-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.6.13
-
Component/s: Replication
-
None
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None
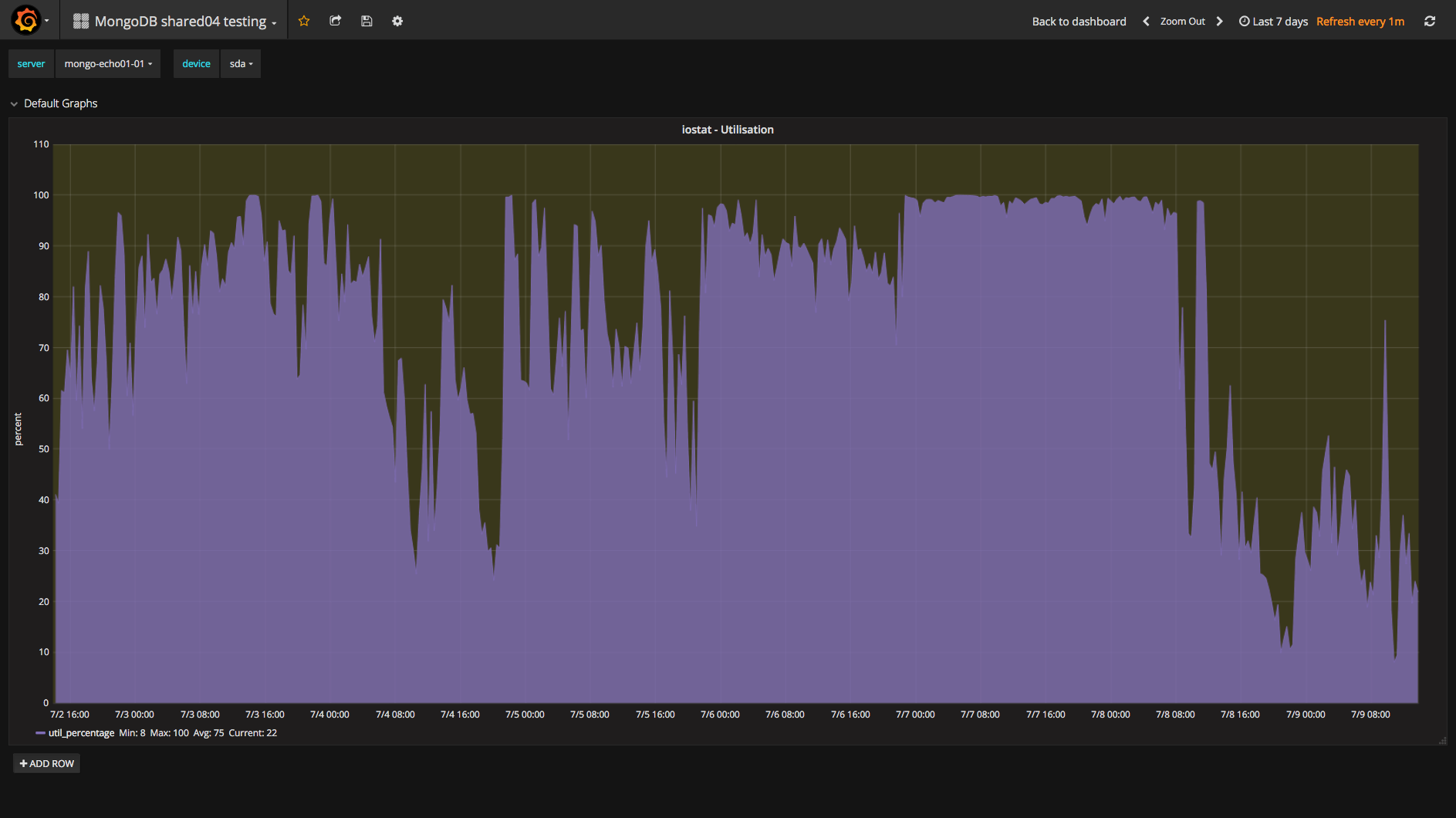
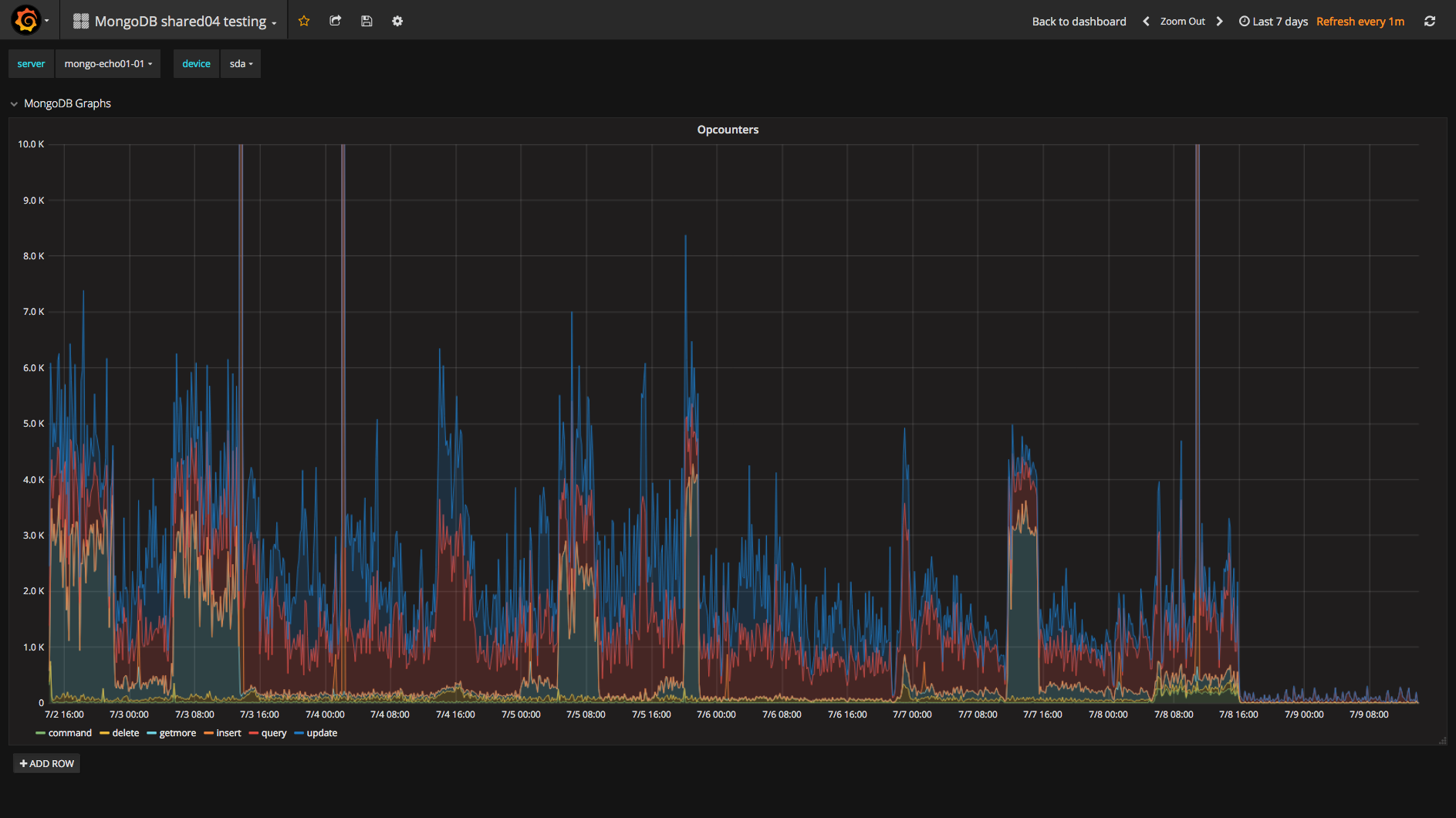
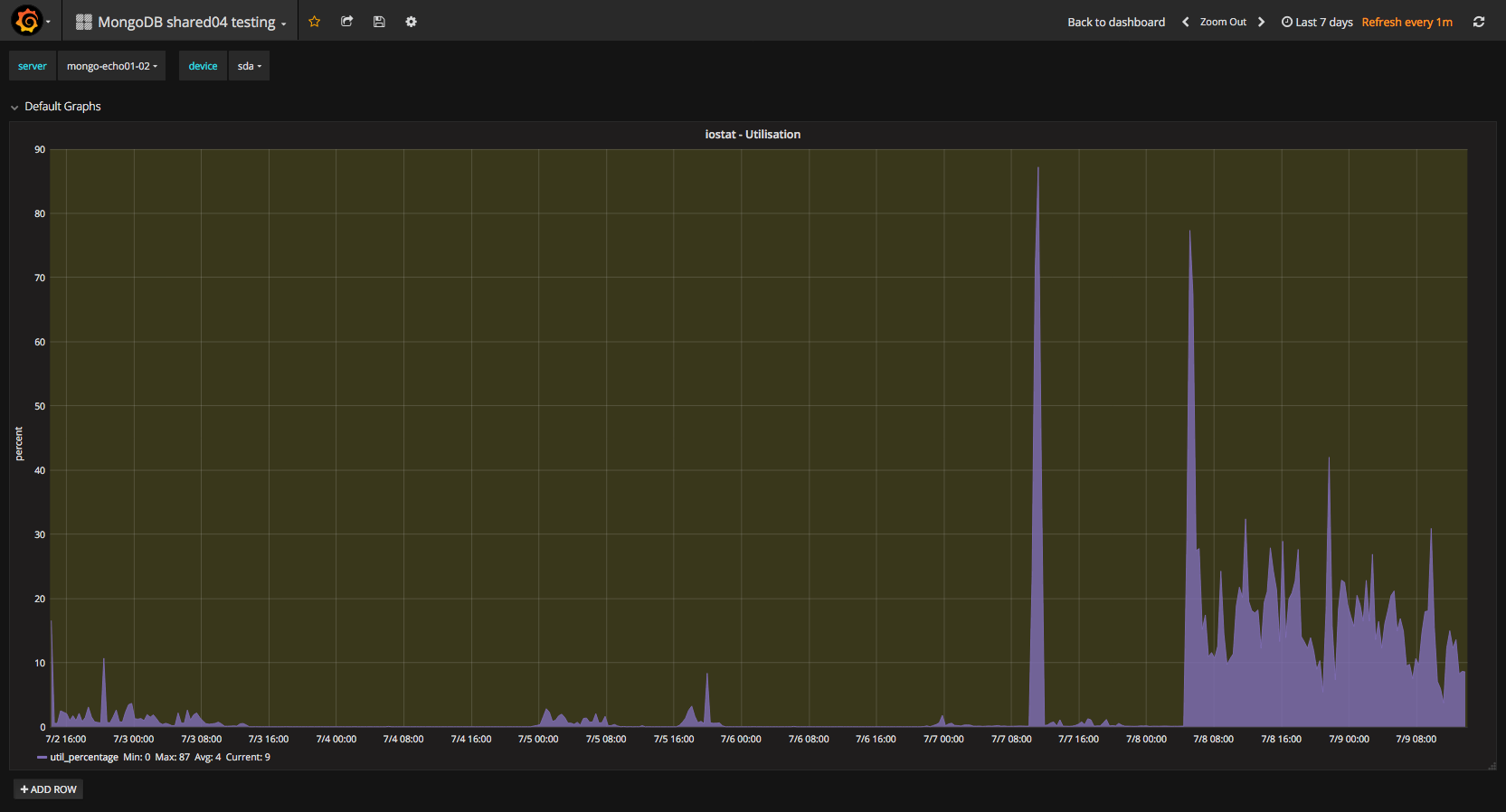
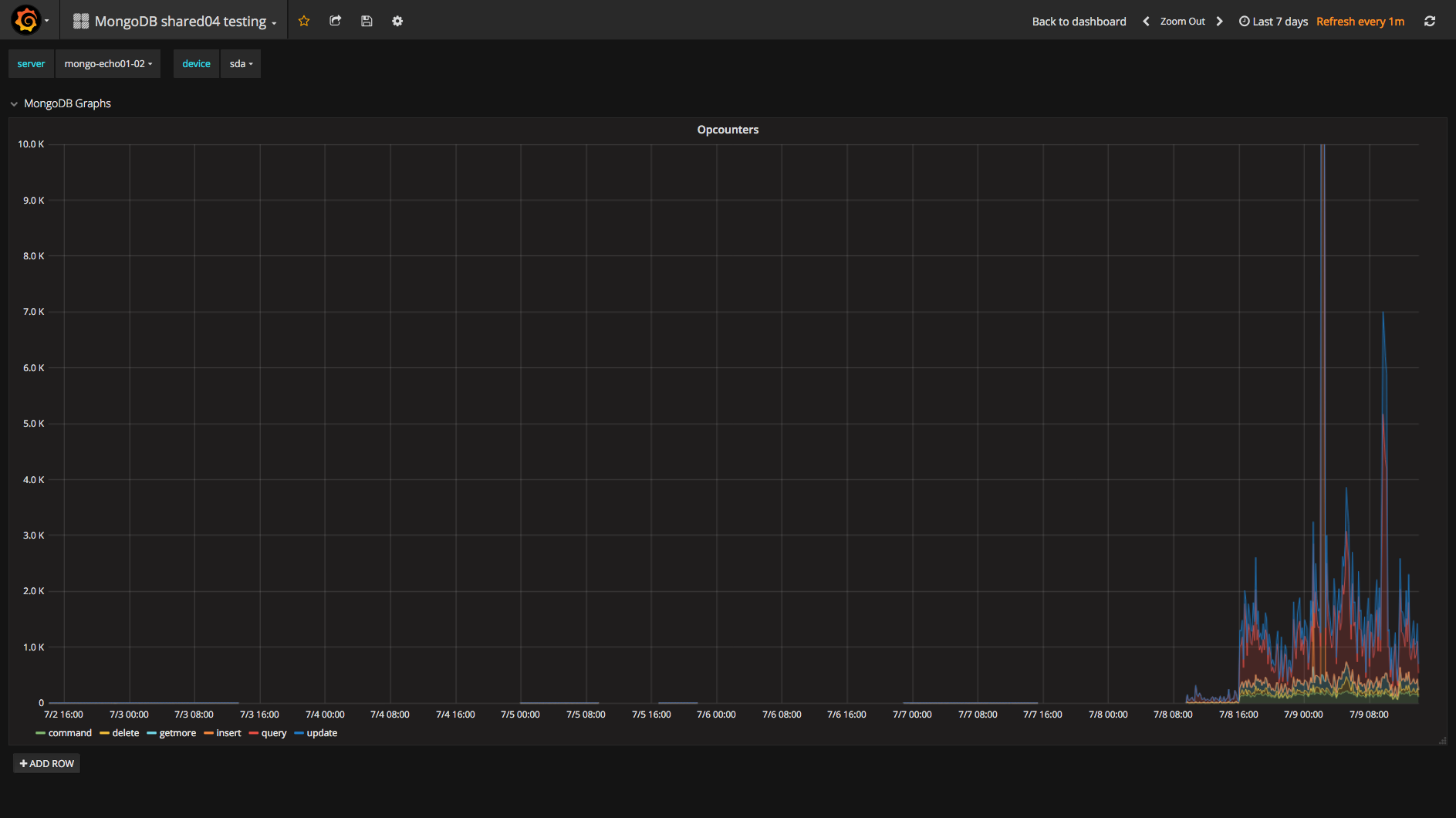
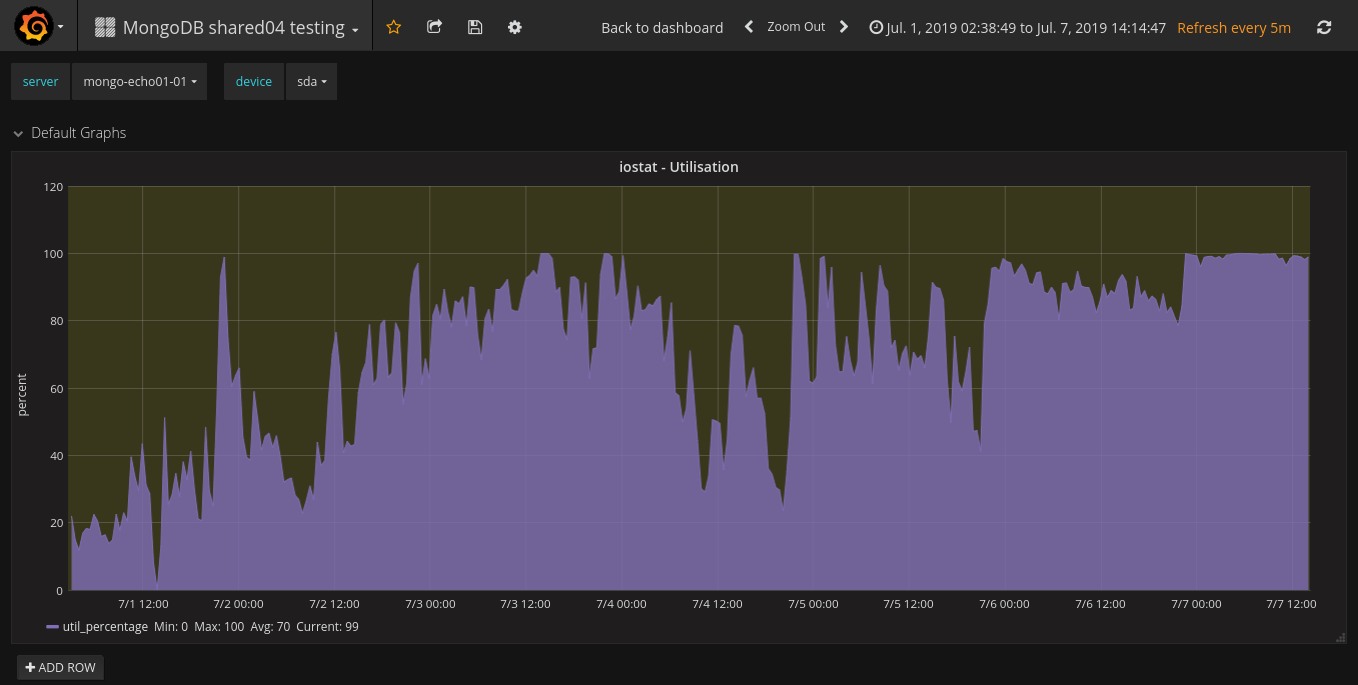
We are unable to add a new replica to a exisiting replica set because the inital sync restarts after cloning is done.
The log says that the new member can't connect to the sync source any longer, so it drops all databases and restarts the initial sync by connecting to the the same sync source which has been declared "unavailabe" just a few seconds ago.
Here are some related log snippets from the new replica. I can send the complete log files from both the sync source and the new replica to a confidential destination.
# Cloning is finished:
2019-07-03T05:25:09.689+0200 I REPL [repl writer worker 0] Finished cloning data: OK. Beginning oplog replay.
2019-07-03T05:25:09.690+0200 I REPL [replication-250] Applying operations until { : Timestamp(1562124309, 5) } before initial sync can complete. (starting at { : Ti
mestamp(1562098892, 137) })
2019-07-03T05:25:09.802+0200 I STORAGE [replication-260] createCollection: local.replset.oplogTruncateAfterPoint with generated UUID: 8488b127-0f54-4294-b9a1-d7ec9acaf
d48
# many of these "update of non-mod failed", "Fetching missing document" and "Missing document not found on source" follow:
2019-07-03T05:25:11.508+0200 E REPL [repl writer worker 5] update of non-mod failed: { ts: Timestamp(1562098895, 15), t: 23, h: -7086754239136309992, v: 2, op: "u",
<CUT-OUT> }
2019-07-03T05:25:11.508+0200 I REPL [repl writer worker 5] Fetching missing document: { ts: Timestamp(1562098895, 15), t: 23, h: -7086754239136309992, v: 2, op: "u"
, <CUT-OUT> }
2019-07-03T05:25:11.510+0200 I REPL [repl writer worker 5] Missing document not found on source; presumably deleted later in oplog. o first field: _id, o2: { _id: {
offerKey: "aebd8b896c20b361df37a4e0d2a51200", listIdentifier: "5621756", siteId: 1 } }
# a few seconds later it "Can no longer connect to initial sync source":
2019-07-03T05:25:57.079+0200 E REPL [replication-259] Failed to apply batch due to 'Location15916: error applying batch :: caused by :: Can no longer connect to ini
tial sync source: mongo-echo01-01.db00.tst06.eu.idealo.com:27017'
2019-07-03T05:25:57.098+0200 I ACCESS [conn1480] Successfully authenticated as principal nagios on admin from client 10.113.1.242:40168
2019-07-03T05:25:57.101+0200 I NETWORK [conn1480] end connection 10.113.1.242:40168 (9 connections now open)
2019-07-03T05:25:57.111+0200 I REPL [replication-250] Finished fetching oplog during initial sync: CallbackCanceled: oplog fetcher shutting down. Last fetched optim
e and hash: { ts: Timestamp(1562124342, 998), t: 23 }[8473475730077512578]
2019-07-03T05:25:57.111+0200 I REPL [replication-250] Initial sync attempt finishing up.
# ...and drops all databases:
2019-07-03T05:25:57.112+0200 E REPL [replication-250] Initial sync attempt failed -- attempts left: 9 cause: Location15916: error applying batch :: caused by :: Can
no longer connect to initial sync source: mongo-echo01-01.db00.tst06.eu.idealo.com:27017
2019-07-03T05:25:58.112+0200 I REPL [replication-259] Starting initial sync (attempt 2 of 10)
2019-07-03T05:25:58.112+0200 I STORAGE [replication-259] Finishing collection drop for local.temp_oplog_buffer (no UUID).
2019-07-03T05:25:58.904+0200 I STORAGE [replication-259] createCollection: local.temp_oplog_buffer with no UUID.
2019-07-03T05:25:58.910+0200 I REPL [replication-259] sync source candidate: mongo-echo01-01.db00.tst06.eu.idealo.com:27017
2019-07-03T05:25:59.022+0200 I STORAGE [replication-259] dropAllDatabasesExceptLocal 44
# ...and connects anew to the initial sync source within a few milliseconds:
2019-07-03T05:26:16.025+0200 I ASIO [NetworkInterfaceASIO-RS-0] Successfully connected to mongo-echo01-01.db00.tst06.eu.idealo.com:27017, took 35ms (3 connections n
ow open to mongo-echo01-01.db00.tst06.eu.idealo.com:27017)
Some more details:
Both servers (sync source and new replica) have identical hardware, OS and configuration:
- 56 CPUs
- 128 GB RAM
- 4.5 TB HD
- Linux 64 bit, stretch 9.9, xfs
- mongodb v3.6.13, wired tiger
Until a few days ago, both servers were running succesfully in a replica-set with Linux jessy, mongodb v3.4 and ext4. Now we wanted to upgrade them wich was successful for the first server that is now Primary. The oplog sizes of both servers have been increased from 50 GB to 200 GB in order to increase the oplog window which varies now from 30 to 45 hours. The cloning process takes round about 8 hours.
We thought we hit the same bug as described in SERVER-18721 so we set "net.ipv4.tcp_tw_reuse = 1". However we did not observe an increase of TIME_WAIT so it seems to be another cause for our issue.



- is related to
-
-
- Closed
-