-
Type:
Improvement
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: Aggregation Framework, Querying
-
None
-
None
-
None
-
None
-
None
-
None
-
None
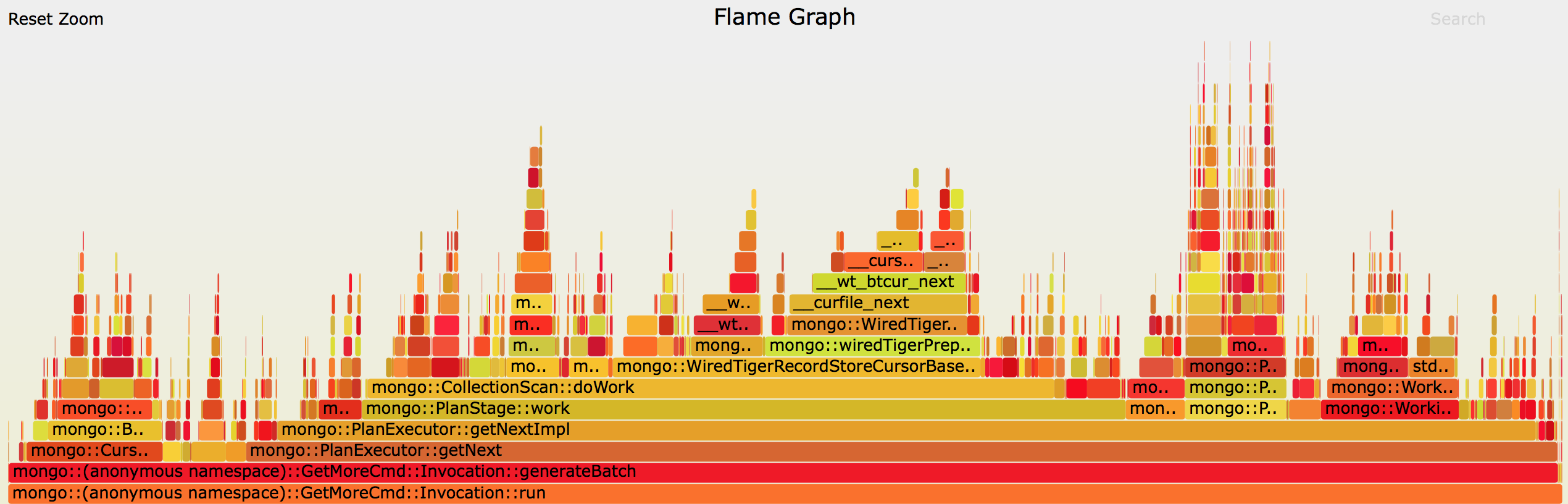
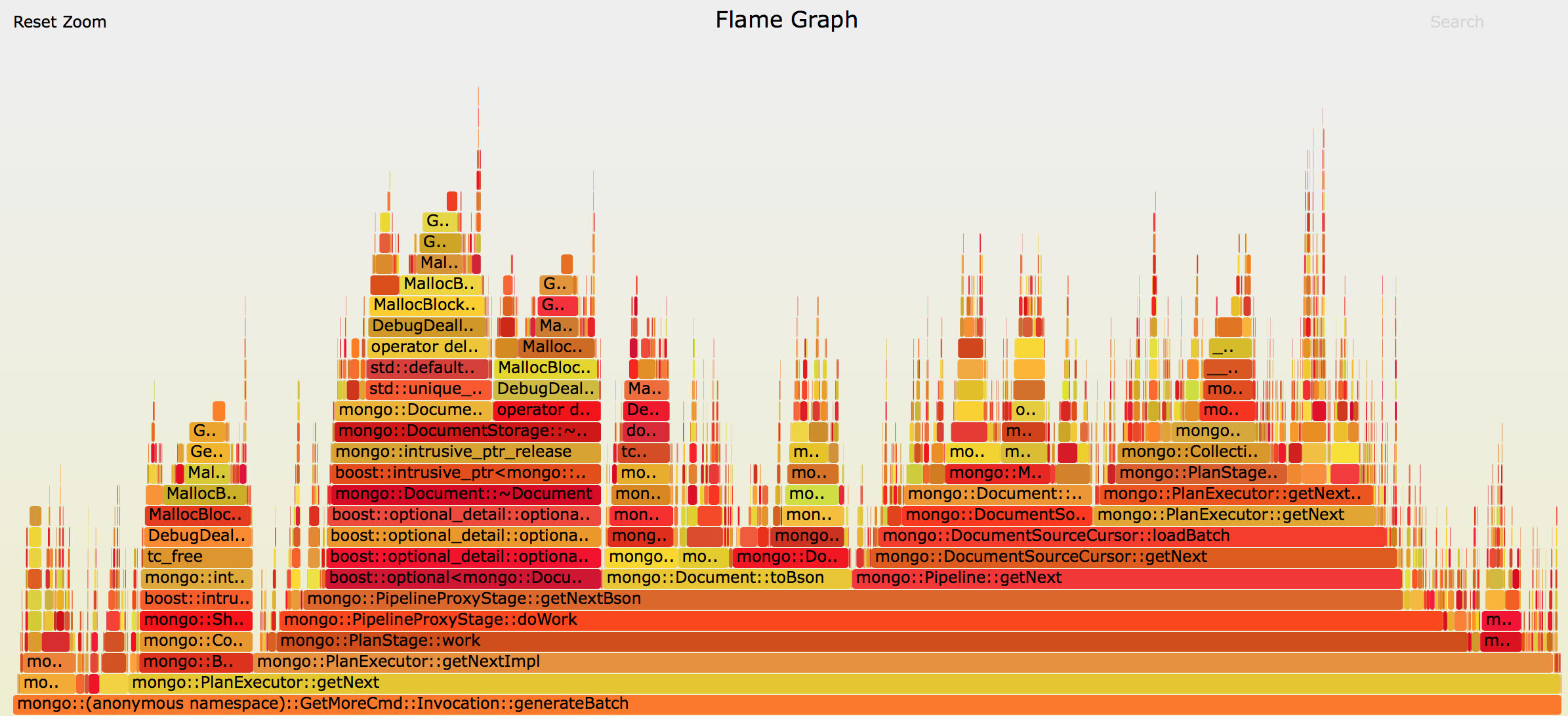
Please see the following python code, and the explanation that follows:
import random from pymongo import MongoClient c=MongoClient('127.0.0.1:27017') def randomword(n): s = "" for i in range(n): s += random.choice('abcdefghijklmnop') return s words = [randomword(10) for i in range(1000)] def bigdict(n): d = {} for i in range(n): d[random.choice(words)] = random.choice(words) return d def somedict(): d = bigdict(50) d['a'] = random.randint(1,100) d['b'] = [ { "val": random.randint(1,100) }, { "val": random.randint(1,100) } ] return d base_collection = c['test']['test'] base_collection_view= c['test']['view_test'] base_collection.drop() base_collection_view.drop() base_collection.insert_many([somedict() for i in range(100000)]) print('done inserting') c['test'].command({ "create": "view_test", "viewOn": "test", "pipeline": [ { '$project': { 'a': 1, 'b': 1 } } ] }) def benchmark_collection(col): # returns time in MS from datetime import datetime start = datetime.now() for i in range(20): res = list(col.find({'b.val': 15}, limit=1)) timedelta_ms = (datetime.now() - start).total_seconds() * 1000 return "%.2fms" % timedelta_ms print("base collection time: " + benchmark_collection(base_collection)) print("view collection time: " + benchmark_collection(base_collection_view)) print() print("base collection time: " + benchmark_collection(base_collection)) print("view collection time: " + benchmark_collection(base_collection_view))
Execution result on my machine
base collection time: 39.00ms view collection time: 3035.63ms base collection time: 49.86ms view collection time: 2970.37ms
The code above puts 100k documents in an empty collection. This collections assumed to have no indexes and nothing else special.
Then a view created on this collection, and the view's pipeline is to project only two of the many fields that documents in that collection have.
Then, both the view and the collection are queried and it is found out that the raw collection outperforms the view about 100x faster.
From my simple tests, I have also found out that:
Querying the collection for a b.val that is found (and having limit=1) is fast.
Querying the collection for a b.val that is not found isn't fast - it takes about 150ms.
**The above results are expected: there is no index on this field.
The unexpected results are for the view:
*Querying the *view__ for any b.val, existing or not, while also having limit=1, still takes about 150ms! It's as if the document was found in the view and the query continues instead of stopping.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
- duplicates
-
-
- Closed
-
-
-
- Closed
-
- related to
-
-
- Closed
-