-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
Affects Version/s: 3.2.5, 3.2.6
-
Component/s: WiredTiger
-
Fully Compatible
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
- Linux, standalone, 3.2.6, 4 GB cache
- data files on hdd, journal on ssd
- single thread inserting 330 kB documents with j:true:
x = '' while (x.length < 330000) { x += 'x' } doc = {x: x} for (var i=0; ; i++) { db.c.insert(doc, {writeConcern: {j: true}}) if (i%1000==0) print(i) }
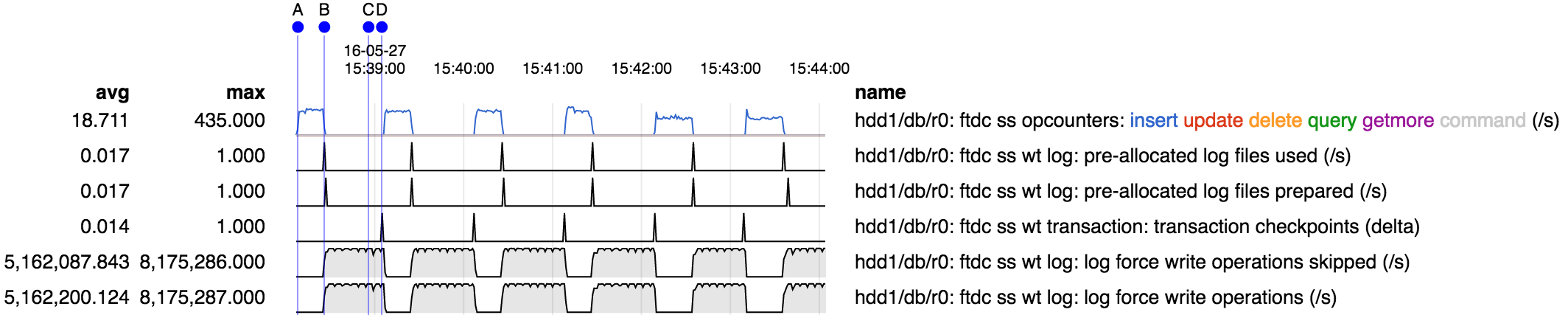
- B: inserts stall coinciding with bump in "log files used" and "log files prepared"
- D: inserts resume on next checkpoint
- during stall "log force write operations" and "log force write operations skipped" are very high (8 M/s)
Following stack, captured at C above, seems to be typical of stalled operations:
=== 2016-05-27T15:38:58.138733+0000 Thread 2 (Thread 0x7fc44266a700 (LWP 16635)): #0 0x00000000019f3508 in __wt_log_wrlsn () #1 0x0000000001a1d9aa in __wt_log_flush_lsn () #2 0x0000000001a1e6ef in __wt_log_flush () #3 0x0000000001a63f28 in __session_log_flush () #4 0x000000000107e3da in mongo::WiredTigerSessionCache::waitUntilDurable(bool) () #5 0x000000000107b0aa in mongo::WiredTigerRecoveryUnit::waitUntilDurable() () #6 0x000000000108d324 in mongo::waitForWriteConcern(mongo::OperationContext*, mongo::repl::OpTime const&, mongo::WriteConcernOptions const&, mongo::WriteConcernResult*) () #7 0x0000000000b64aad in mongo::WriteBatchExecutor::executeBatch(mongo::BatchedCommandRequest const&, mongo::BatchedCommandResponse*) () #8 0x0000000000b67b78 in mongo::WriteCmd::run(mongo::OperationContext*, std::string const&, mongo::BSONObj&, int, std::string&, mongo::BSONObjBuilder&) () #9 0x0000000000b81833 in mongo::Command::run(mongo::OperationContext*, mongo::rpc::RequestInterface const&, mongo::rpc::ReplyBuilderInterface*) () #10 0x0000000000b826a4 in mongo::Command::execCommand(mongo::OperationContext*, mongo::Command*, mongo::rpc::RequestInterface const&, mongo::rpc::ReplyBuilderInterface*) () #11 0x0000000000ad9a10 in mongo::runCommands(mongo::OperationContext*, mongo::rpc::RequestInterface const&, mongo::rpc::ReplyBuilderInterface*) () #12 0x0000000000c9b1e5 in mongo::assembleResponse(mongo::OperationContext*, mongo::Message&, mongo::DbResponse&, mongo::HostAndPort const&) () #13 0x0000000000961cdc in mongo::MyMessageHandler::process(mongo::Message&, mongo::AbstractMessagingPort*) () #14 0x00000000012b51ad in mongo::PortMessageServer::handleIncomingMsg(void*) () #15 0x00007fc44191b6aa in start_thread (arg=0x7fc44266a700) at pthread_create.c:333 #16 0x00007fc441650e9d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:109
Attaching diagnostic.data and stack traces (with timestamps) captured every 5 seconds during run.
Note: above repro was with the journal on SSD, so it reached the point where the "log files used" and "log files prepared" counters were bumped fairly quickly, before the next checkpoint. With journal on HDD, the problem still reproduces, but more the operation rate is much slower, so it takes much longer (several checkpoints) to reach the point where "log files used" and "log files prepared" bump, at which point operations stall until the next checkpoint.
{kind=link}