-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
Affects Version/s: 3.0.1, 3.0.4
-
Component/s: Text Search, WiredTiger
-
None
-
Fully Compatible
-
ALL
-
Quint Iteration 5
-
None
-
None
-
None
-
None
-
None
-
None
-
None
ISSUE SUMMARY
Long-running queries in MongoDB periodically yield their locks. As part of the yield-preparation procedure, intermediate results buffered in memory by the storage engine may need to be processed in order to ensure that there are no references into the storage layer that may become invalid when locks are relinquished.
A bug in this procedure may make $text and geoNear (i.e. $near or $nearSphere) long-running queries, which buffer intermediate query results, execute slowly. In particular, if a such a query yields y times and buffers d documents, the overall time spent in yield-preparation was O(yd). With the fix, the time complexity is reduced to O(y).
This issue only appears when queries are performed against a mongod instance running with the WiredTiger storage engine. Instances running the MMAPv1 storage engine are not affected.
USER IMPACT
On MongoDB systems using the WiredTiger storage engine, queries using $text or geoNear (i.e. $near or $nearSphere) may perform poorly. The performance impact is most severe for "large" $text or geoNear queries, i.e. queries that return a lot of results or require examining a large number of index keys or documents.
AFFECTED VERSIONS
MongoDB 3.0.0 through 3.0.4 running with the WiredTiger storage engine.
FIX VERSION
The fix is included in the 3.0.5 production release.
Original description
Created db with 5M docs full-text indexed as follows:
words = [
" when", " in", " the", " course", " of", " human", " events", " it", " becomes", " necessary",
" four", " score", " and", " seven", " years", " ago",
" ask", " not", " what", " your", " country", " can", " do", " for", " you",
" that's", " one", " small", " step", " for", " a", " man",
]
function sentence() {
l = Math.random() * 20
s = " "
for (var i=0; i<l; i++) {
w = Math.floor(Math.random() * words.length)
s = s + words[w]
}
return s
}
function init() {
db.c.drop()
db.c.createIndex({x: "text"})
}
function create() {
count = 5000000
every = 10000
for (var i=0; i<count; ) {
var bulk = db.c.initializeUnorderedBulkOp();
for (var j=0; j<every; j++, i++)
bulk.insert({x:sentence()})
bulk.execute();
print(i)
}
}
Then do a full-text search:
db.c.find({$text: {$search: "necessary"}}).itcount()
Finishes in about 10 seconds under mmapv1, ran for a several minutes without finishing under WT before I killed it. It also uses (possibly a lot) more memory under WT than mmapv1.
It seems to be spending all its time in forceFetchAllLocs (itself, not callees), called from yield. This path is only exercised if storage engine has document-level locking, which explains why WT behaves differently than mmapv1.
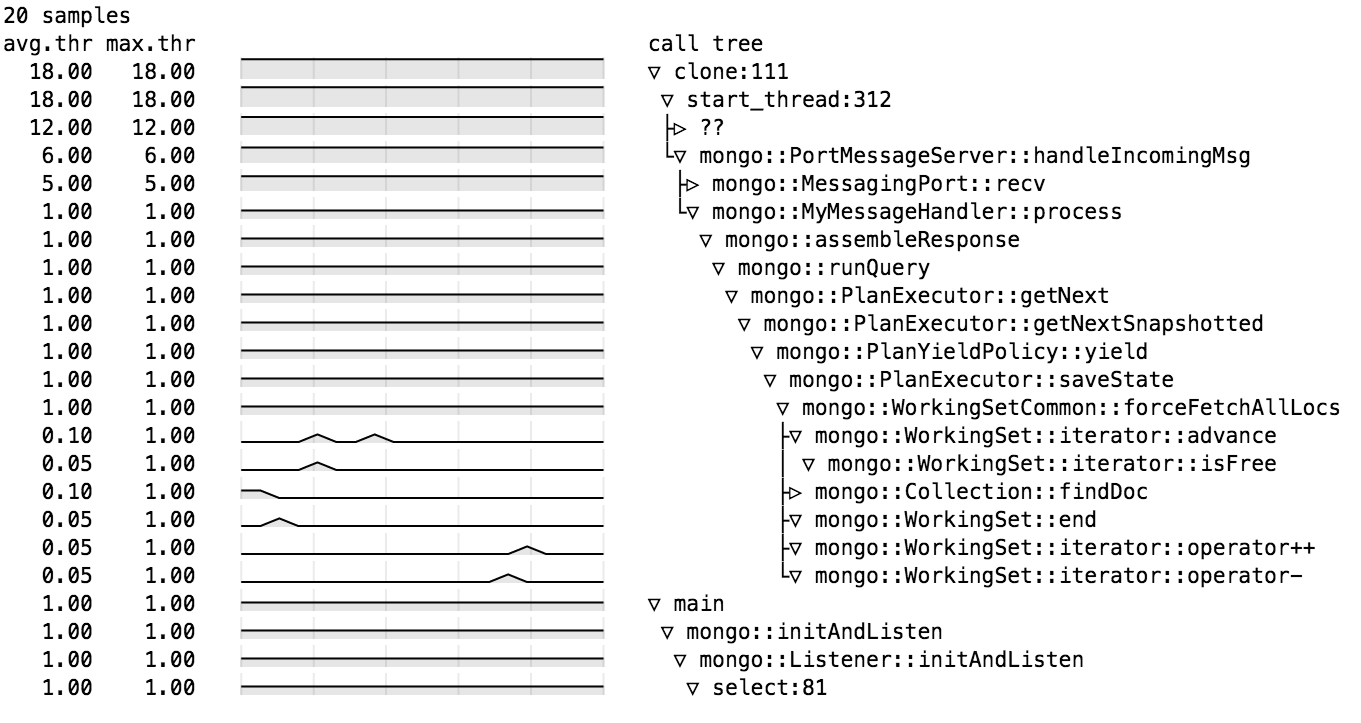
- is related to
-
SERVER-18961 Avoid iterating the entire working set on every yield
-
- Closed
-
- related to
-
-
- Closed
-
-
-

- Closed
-