-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 4.2.0
-
Component/s: None
-
None
-
ALL
-
-
Execution Team 2019-11-04
-
None
-
None
-
None
-
None
-
None
-
None
-
None
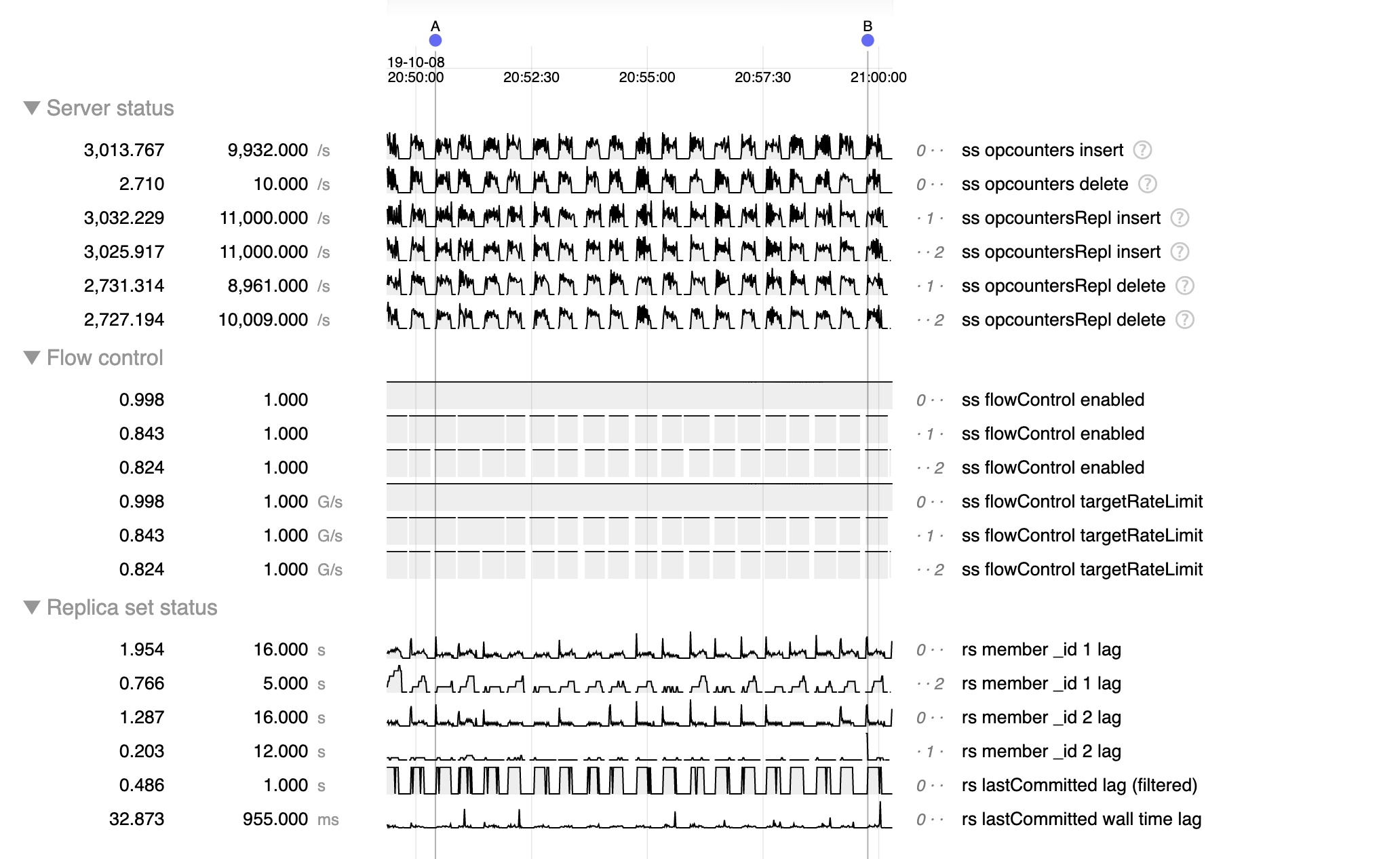
I wrote a workload that does heavy inserts and deletes, and I'm observing many WT cache stuck errors: "Cache stuck for too long, giving up", and replication lag exceeding 47s per node.
I raised the vectored insert batch limit from 256K to 1MB, however, I wouldn't expect this to significantly alter the behavior of flow control, as I understand it.
The workload repetitively performs a large number of inserts then deletes. The goal is to have the inserts batch together an get inserted as a "vector" through the groupAndApplyInserts function during secondary batch application.
This is the patch where I first encountered the issue.
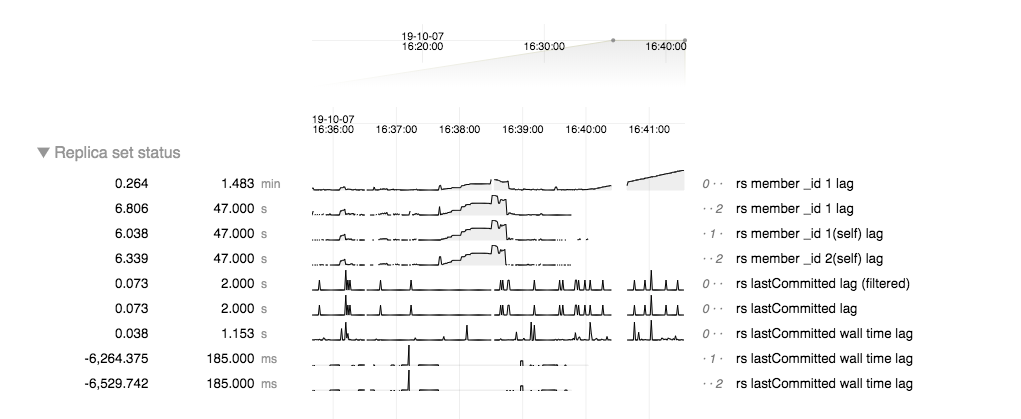
I discussed with maria.vankeulen, and FTDC reports that the lastCommitted and wall time lags are inconsistent with the member lag:
Flow Control, as a direct consumer of lastCommitted lag, will only throttle if this lag is greater than 5 seconds.
Additionally, below are the FTDC stats obtained for Flow Control:

Even when Flow Control is not actively throttling writes, we expect there to be FTDC data on the amount of locks each operation takes, since we sample this data regardless of whether Flow Control is enabled. However, this data is missing.