-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.0.2
-
Component/s: Storage
-
None
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Hello,
We are running a single dev server mongodb (almost every parameter is default, except directoryPerDB), no replication, just for testing (we'll definitely put replication, even on dev, after this problem...).
We've been running some very long processes over the week-end, that created over 200 GB of "aggregated" data (not necessarily with aggregation framework).
This morning, we had a crash on our MongoDB dev server. The crash was provoked by us moving data files from a certain DB that was not used by MongoDB at this moment.
Well, it seems that MongoDB noticed that and decided to crash, too bad but it was kinda expected.
Please note that mongodb was doing lots of updates on another database at this same moment (enough updates to get the whole instance very slow).
We started mongodb again, and here's the log :
2015-05-26T08:35:41.649+0200 I WRITE [conn22170] update cicr_results.cr2 query: { _id: "xxxxxxxx" } update: { $set: { s.ra: 839.0 } } nscanned:1 nscannedObjects:1 nMatched:1 nModified:1 keyUpdates:0 writeConflicts:0 numYields:0 locks:{ Global: { acquireCount: { r: 2553, w: 11828711, W: 1 } }, MMAPV1Journal: { acquireCount: { w: 11828398 }, acquireWaitCount: { w: 45575 }, timeAcquiringMicros: { w: 443975376 } }, Database: { acquireCount: { r: 2553, w: 11828711 } }, Collection: { acquireCount: { R: 2553, W: 11828711 } } } 219ms
2015-05-26T08:35:41.649+0200 I COMMAND [conn22170] command cicr_results.$cmd command: update { update: "cr2", updates: [ { q: { _id: "xxxxxxx" }, u: { $set: { s.ra: 839.0 } }, multi: false, upsert: false } ], ordered: true } keyUpdates:0 writeConflicts:0 numYields:0 reslen:55 locks:{ Global: { acquireCount: { r: 2553, w: 11828711, W: 1 } }, MMAPV1Journal: { acquireCount: { w: 11828398 }, acquireWaitCount: { w: 45575 }, timeAcquiringMicros: { w: 443975376 } }, Database: { acquireCount: { r: 2553, w: 11828711 } }, Collection: { acquireCount: { R: 2553, W: 11828711 } } } 219ms
2015-05-26T08:35:41.845+0200 E NETWORK [conn22374] Uncaught std::exception: boost::filesystem::status: Permission denied: "/home/mongodb/ssd_buffer/ssd_buffer.ns", terminating
2015-05-26T08:35:42.023+0200 I CONTROL [conn22374] dbexit: rc: 100
2015-05-26T08:39:25.565+0200 I CONTROL ***** SERVER RESTARTED *****
2015-05-26T08:39:26.027+0200 W - [initandlisten] Detected unclean shutdown - /home/mongodb/mongod.lock is not empty.
2015-05-26T08:39:26.040+0200 I JOURNAL [initandlisten] journal dir=/home/mongodb/journal
2015-05-26T08:39:26.040+0200 I JOURNAL [initandlisten] recover begin
2015-05-26T08:39:26.040+0200 I JOURNAL [initandlisten] recover lsn: 396165925
2015-05-26T08:39:26.040+0200 I JOURNAL [initandlisten] recover /home/mongodb/journal/j._339
2015-05-26T08:39:26.711+0200 I JOURNAL [initandlisten] recover skipping application of section seq:394860057 < lsn:396165925
2015-05-26T08:39:31.379+0200 I JOURNAL [initandlisten] recover skipping application of section seq:394919427 < lsn:396165925
2015-05-26T08:39:32.203+0200 I JOURNAL [initandlisten] recover skipping application of section seq:394978827 < lsn:396165925
2015-05-26T08:39:33.158+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395038299 < lsn:396165925
2015-05-26T08:39:33.996+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395097698 < lsn:396165925
2015-05-26T08:40:26.799+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395157099 < lsn:396165925
2015-05-26T08:40:27.683+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395216461 < lsn:396165925
2015-05-26T08:40:28.595+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395275842 < lsn:396165925
2015-05-26T08:40:29.475+0200 I JOURNAL [initandlisten] recover skipping application of section seq:395335285 < lsn:396165925
2015-05-26T08:40:30.052+0200 I JOURNAL [initandlisten] recover skipping application of section more...
2015-05-26T08:40:33.456+0200 I JOURNAL [initandlisten] recover /home/mongodb/journal/j._340
2015-05-26T08:40:37.904+0200 I JOURNAL [initandlisten] recover cleaning up
2015-05-26T08:40:37.904+0200 I JOURNAL [initandlisten] removeJournalFiles
2015-05-26T08:40:38.142+0200 I JOURNAL [initandlisten] recover done
2015-05-26T08:40:38.142+0200 I STORAGE [DataFileSync] flushing mmaps took 12102ms for 0 files
2015-05-26T08:40:38.163+0200 I JOURNAL [durability] Durability thread started
2015-05-26T08:40:38.163+0200 I CONTROL [initandlisten] MongoDB starting : pid=23958 port=27017 dbpath=/home/mongodb 64-bit host=xxxxxxxxx
2015-05-26T08:40:38.163+0200 I JOURNAL [journal writer] Journal writer thread started
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] db version v3.0.2
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] git version: 6201872043ecbbc0a4cc169b5482dcf385fc464f
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] OpenSSL version: OpenSSL 1.0.1e 11 Feb 2013
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] build info: Linux ip-10-171-120-232 3.2.0-4-amd64 #1 SMP Debian 3.2.46-1 x86_64 BOOST_LIB_VERSION=1_49
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] allocator: tcmalloc
2015-05-26T08:40:38.164+0200 I CONTROL [initandlisten] options: { config: "/etc/mongod.conf", net: { bindIp: "127.0.0.1" }, storage: { dbPath: "/home/mongodb", directoryPerDB: true }, systemLog: { destination: "file", logAppend: true, path: "/home/mongodb/mongod.log" } }
2015-05-26T08:40:39.991+0200 I NETWORK [initandlisten] waiting for connections on port 27017
2015-05-26T08:40:40.234+0200 I NETWORK [initandlisten] connection accepted from 127.0.0.1:54012 #1 (1 connection now open)
First lines, you see the last updates before the crash occured.
Obviously, crash occured at :
2015-05-26T08:35:41.845+0200 E NETWORK [conn22374] Uncaught std::exception: boost::filesystem::status: Permission denied: "/home/mongodb/ssd_buffer/ssd_buffer.ns", terminating
Server restarts after unclean shutdown, so the journal recovers.
Apparently, everything runs smoothly.
Except that when we connect to our mongo client, the data in two of our databases are back to their state of 3 days ago (before all of our processing over the week-end). The two databases in question are the ones that were mostly written to over the week-end.
We check the files written on disk, they seem to be up to date (some of the files were updated just before the crash happened).
But the data is definitely 3 days old in the client.
Obviously, we tried repairDatabase and validate. Both ran ok, but the data was still the same (e.g. old data).
Of course, replication may have prevented that, but it seems rather alarming that, even with journaling enabled, we've lost this much data.
Has anyone encountered something similar ?
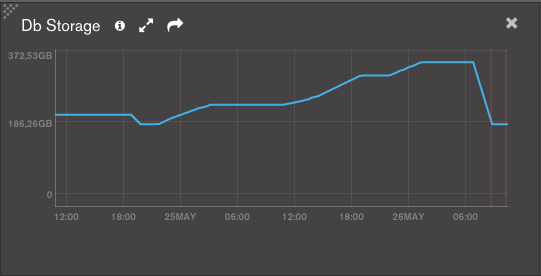
PS : You can see in the screenshot attached that the storage size increased over the week-end before completely dropping when mongod crashed.
PS 2 : Note that this is the second time it occurs in a week, but the first time was even worse... we got back data a few months old instead.