-
Type:
Bug
-
Resolution: Done
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: 3.2.9
-
Component/s: Concurrency, WiredTiger
-
None
-
Environment:We are running on Debian 7
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
We have upgraded a production replica set from 3.0.12 to 3.2.9, secondary members first, leaving the two last members (primary and its datacenter active fallback) to the end of the process.
The other day we've changed priorities between the afore mentioned two remaining 3.0.12 members, upgraded one to 3.2.9 and then set it back as a primary node, leaving us with one secondary member left as 3.0.12
Once that newly upgraded 3.2.9 host (172.16.144.3) became primary again (after DB restart, to have the new binaries apply),
Application using this replica set had their performance and response times were deteriorating rapidly.
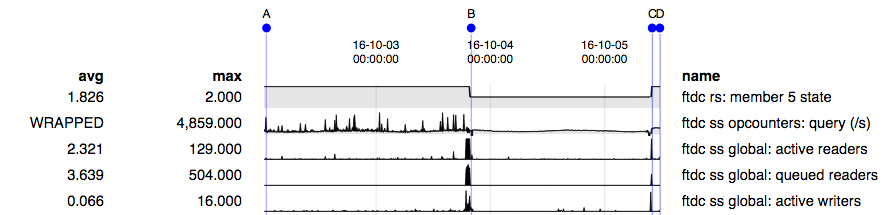
Node log file was showing "cursorExhausted:1" for almost every query logged,
which wasn't occurring in any of the other members.
When examined server status for cursor metrics, number of timed out cursors was rising gradually while number of pinned cursors was around 100 and number of no timeout cursors was around 70.
One thing that was changed apart from upgrading this primary node to 3.2.9 was to explicitly set its maximum configured WT cache size to 36Gb (based on the new 3.2 wiredTiger rule of thumb saying it's 60% of free physical RAM minus one Gb)
We suspected that the fact that the recently upgraded 3.2.9 node was just restarted, thus having its cache empty - being completely "cold" when massive application traffic started performing reads and writes, was the root cause for these cursor exhaustion and performance drop - so we shortly after fallen back to the left 3.0.12 secondary (172.16.23.3) to become primary - which has resulted an immediate significant performance improvement and a stop to cursor exhaustion.
Please note that on the 3.0.12 we had no explicit configuration of cacheSizeGB but left it to the default behaviour of wiredTiger 3.2.9.
After primary was set on the last remaining 3.0.12, we decided to have leave the 3.2.9 node which failed to take the load as primary (172.16.144.3) to "pre heat" its cache for on query traffic (about 600 read statements per second) and gave it another go as primary the day after (without restarting it, as it was already set on version 3.2.9 - yet the same behaviour of cursor exhaustion and massive app performance drop occurred again forcing yet another fallback to the 3.0.12 node to become primary again - which again mitigated things back to what they were before the change.
Enclosed please find are log files from both the 3.2.9 and 3.0.12 nodes, notice how same queries generate different outcomes in terms of cursor exhaustion even though they share the same execution plans, one extremely popular query is the one issuing find on lists.items-Posts in its different permutations:
329_member.log.tar.gz: for host 172.16.144.3, I've omitted the biggest log (1.5G - which covered Sep 29 09:30 to 12:43) as other logs also contain the symptoms reported here.
3012_member.log.tar.gz: for host 172.16.23.3
329_member_server_status.out
3012_member_server_status.out
We have other applications based on other replica sets which are fully upgraded to 3.2.9 (including primary of course) which doesn't display this behaviour - so this could very much have to do with the way the application driver is setup or simply on how its written (or a mix of both...)
Kindly try and assist in analysing how come this behaviour occurs and recommend of methods to try and overcome it.
This is quite urgent for us as we wish to have it completed by the end of next week.
Many thanks in advance,
Avi K, DBA
WiX.COM
- is related to
-
SERVER-27132 Mongo response time increased in 15-20% after upgrade to 3.2.10
-

- Closed
-