We have updated one of our sharded cluster from v3.0.12 to v3.2.10. Since then our cluster was not operational because many operations got blocked by the the router. The corresponding log message looks like this:
2016-10-20T11:00:22.902+0200 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-3-0] Failed to connect to s559:27017 - ExceededTimeLimit: Operation timed out 2016-10-20T11:00:22.918+0200 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-3-0] Failed to connect to mongo-007.ipx:27017 - ExceededTimeLimit: Operation timed out 2016-10-20T11:00:22.920+0200 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-3-0] Failed to connect to mongo-024.ipx:27017 - ExceededTimeLimit: Operation timed out 2016-10-20T11:00:22.921+0200 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-3-0] Failed to connect to mongo-007.ipx:27017 - ExceededTimeLimit: Operation timed out 2016-10-20T11:00:22.921+0200 I ASIO [NetworkInterfaceASIO-TaskExecutorPool-3-0] Failed to connect to mongo-024.ipx:27017 - ExceededTimeLimit: Operation timed out
We can reproduce the issue at any time just by executing a findOne through the router several times:
for(x=0;x<1000;x++){db.offer.find({"_id" : NumberLong("5672494983")}).forEach(function(u){printjson(u)});print(x)}
It blocks after a few findOne's already.
If we execute the same code on the shard where the document is located then there is no blocking at all.
We found out that mongodb router v3.0.12 doesn't have this problem. This is why we downgraded all our routers to v3.0.12 even though the rest of the cluster (mongod's) is running v3.2.10.
Please see attached the log file from the router.
Please see also 3 monitoring screenshots of the router TCP-sockets. As you can see, tcp_tw (tcp_timeWait) is much higher for v3.2.10 than for v3.0.12.
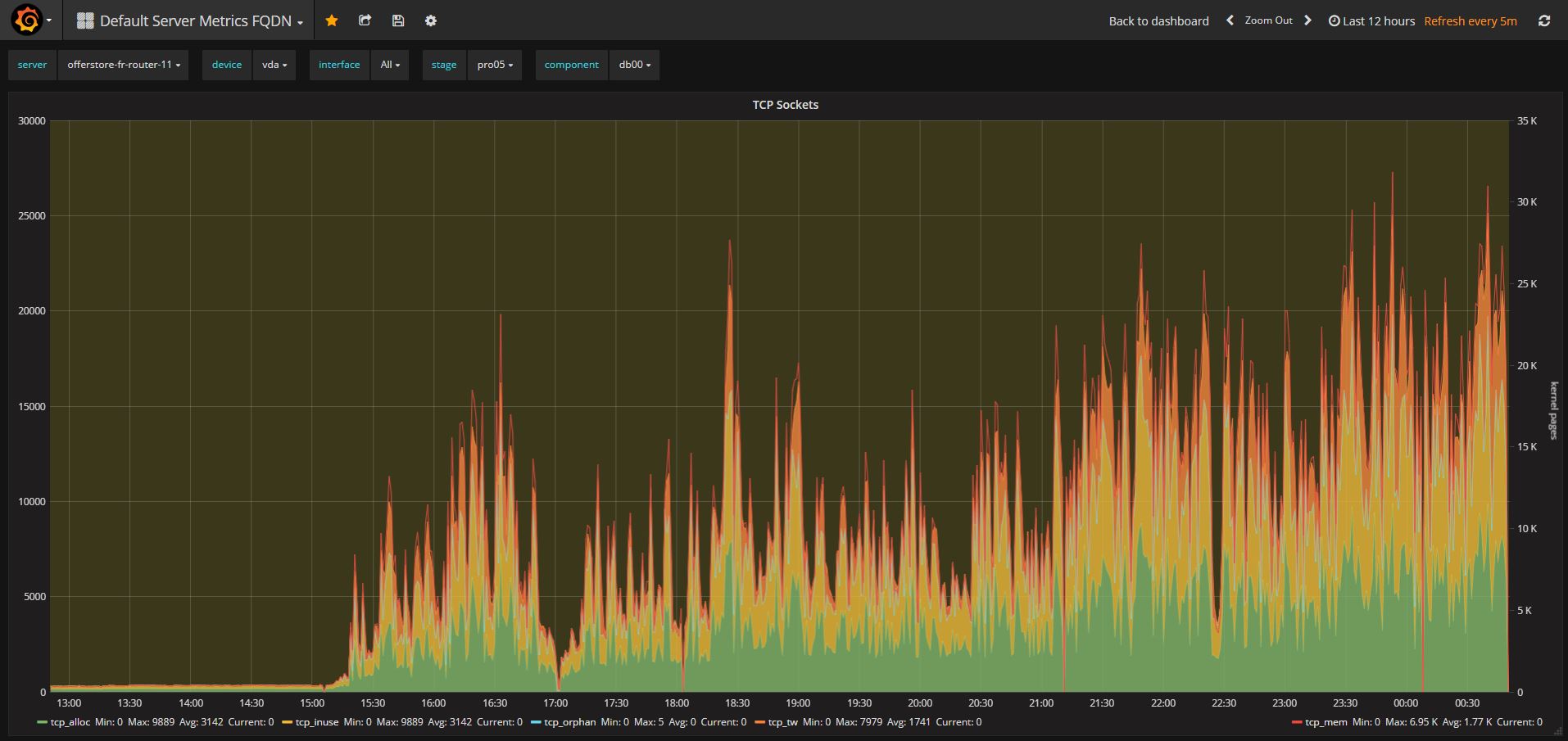
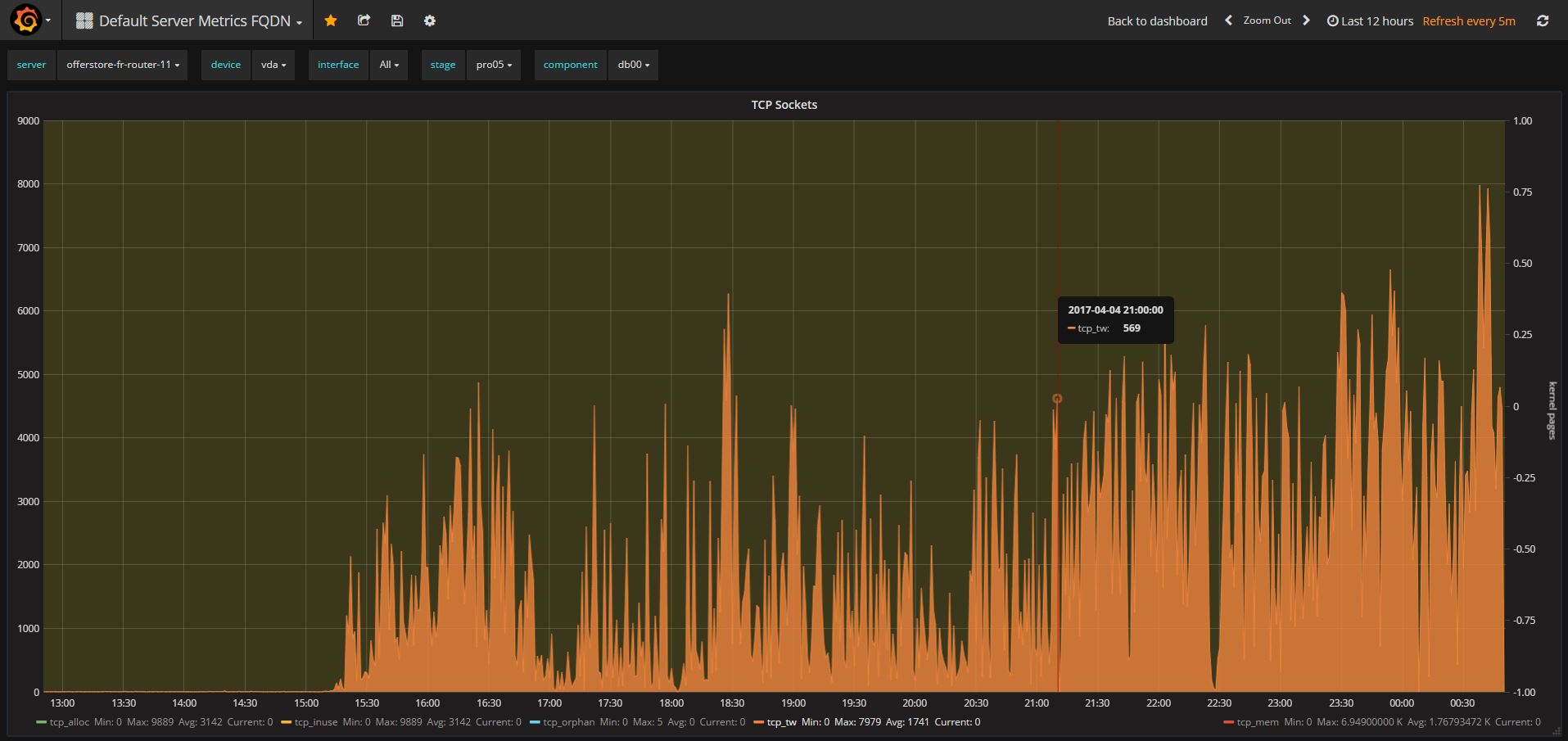

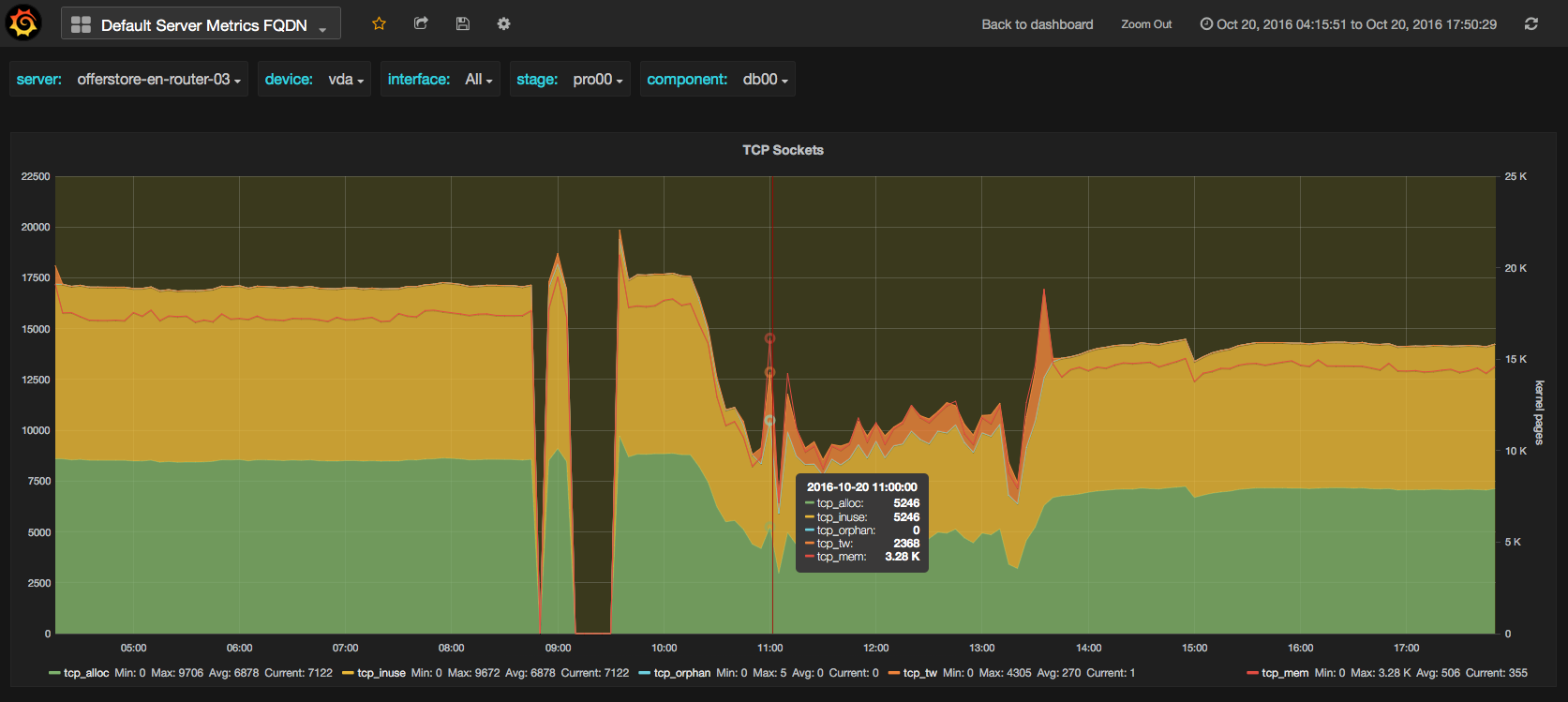

- duplicates
-
SERVER-27232 Refresh and Setup timeouts in the ASIO connpool can prematurely time out an operation
-

- Closed
-
- is related to
-
-
- Closed
-
-
-
- Closed
-