-
Type:
Question
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: Performance
-
None
-
Server Triage
-
None
-
None
-
None
-
None
-
None
-
None
-
None
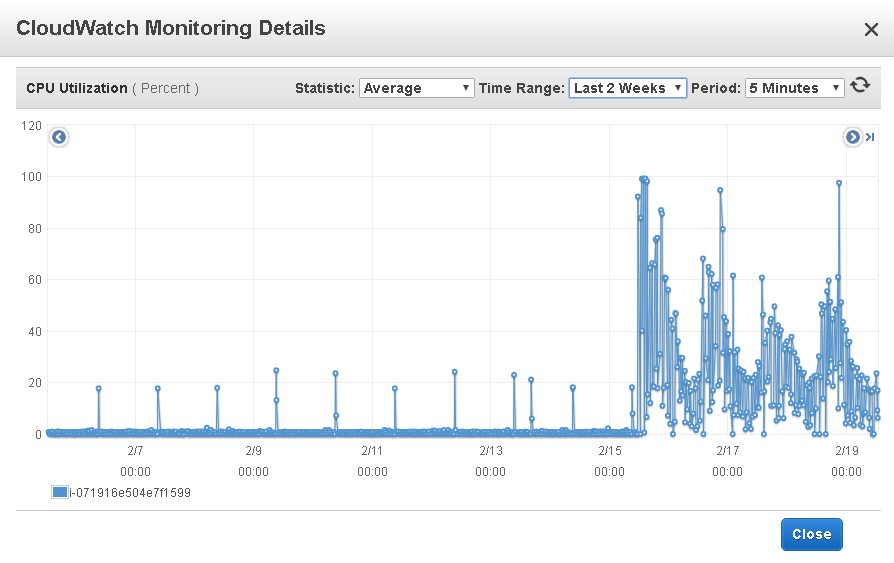
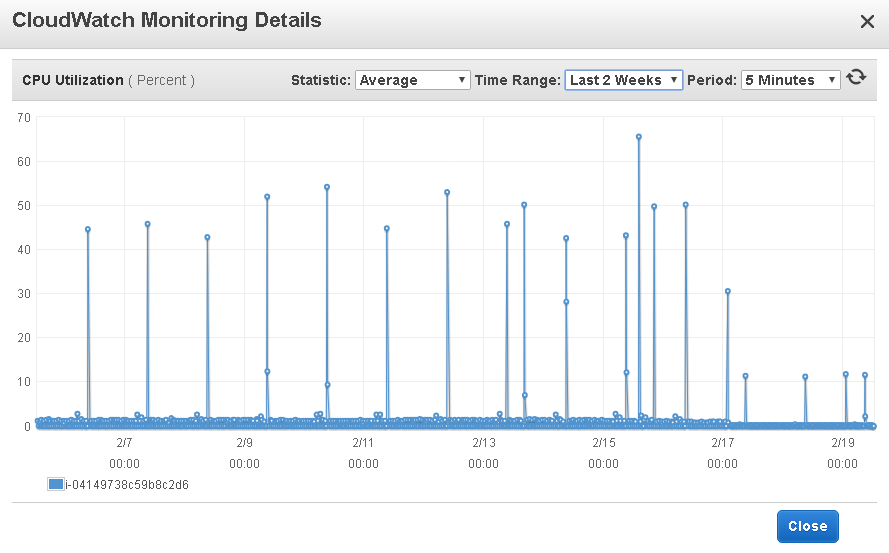
Out of nowhere the two secondary instances for a three node cluster with very little CPU usage spiked to 100% and remained high.
Version: 2.4.14
Things we did so far:
- Rebuilt all three databases from replicas.
- reIndex()
Things we discovered:
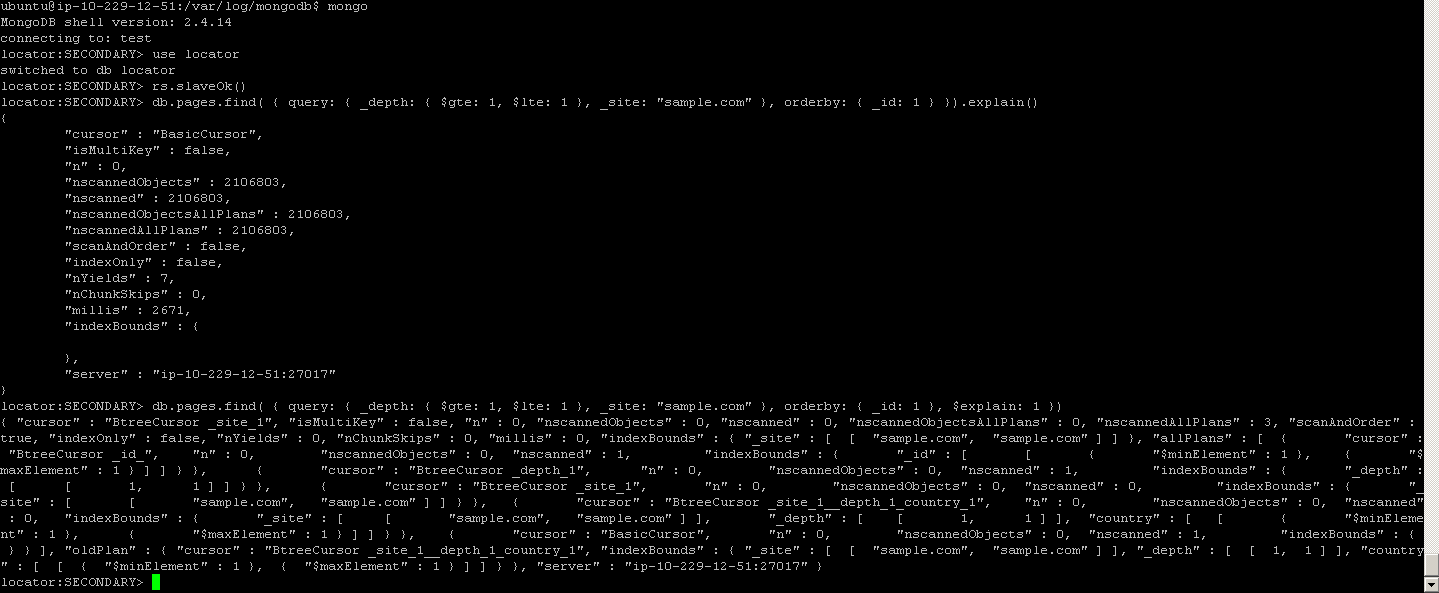
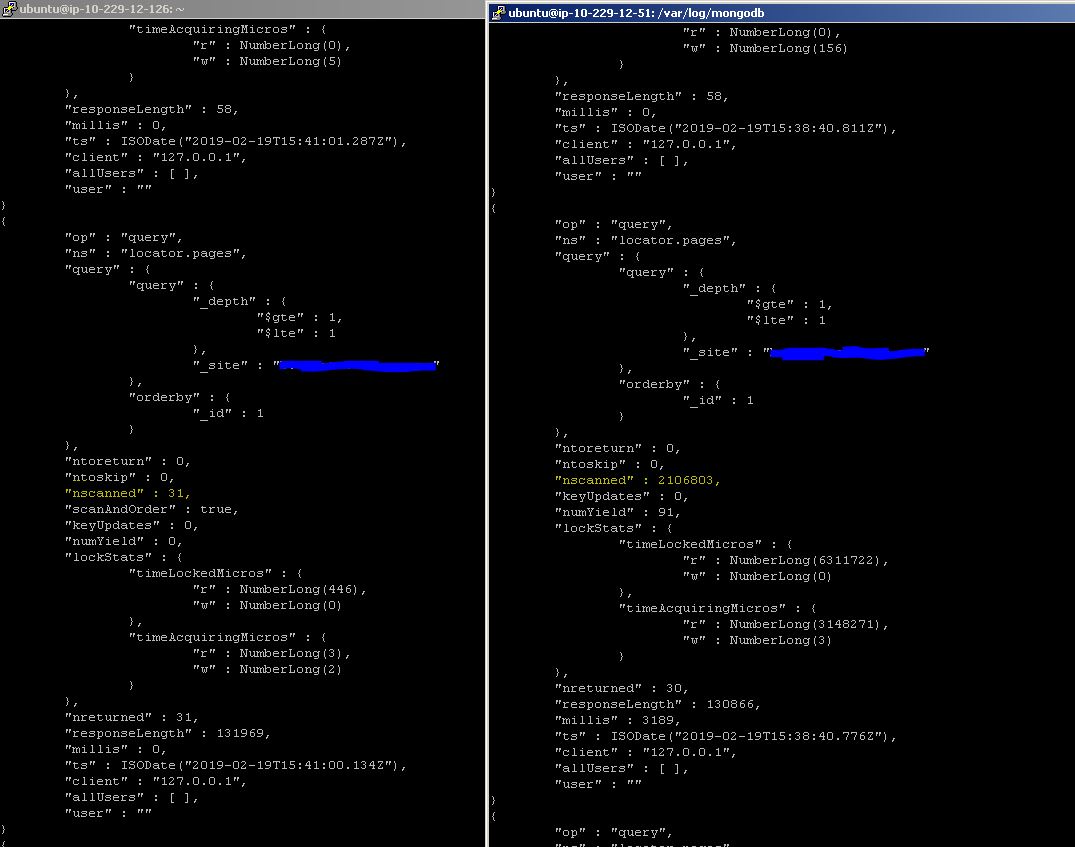
Now that the load is higher and avg response time is >100ms than usual we see some query that should be using index not using it.
Tue Feb 19 12:47:27.946 [conn11958] query locator.pages query: { query: { _depth:
{ $gte: 1, $lte: 1 }, _site: "sample.com" }, orderby: { _id: 1 } } ntoreturn:0 ntoskip:0 nscanned:2106803 keyUpdates:0 numYields: 11 locks(micros) r:5514254 nreturned:30 reslen:130866 2951ms
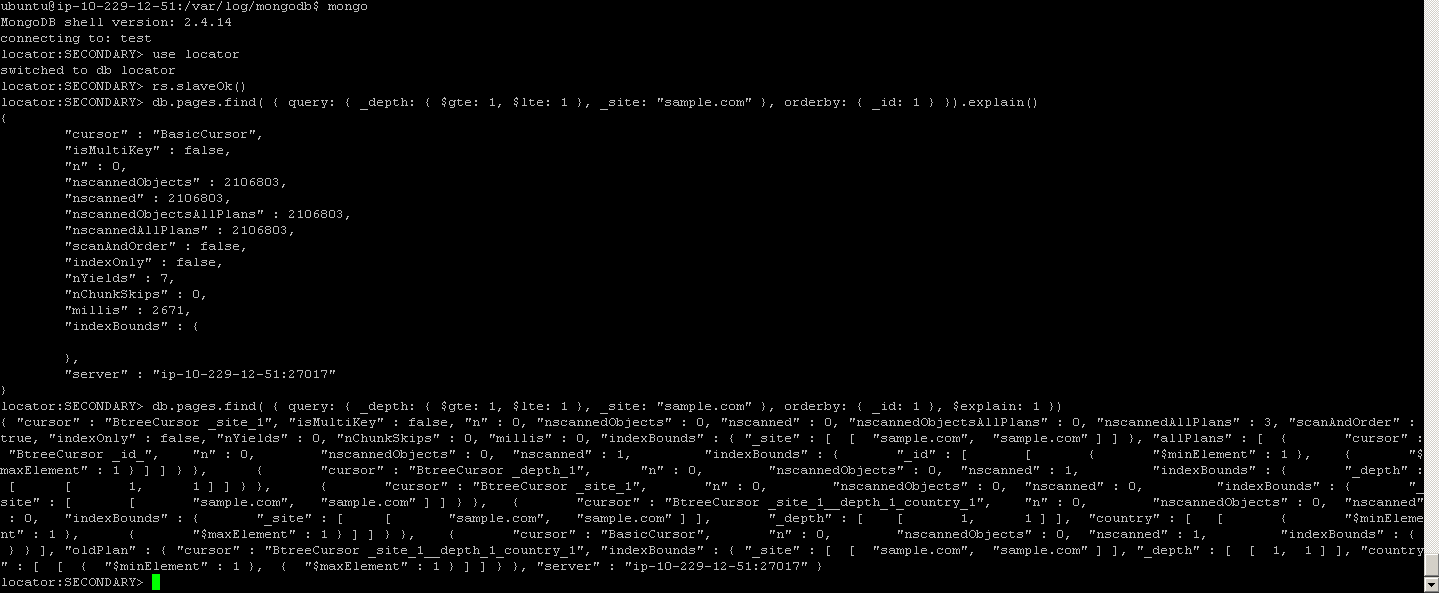
Screenshots
Secondary Node 1 - The other follows the same pattern.
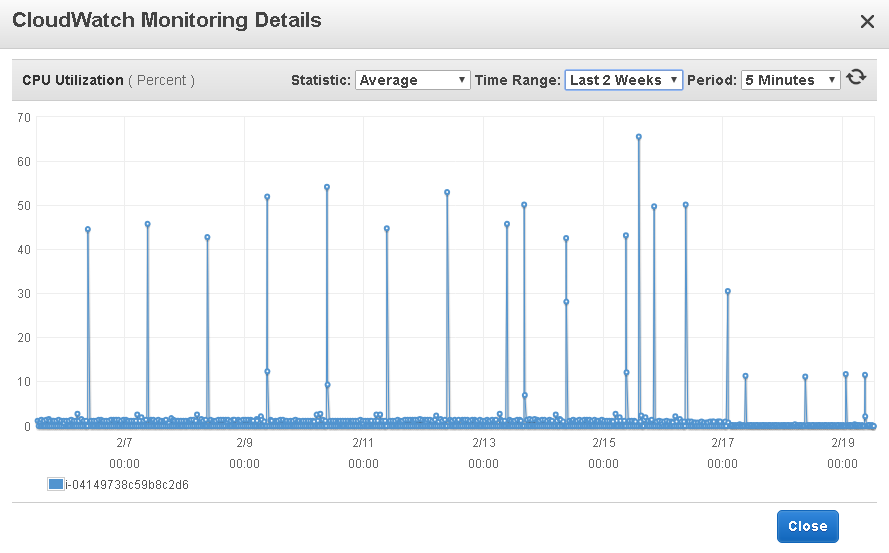
Primary Node (mostly idle except for nightly batch loads)
{kind=link}
{kind=link}
{kind=link}
{kind=link}