-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 4.2.2
-
Component/s: Replication, Sharding
-
None
-
Fully Compatible
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
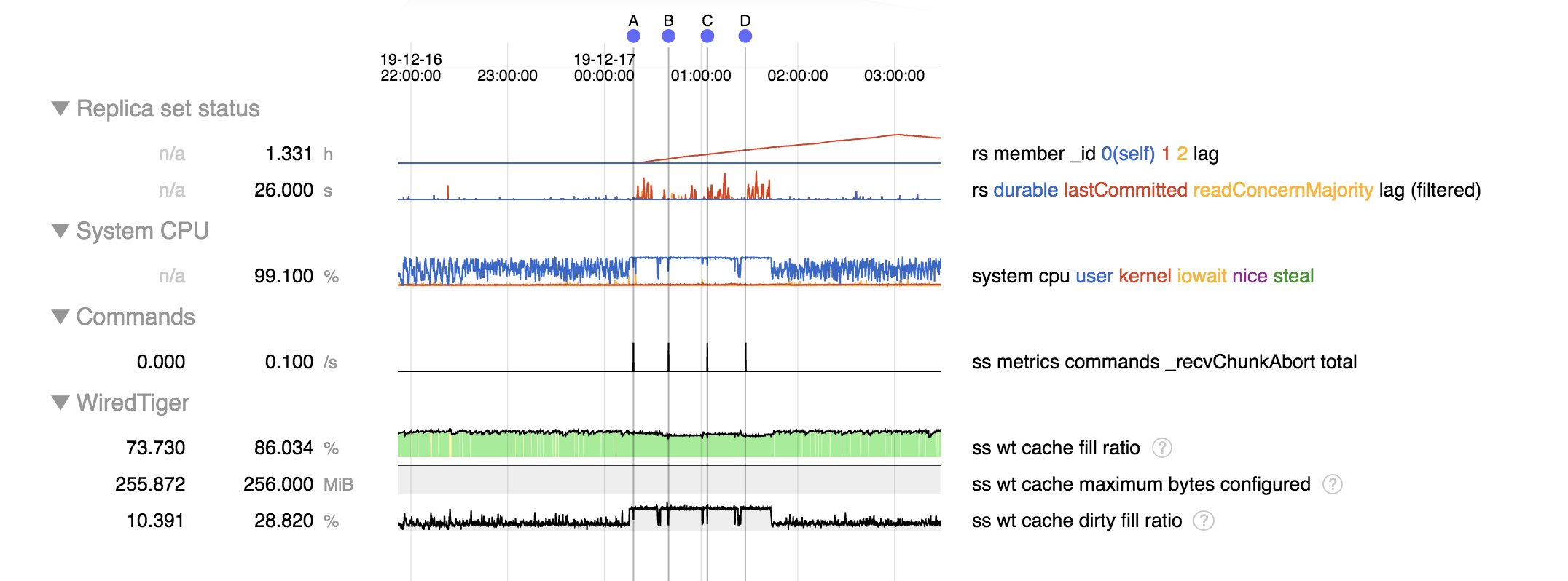
I have a MongoDB Deployment with 3 shards, all deployed as a PSA (Primary, Secondary, Arbiter) Replica Set.
The Cluster works fine as long as the balancer is stopped.
When I enable the balancer it successfully moves chunks for a short while but then begins failing with moveChunk.errors.
This is the error I see on the primary for shard3rs:
2019-12-16T09:39:51.860+0000 I SHARDING [conn47] about to log metadata event into changelog: \{ _id: "edaaf0746692:27017-2019-12-16T09:39:51.860+0000-5df750e7dc45e3a1a34c6889", server: "edaaf0746692:27017", shard: "shard3rs", clientAddr: "10.0.1.72:49758", time: new Date(1576489191860), what: "moveChunk.error", ns: "database.accounts.events", details: { min: { subscriberId: -1352160598807904125 }, max: \{ subscriberId: -1324388048193741545 }, from: "shard3rs", to: "shard2rs" } }
2019-12-16T09:39:52.084+0000 W SHARDING [conn47] Chunk move failed :: caused by :: OperationFailed: Data transfer error: waiting for replication timed out
On the shard2rs the chunk was being moved to I see the same:
2019-12-16T09:39:51.831+0000 I SHARDING [Collection-Range-Deleter] Error when waiting for write concern after removing database.accounts.events range [\{ subscriberId: -1352160598807904125 }, \{ subscriberId: -1324388048193741545 }) : waiting for replication timed out}}
2019-12-16T09:39:51.831+0000 I SHARDING [Collection-Range-Deleter] Abandoning deletion of latest range in database.accounts.events after local deletions because of replication failure
{{2019-12-16T09:39:51.831+0000 I SHARDING [migrateThread] waiting for replication timed out
So it looks like the secondary on shard3rs can't keep up with the deletions and the moveChunk fails after a timeout as the replica set hasn't confirmed the deletions yet.
From the first time a moveChunk.error occurs the replica set get's out of sync and the replication lag just keeps on growing without ever making it back again. The CPU starts rising to 100% as the replica set is trying to keep up while the balancer continues executing moveChunk commands which keep on failing with the same error. This even happens when the balancer is stopped afterwards via sh.stopBalancer()
In theory this shouldn't be happening.
According to the documentation the default _secondaryThrottle setting for wiredTiger on MongoDB > 3.4 is false, so that the migration process does not wait for replication to a secondary but continues immediately with the next document.
I can confirm that _secondaryThrottle is not set:
use config
db.settings.find({})
{ "_id" : "balancer", "mode" : "off", "stopped" : true }
{ "_id" : "chunksize", "value" : 16 }
{ "_id" : "autosplit", "enabled" : false }
So why does the migration still fails with an error of "waiting for replication timed out"?
If necessary I can supply logs of the whole cluster to a secure upload. (Unsure if the Jira file attachment makes them publicly accesible)
{kind=link}