-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: None
-
Component/s: Admin
-
None
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
I have one MongoDB Cluster (using ReplicaSet) with:
1 Mongo Primary (3.0.5 - 100GB OPLOG)
1 Mongo Secondary (3.0.5 - 100GB OPLOG)
1 Mongo Arbiter (3.0.5 - no journal)
All servers hosted on Ubuntu 14.04 (Trusty).
This cluster is used for reading and heavy written (many per second, after all is a datasource). Every write uses REPLICA_ACKNOWLEDGED WriteConcern (w = 2) (to prevent desynchronization).
Today, at 11AM my primary node failed and I'm not seeing no reason to this...
Here is the event log (with 2 operations beyond the error, one before and (even after abort) one after) (archive first.log - text is too long).
After that, my re-initialization script get mongo node only again, and some operations took place smoothly, until this error (archive second.log - text is too long).
After that, all subsequent startup attempts failed with the following error (archive third.log - text is too long).
After these failures, I tried to start mongo with --repair parameter, but it gave me WT_PANIC too.
After that, I upgrade my mongo node to 3.0.7 and start --repair again (which is running so far).
I know you (jira contributors) don't have nothing with this, but this error appears to me for the second time(WT_PANIC: WiredTiger library panic). First you said this problem was solved in a custom branch (created with my previous issue) and then attached to the next version.
It's hard to trust in mongo for production environments after these errors...
Can someone help me find the possible cause of these errors mentioned above? I really need to know the cause and ways to avoid them...
Obs.:
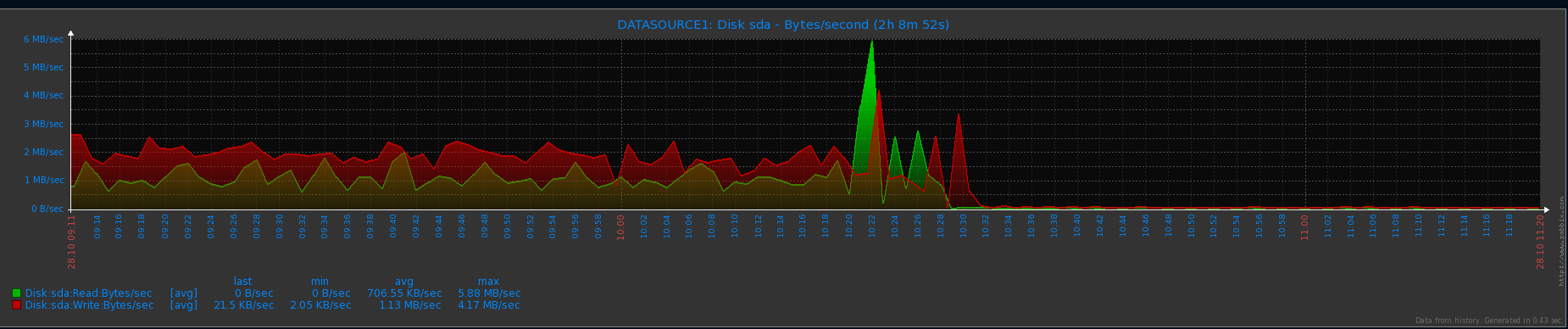
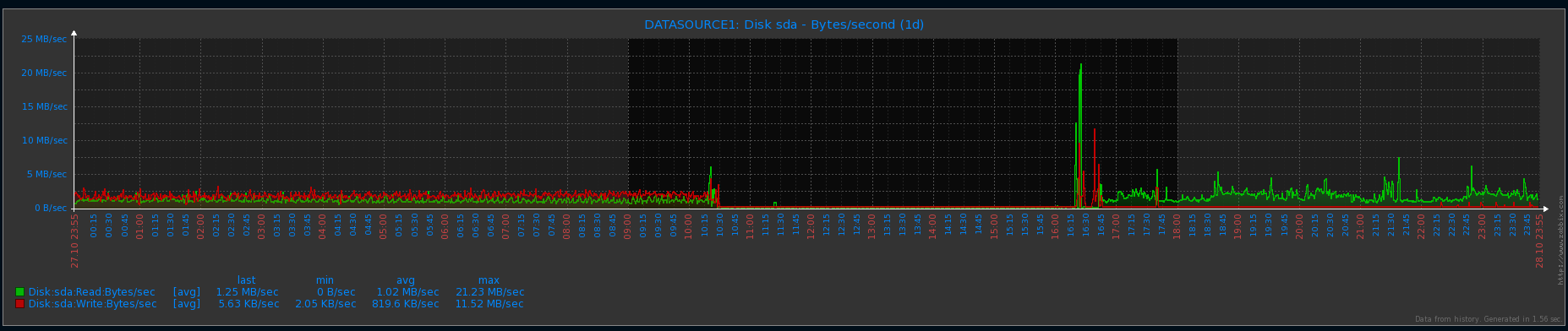
I attach some pictures of server disk usage. The picture with name 1.png is from the time of first occurrence. The picture with name 2.png is from all day window (my node is repairing since 4PM).