-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.4.3, 3.4.4
-
Component/s: Replication
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Hello,
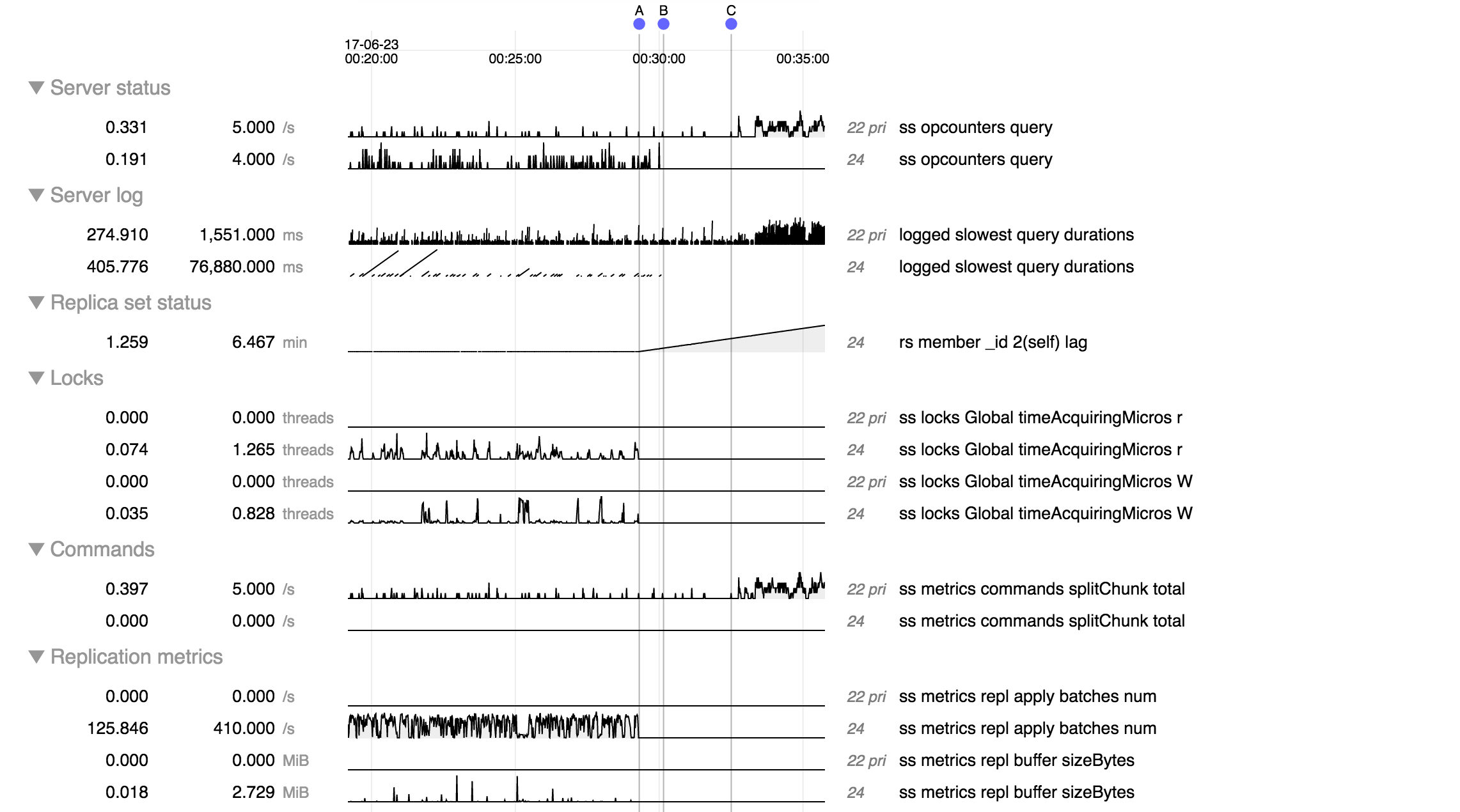
Since we upgraded our cluster from 3.2.8 to 3.4.3, regularly secondary members of our most loaded shard stopping syncing to primary. When that happens, the field "oplog last event time" returned by command rs.printReplicationInfo() stays indefinitely blocked. The secondary member just fall behind and we need to restart it in order to free the oplog, allowing to catch up the primary member.
When it happens, just before the service shutdown, in logs we can see this error :
2017-06-11T05:13:46.410+0200 I REPL [replication-7923] Error returned from oplog query while canceling query: ExceededTimeLimit: Remote command timed out while waiting to get a connection from the pool, took 39149258ms, timeout was set to 65000ms 2017-06-11T05:13:46.411+0200 I REPL [rsBackgroundSync] Replication producer stopped after oplog fetcher finished returning a batch from our sync source. Abandoning this batch of oplog entries and re-evaluating our sync source.
The "took 39149258ms, timeout was set to 65000ms" is strange, seems that the oplog query was longer that the timeout. The shard on witch it happens receives huge amount of read and writes so it's not shocking for us to see a oplog query to fail. But the secondary should be able to retry it.
And sometimes when the oplog is blocked and we restarting the concerned member, it produces theses messages in logs :
2017-06-25T17:35:32.914+0200 I CONTROL [signalProcessingThread] got signal 15 (Terminated), will terminate after current cmd ends 2017-06-25T17:35:32.914+0200 I NETWORK [signalProcessingThread] shutdown: going to close listening sockets... 2017-06-25T17:35:32.914+0200 I NETWORK [signalProcessingThread] closing listening socket: 7 2017-06-25T17:35:32.915+0200 I NETWORK [signalProcessingThread] shutdown: going to flush diaglog... 2017-06-25T17:35:32.915+0200 I REPL [signalProcessingThread] shutting down replication subsystems 2017-06-25T17:35:32.916+0200 I REPL [signalProcessingThread] Stopping replication reporter thread 2017-06-25T17:35:57.051+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.30:27025 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.052+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.3:27025 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.052+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.28:27025 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.052+0200 W NETWORK [ReplicaSetMonitor-TaskExecutor-0] No primary detected for set csReplSet 2017-06-25T17:35:57.052+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] All nodes for set csReplSet are down. This has happened for 1 checks in a row. 2017-06-25T17:35:57.329+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.18:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.329+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.16:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.329+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.17:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.329+0200 W NETWORK [ReplicaSetMonitor-TaskExecutor-0] No primary detected for set sfx6 2017-06-25T17:35:57.329+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] All nodes for set sfx6 are down. This has happened for 1 checks in a row. 2017-06-25T17:35:57.839+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.30:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.839+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.29:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.839+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] Marking host 172.16.18.28:27017 as failed :: caused by :: Location17382: Can't use connection pool during shutdown 2017-06-25T17:35:57.839+0200 W NETWORK [ReplicaSetMonitor-TaskExecutor-0] No primary detected for set sfx10 2017-06-25T17:35:57.839+0200 I NETWORK [ReplicaSetMonitor-TaskExecutor-0] All nodes for set sfx10 are down. This has happened for 1 checks in a row. [...]
In that case only a "kill -9" let the member to shutdown.
Our Mongo cluster details :
- Many shards + config replica set, each formed by 3 members (1 primary + 2 secondary)
- 2 mongos
- Balancer is disabled
- Package version 3.4.4, OS: Debian 8 Jessie
- Servers: 6 cores Xeon CPU, 64GB RAM, ~3To SSD, ext4 file system
- ~ 40 collections in 1 DB
- Many writes and reads
Thank you in advance for your help.
Best regards,
Slawomir

- related to
-
SERVER-31368 Log time spent waiting for other shards in merge cursors aggregation stage
-
- Closed
-