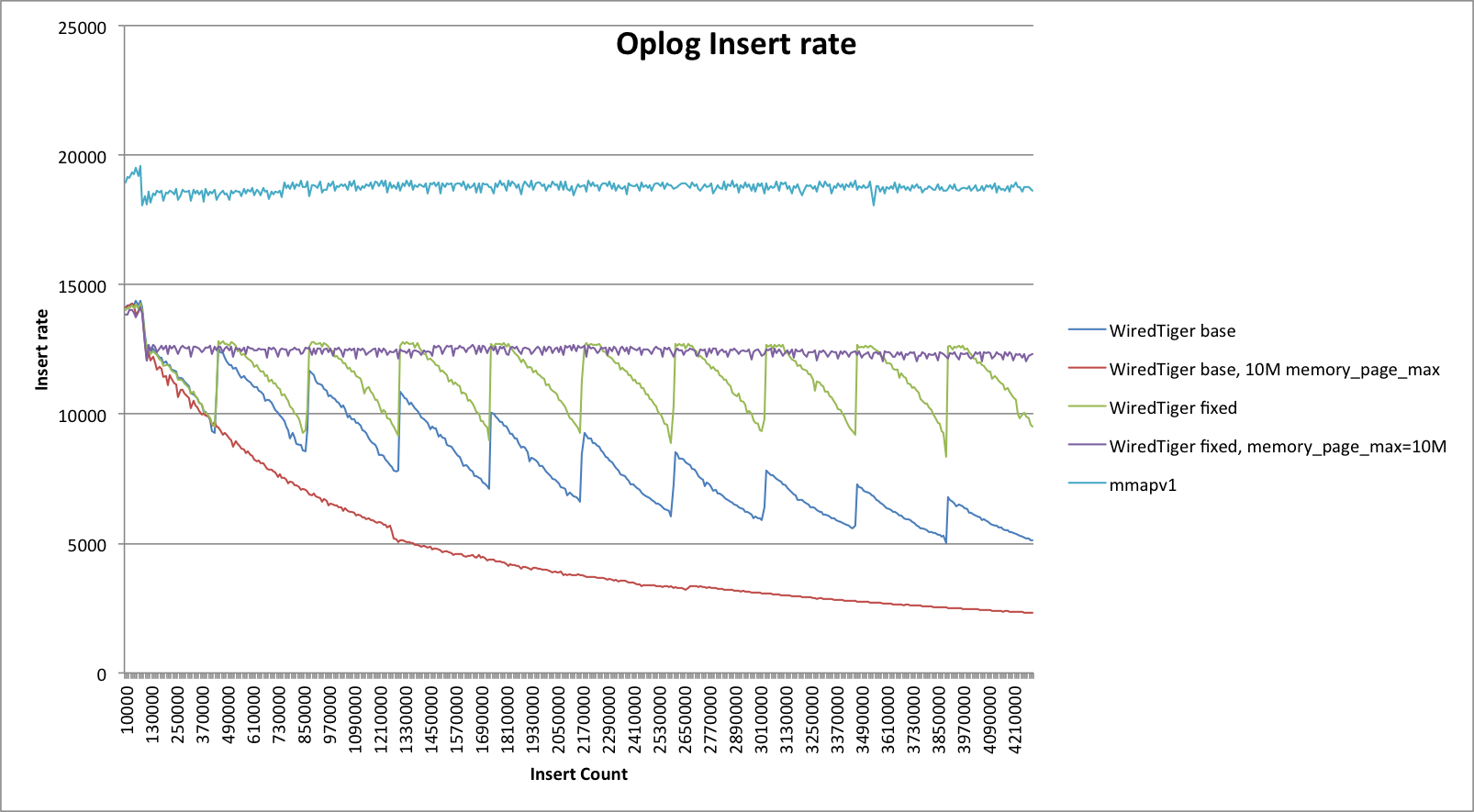
- Yellow graph below shows declining performance over time (measured in number of updates done). Graph shows same decline starting at first oplog wraparound at about 90 k inserts as seen in
SERVER-16235, but then it recovers and begins a cycle of repeated declines and recoveries. But superimposed on this is a longer term downard trend, and that possibly distinguishes this issue fromSERVER-16235. Not clear from this data whether the asymptote is >0. - Red graph shows that the decline goes away for the same test in a standalone instance, confirming that this is an oplog issue.
- Blue graph shows that decline is not seen with mmapv1, confirming that this is a WT-specific issue.
- Restarting mongod (not shown) resets the behavior back to time 0.
db.c.drop()
db.c.insert({_id:0, i:0})
var every = 10000
var bulk = db.c.initializeOrderedBulkOp();
var t = new Date()
for (var i=0; i<=count; i++) {
if (i>0 && i%every==0) {
bulk.execute();
bulk = db.c.initializeOrderedBulkOp();
tt = new Date()
print(i, Math.floor(every / (tt-t) * 1000))
t = tt
}
bulk.find({_id:0}).updateOne({_id:0, i:i})
}
- is depended on by
-
-
- Closed
-
- is related to
-
-

- Closed
-
-
-
- Closed
-
- related to
-
-
- Closed
-
-
WT-15893 Unexpected large amount of phylog for seemingly small workloads
-

- Backlog
-