-
Type:
Improvement
-
Resolution: Fixed
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: Performance, Sharding
-
None
-
Fully Compatible
-
v4.4, v4.2, v4.0, v3.6
-
Sharding 2020-03-09, Sharding 2020-03-23, Sharding 2020-04-06, Sharding 2020-04-20
-
(copied to CRM)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Sessions records are small in size, so usually the sessions collection doesn't get automatically splitted by the auto-splitter and thus it is not balanced automatically. This can cause an high load on the primary shard of the sessions collection.
Some context:
The session collection is sharded by default on the `_id` field and a session record looks like this one:
{
"_id" : {
"id" : UUID("48195d0c-aeb6-4271-8bda-1ff004ed3fda"),
"uid" : BinData(0,"47DEQpj8HBSa+/TImW+5JCeuQeRkm5NMpJWZG3hSuFU=")
},
"lastUse" : ISODate("2020-01-16T13:46:28.049Z")
}
As you can see the `_id` field is an object itself and the internal `id` is of type UUID. In particular we use UUIDv4 that is a 128-bit randomly generated number. Since some of the internal bits are used to store the version and the variant, it is not possible to use normal integer arithmetics on this type. Fortunately we can still compare two UUID and sort them, this is necessary to use them as split points.
I ran a syntethic benchmark to see how sessions get distributed on a partitioned collection. I partitioned the collection in 10 equally sized chunks and assigned each one to a different shard. I tried first to simulate 1000 sessions and then 100.000.
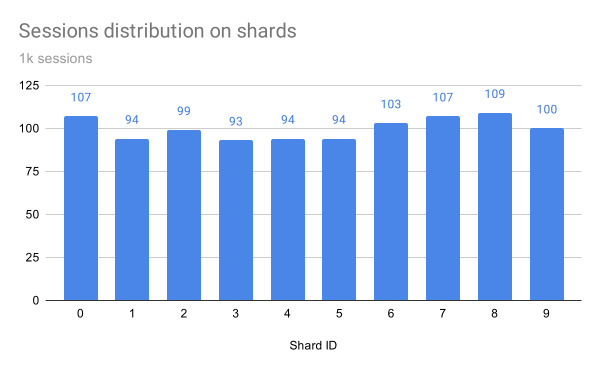

As you can see from the graphs the truly random distribution of the generated UUID made possible to distribute them fairly among the shards.
I've also created a js script that if executed on a mongos will partition the session collection and it will distribute one chunk to every shard.


- related to
-
SERVER-66078 Adapt sessions collection balacing policy to data-size aware balancing
-
- Closed
-