-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Critical - P2
Critical - P2
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
Environment:Linix, 1.8.3, aws:m2.4xlarge, filesystem on tmpfs
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
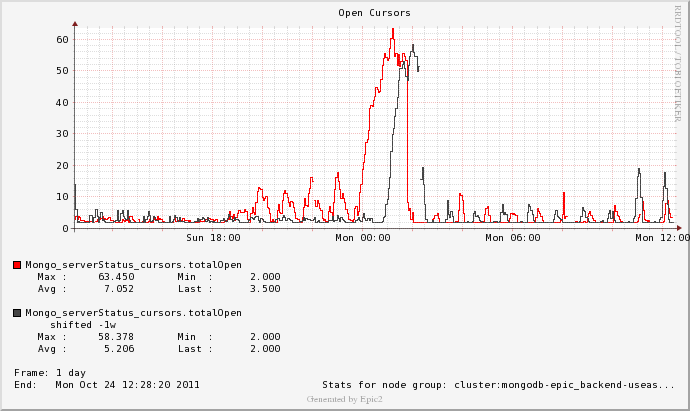
Something happens and our open cursors start climbing. We alert internally when it hits a number much higher than normal (55). To recover, we restart the primary. Stopping the primary sometimes fails and requires kill -9. We regularly lose data when we stop the primary (we're ok with some data loss, but the loss seems extreme - orders of magnitude more than shutting down a mysql master and moving to a replica). Note that this happens several times per week (it can happen 5-10 times in a 24 hour period). The last event started at ~12:50am PDT, 10/17/2011 (our alarm went off at ~2:00am and the master was restarted at ~2:20am).
See mms:
clsol:PRIMARY> rs.conf()
{
"_id" : "clsol",
"version" : 1,
"members" : [
,
,
{ "_id" : 2, "host" : "ec2-50-17-247-66.compute-1.amazonaws.com:27017" } ]
}