-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: 3.4.0, 3.4.3, 3.4.4, 3.4.6
-
Component/s: Networking, Sharding
-
None
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
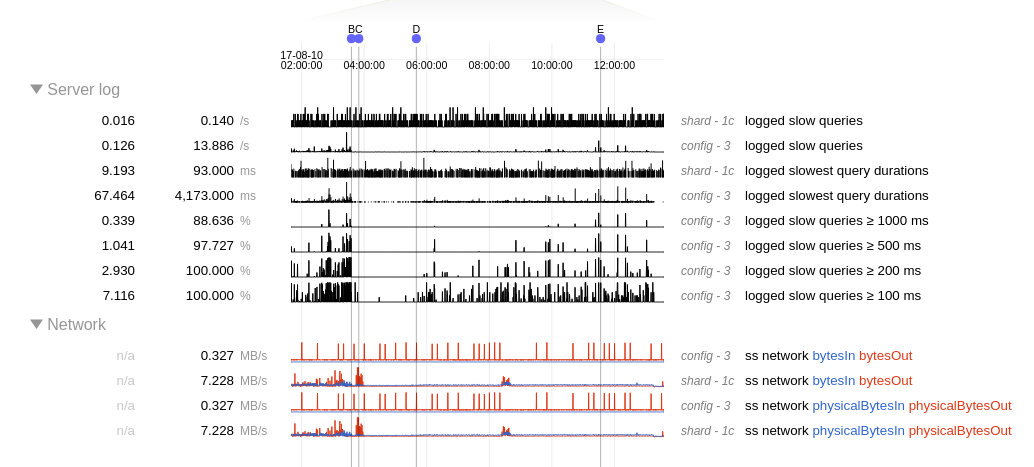
We had several issues in the past few days under our applications, and after further analysis, we found out that they are all related to our running instances of sharded MongoDB. During this examination, we noticed that our servers were reporting a lot of connection timeouts. After analyzing our network we discovered that it didn't have any performance issues. The tests results are provided along with this ticket in 'reportNetwork_mongo-20170811.txt' file.
Also, we found some links on the web of people having similar problems to this one that we're facing; this is a group of links that we found:
https://jira.mongodb.org/browse/SERVER-24711
https://stackoverflow.com/questions/38485285/mongodb-replica-heartbeat-request-time-exceeded
https://jira.mongodb.org/browse/SERVER-24058
https://github.com/rofl0r/proxychains-ng/issues/171
But even so, we think we are facing an undocumented problem here (maybe related to those others).
A description of the problem:
Some requests made to our sharded clusters give us a timeout message (found at the log from the DB) for no apparent reason or pattern that we could figure out. If we try to perform the same request right after the problematic one, it may works without any problems but sometimes It don't. We even implemented this retry at our application code to mitigate the problem, but since it takes much time to timeout and make the request again, our client experience some slowness due to this issue and making this retry isn't a satisfactory fix to the problem for us.
Currently, we have three different clusters running sharded MongoDB. One of them is operating at Softlayer’s(IBM) data center, and two others at OVH. We're going to focus our data provided in this ticket on the one from IBMs despite also having problems on the other two, just because we think that we're already providing a lot of data to you guys, but if needed we can provide data from the other two clusters.
The cluster is composed of (all logs will be relative to this cluster):
Servers hosted in IBM’s data center.
3 MongoDB(3.4.4) Servers running in a VM with 32GB RAM and 8 cores.
3 MongoDB(3.4.4) Configs running in a VM with 2GB RAM and 2 cores.
8 nodes(3.4.4) with the replication factor of 3 Bare metal with 256GB RAM and 40 cores.
All of them communicate between each other using 1Gbps network.
We can say these issues aren't related to infrastructure problems at the DC, as the all of our clusters are having this issues, regardless of the infrastructure provider. Also, it is important to report that the cluster size is not a factor in this problem because we have a tiny cluster of only two servers and they are facing the same problems.
Our DBA also tried to fine tune some configurations and had no luck in fixing the problem. The tuned configurations were:
WiredTigerConcurrentReadOperations – from default to 256
WiredTigerConcurrentWriteOperations – from default to 256
ShardingTaskExecutorPoolHostTimeoutMS – from default to 7200000
ShardingTaskExecutorPoolMinSize – from default to 10
taskExecutorPoolSize – from default to 16 (twice the number of cores)
We also tried to change the max connection pool but with no success.
Our development team also tried different versions of the Java's mongo driver, also with no positive results. (currently using version 3.4.2)
com.mongodb.MongoExecutionTimeoutException: Operation timed out, request was RemoteCommand 254187776 -- target:mongo-shard-geral7a.foobar.com:7308 db:admin cmd:{ isMaster: 1 }
com.mongodb.MongoExecutionTimeoutException: Couldn't get a connection within the time limit
We also tried to upgrade and downgrade the MongoDB binary versions (3.4.6, 3.4.3, 3.4.0) none of them had any effects to solve our problem.
We have several individual replica-set deployments, and none of them faced this issue in the past three years.
The data provided with this ticket is:
All MongoDB Nodes (from the given cluster) logs and diagnostic.data files (past 3 days).
All MongoDB Servers (from the given cluster) logs (past 3 days).
All MongoDB Configs (from the given cluster) logs (past 3 days).
Network tests between a 'mongos', a config server and a primary node.
IP’s and DNS’ has been hidden or modified for security reasons.

- related to
-
-
- Closed
-