-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: WiredTiger
-
None
-
Fully Compatible
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
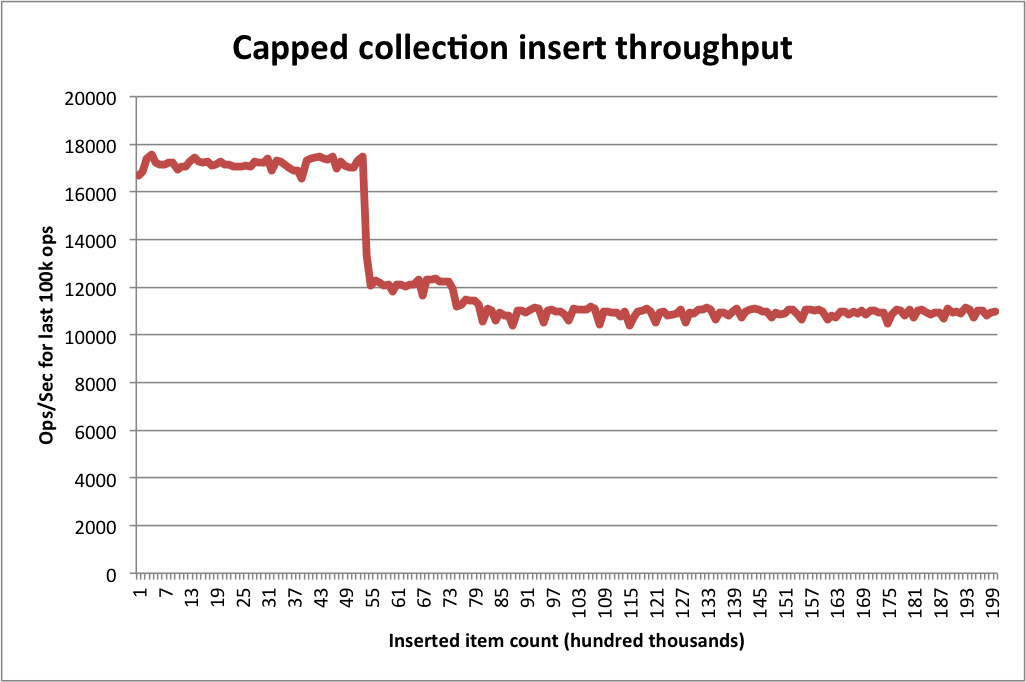
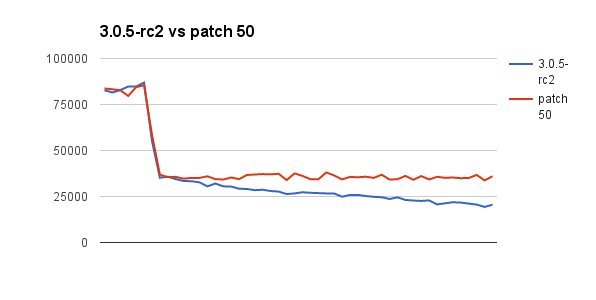
Capped collection insert rate begins to decline steadily once it is full and deletions start. Restarting mongod (without disturbing the collection) restores inserts to the original rate, but insert rate then begins to decline to a fraction of the initial rate:
20486 mb, 72577 ins/s 20489 mb, 63780 ins/s 20494 mb, 61213 ins/s 20495 mb, 55644 ins/s 20491 mb, 50556 ins/s 20494 mb, 46906 ins/s 20493 mb, 39926 ins/s 20496 mb, 36380 ins/s 20496 mb, 34873 ins/s 20496 mb, 43359 ins/s 20492 mb, 36704 ins/s 20491 mb, 25022 ins/s 20493 mb, 26334 ins/s 20494 mb, 27420 ins/s 20496 mb, 26594 ins/s 20493 mb, 25970 ins/s 20496 mb, 27202 ins/s 20496 mb, 25868 ins/s 20492 mb, 26571 ins/s 20491 mb, 26460 ins/s 20496 mb, 26840 ins/s 20496 mb, 26273 ins/s 20491 mb, 25883 ins/s 20496 mb, 25342 ins/s 20491 mb, 25477 ins/s 20496 mb, 24753 ins/s 20496 mb, 24196 ins/s 20492 mb, 24092 ins/s 20491 mb, 23656 ins/s 20496 mb, 23656 ins/s 20495 mb, 23213 ins/s 20496 mb, 22776 ins/s 20496 mb, 23280 ins/s 20495 mb, 22710 ins/s 20496 mb, 22352 ins/s 20492 mb, 22554 ins/s
Seems to be worse with larger documents and with larger collections:
doc size cap initial final final/ rate rate initial 200 2GB 194 160 82% 1000 10GB 140 84 60% 1000 20GB 140 63 45% 2000 20GB 115 50 43% 4000 20GB 83 23 27%
Stack trace excepts showing involvement of WT delete (complete stack traces attached as capped-delete.html):


- is depended on by
-
-
- Closed
-
-
SERVER-19744 WiredTiger changes for MongoDB 3.0.6
-
- Closed
-
- is related to
-
-
- Closed
-