Hide
Here are some chronological traces:
Command convertToCapped executed at 11:54:13 and terminated at 13:15:34:
PRO [21:39][root@mongo-hotel01-01.db00.pro07:/home/kay.agahd]# ✔ grep "convertToCapped" /data/sharedSystem01/log/sharedSystem01.log
2020-03-20T11:54:13.749+0100 I STORAGE [conn39183053] createCollection: mongodba.tmphDRLk.convertToCapped.slowops with generated UUID: 90759c88-dcce-463a-9e95-e29c54ab1d00
2020-03-20T13:15:08.832+0100 I COMMAND [conn39183053] renameCollection: renaming collection no UUID from mongodba.tmphDRLk.convertToCapped.slowops to mongodba.slowops
2020-03-20T13:15:34.323+0100 I COMMAND [conn39183053] command mongodba.tmphDRLk.convertToCapped.slowops appName: "MongoDB Shell" command: convertToCapped { convertToCapped: "slowops", size: 69793218560.0, shardVersion: [ Timestamp(0, 0), ObjectId('000000000000000000000000') ], lsid: { id: UUID("fbe556af-08f9-46af-89fc-09fbde81142a"), uid: BinData(0, 3B408CB48548B5037822C10EB0976B3CBF2CEE3BF9C708796BF03941FBECD80F) }, $clusterTime: { clusterTime: Timestamp(1584701653, 8698), signature: { hash: BinData(0, BC39D22EAB7430F38A7C3701C473DD02FCCB3D2B), keyId: 6796240667325497611 } }, $client: { application: { name: "MongoDB Shell" }, driver: { name: "MongoDB Internal Client", version: "3.6.13" }, os: { type: "Linux", name: "PRETTY_NAME="Debian GNU/Linux 9 (stretch)"", architecture: "x86_64", version: "Kernel 4.9.0-11-amd64" }, mongos: { host: "mongo-hotel-01:27017", client: "127.0.0.1:42800", version: "3.6.13" } }, $configServerState: { opTime: { ts: Timestamp(1584701649, 3098), t: 14 } }, $db: "mongodba" } numYields:0 reslen:288 locks:{ Global: { acquireCount: { r: 223917487, w: 223917487 } }, Database: { acquireCount: { w: 223917484, W: 3 } }, Metadata: { acquireCount: { W: 223917482 } }, oplog: { acquireCount: { w: 223917484 } } } protocol:op_msg 4880614ms
PRO [22:23][root@mongo-hotel01-01.db00.pro07:/home/kay.agahd]
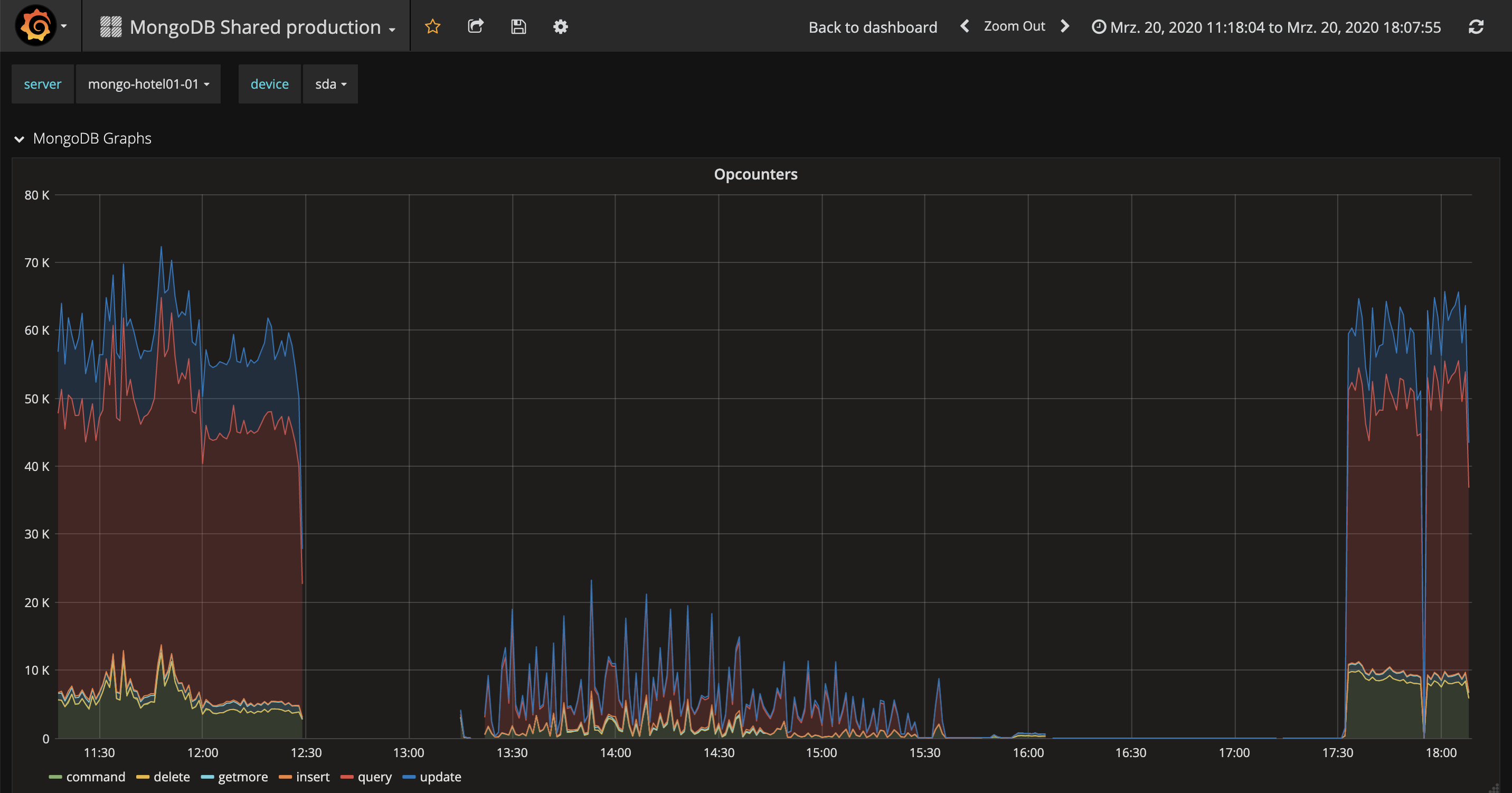
Index Build started at 13:15:38 and finished at 17:58:25.
2020-03-20T13:15:38.654+0100 I - [conn39189395] Index Build (background): 2200/223918168 0%
...
2020-03-20T14:45:33.113+0100 I - [conn39232652] Index Build (background): 5407600/224961851 2%
2020-03-20T17:58:15.033+0100 I - [conn39266887] Index Build (background): 230800/1292208 17%
2020-03-20T17:58:18.003+0100 I - [conn39266887] Index Build (background): 529900/1292208 41%
2020-03-20T17:58:21.002+0100 I - [conn39266887] Index Build (background): 858200/1292208 66%
2020-03-20T17:58:24.006+0100 I - [conn39266887] Index Build (background): 1142800/1292208 88%
2020-03-20T17:58:25.451+0100 I INDEX [conn39266887] build index done. scanned 1292208 total records. 13 secs
The first 17% of the index build took nearly 5 hours while the rest took only a few seconds. Or was the index build killed by my command killOp or killSession, executed at 14:53:25 eventually?
2020-03-20T14:53:25.208+0100 I COMMAND [conn39249255] command admin.$cmd appName: "MongoDB Shell" command: killSessions { killSessions: [ { id: UUID("81914921-f985-464d-ad3a-7ab007c2b895"), uid: BinData(0, 4E5C22C0742A0A942E4361737D42A397DBF0E56F30DC26CB617A186C91FF4A48) } ], lsid: { id: UUID("be3079b7-ffb7-435c-938e-262ca10da9a6") }, $clusterTime: { clusterTime: Timestamp(1584712403, 84), signature: { hash: BinData(0, A820811A96105BC4B5D4ADF5FBACAD96714937D2), keyId: 6796240667325497611 } }, $db: "admin" } numYields:0 reslen:268 locks:{} protocol:op_msg 231ms
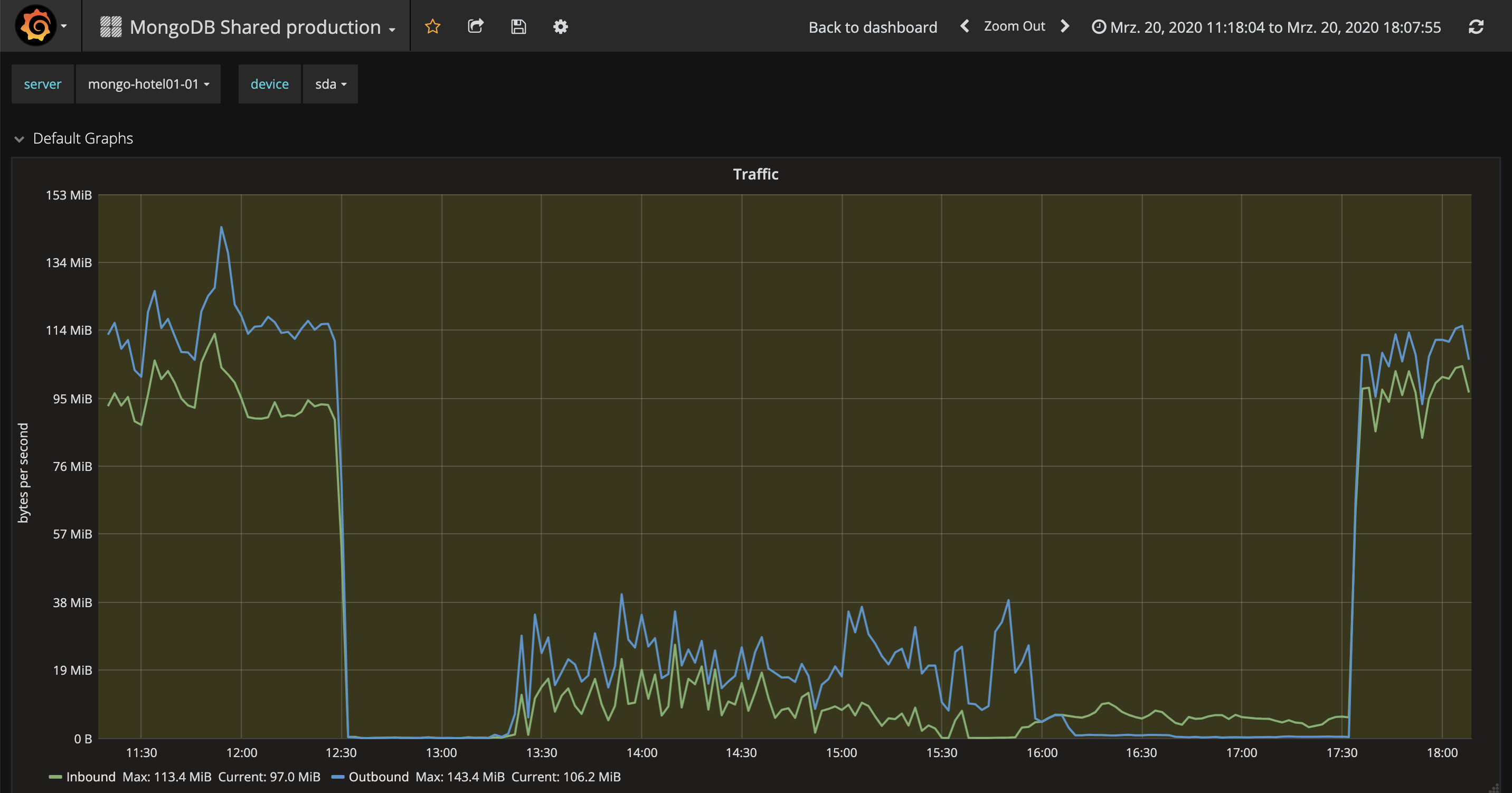
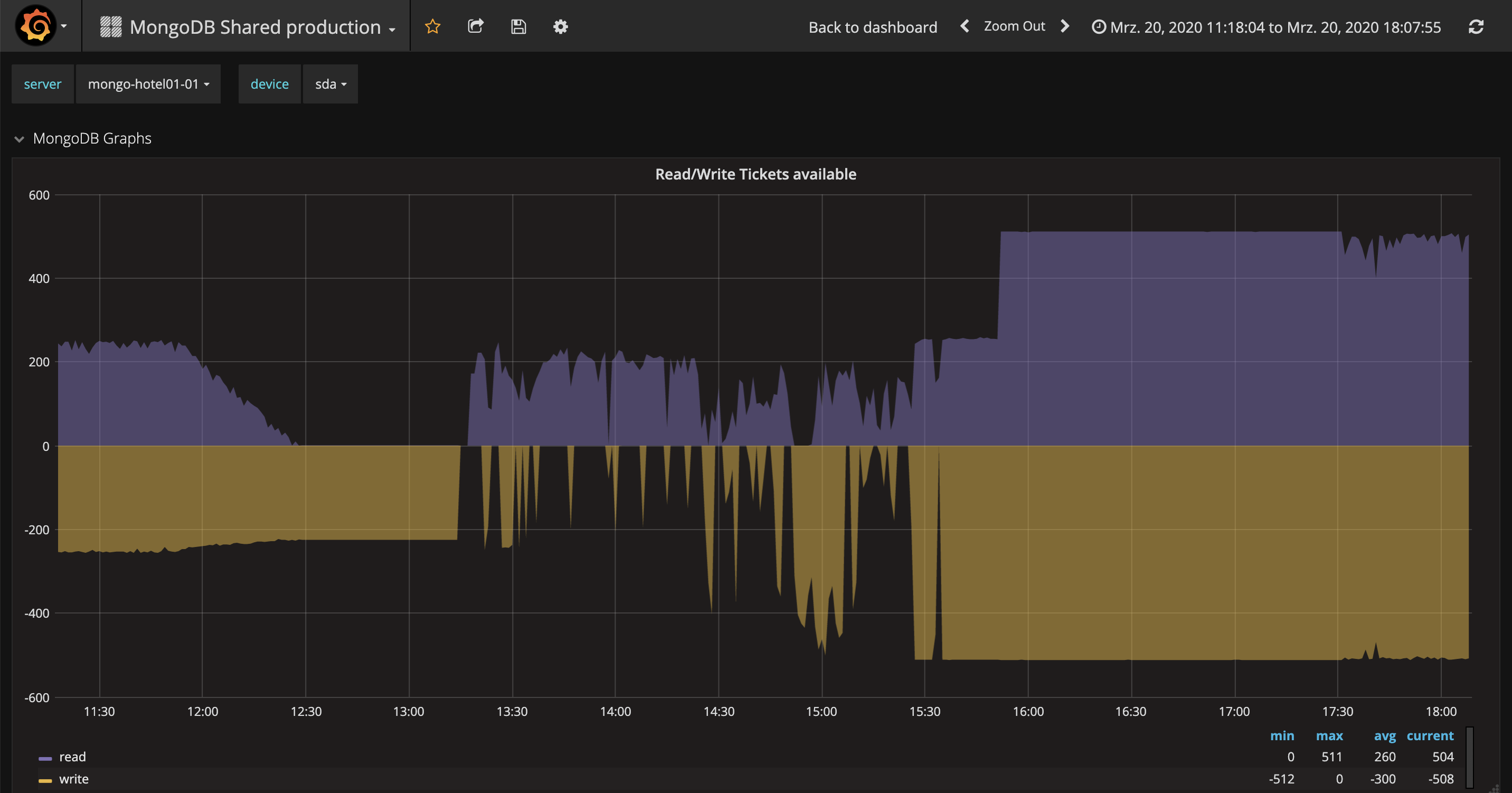
At around 14:20 we remark that read and write ticket are out, so we increase it from 256 to 512:
2020-03-20T14:24:08.435+0100 I COMMAND [conn39247774] successfully set parameter wiredTigerConcurrentWriteTransactions to 512.0 (was 256)
2020-03-20T14:24:27.886+0100 I COMMAND [conn39247774] successfully set parameter wiredTigerConcurrentReadTransactions to 512.0 (was 256)
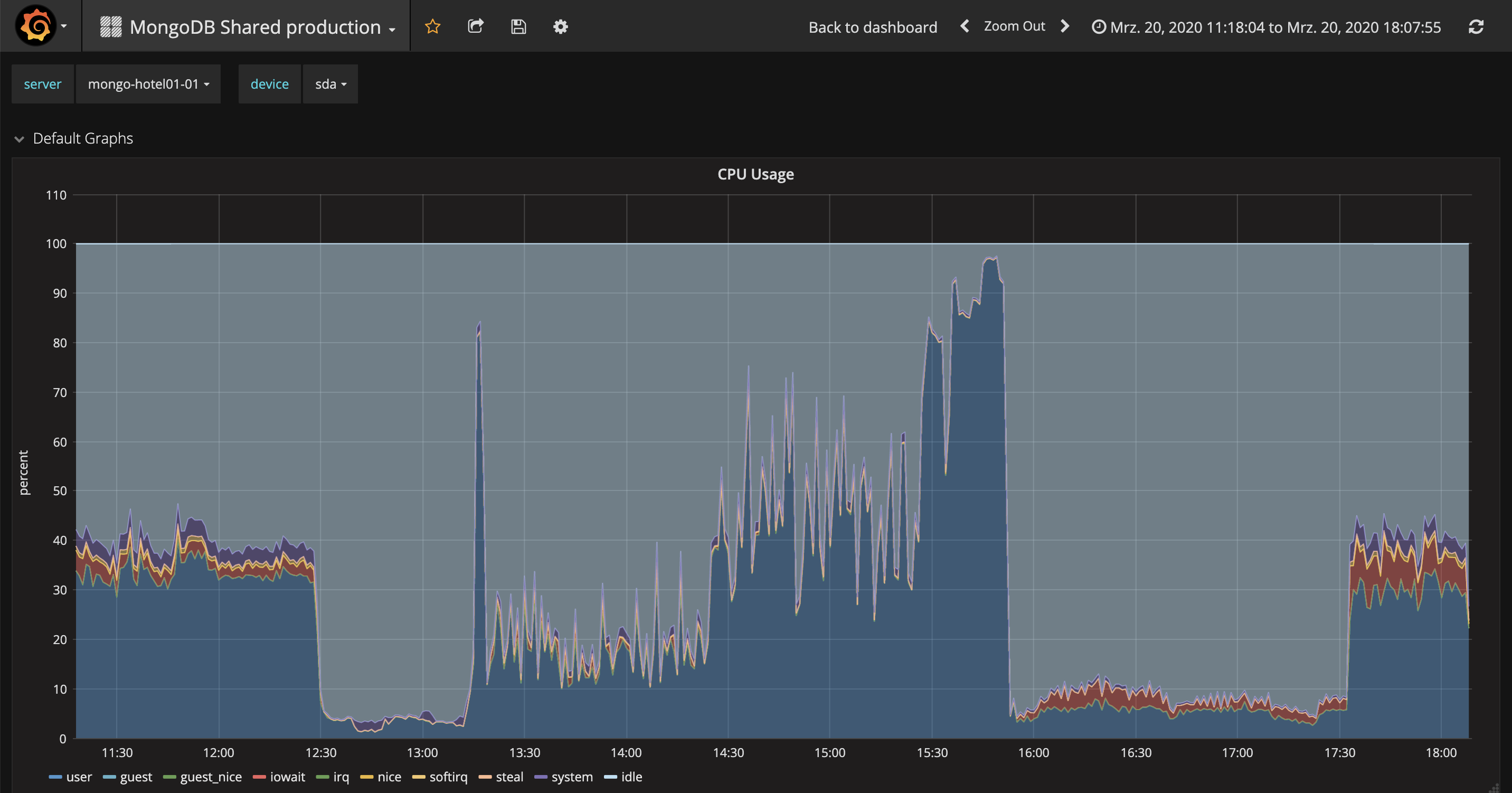
At around 15:00 we remark that replication got stuck on both secondaries.
At 15:19:41 we restart one secondary to see if replication will work again, but no success.
2020-03-20T15:19:41.790+0100 I CONTROL [main] ***** SERVER RESTARTED *****
At around 15:25 we shut down the 3 most heavily loaded routers (mongo-hotel-01, mongo-hotel-02, mongo-hotel-03), so that the DB does not get a load from their clients anymore.
At about 15:50 the first secondary is back in sync, therefore we stepDown the primary because we (wrongly) think it might be a hardware problem:
2020-03-20T15:52:11.954+0100 I COMMAND [conn39249255] Attempting to step down in response to replSetStepDown command
2020-03-20T15:52:11.973+0100 I COMMAND [conn39249255] command admin.$cmd appName: "MongoDB Shell" command: replSetStepDown { replSetStepDown: 60.0, lsid: { id: UUID("be3079b7-ffb7-435c-938e-262ca10da9a6") }, $clusterTime: { clusterTime: Timestamp(1584715911, 226), signature: { hash: BinData(0, 0A644227C73C9075B61DF7053FB6C4B6A467F789), keyId: 6796240667325497611 } }, $db: "admin" } numYields:0 reslen:268 locks:{ Global: { acquireCount: { r: 2, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 10861 } } } protocol:op_msg 148ms
At about 17:20, we promote the stepped-down server to be Primary again because we don't think that's a hardware problem anymore.
Show
Here are some chronological traces:
Command convertToCapped executed at 11:54:13 and terminated at 13:15:34:
PRO [21:39][root@mongo-hotel01-01.db00.pro07:/home/kay.agahd]# ✔ grep "convertToCapped" /data/sharedSystem01/log/sharedSystem01.log
2020-03-20T11:54:13.749+0100 I STORAGE [conn39183053] createCollection: mongodba.tmphDRLk.convertToCapped.slowops with generated UUID: 90759c88-dcce-463a-9e95-e29c54ab1d00
2020-03-20T13:15:08.832+0100 I COMMAND [conn39183053] renameCollection: renaming collection no UUID from mongodba.tmphDRLk.convertToCapped.slowops to mongodba.slowops
2020-03-20T13:15:34.323+0100 I COMMAND [conn39183053] command mongodba.tmphDRLk.convertToCapped.slowops appName: "MongoDB Shell" command: convertToCapped { convertToCapped: "slowops" , size: 69793218560.0, shardVersion: [ Timestamp(0, 0), ObjectId( '000000000000000000000000' ) ], lsid: { id: UUID( "fbe556af-08f9-46af-89fc-09fbde81142a" ), uid: BinData(0, 3B408CB48548B5037822C10EB0976B3CBF2CEE3BF9C708796BF03941FBECD80F) }, $clusterTime: { clusterTime: Timestamp(1584701653, 8698), signature: { hash: BinData(0, BC39D22EAB7430F38A7C3701C473DD02FCCB3D2B), keyId: 6796240667325497611 } }, $client: { application: { name: "MongoDB Shell" }, driver: { name: "MongoDB Internal Client" , version: "3.6.13" }, os: { type: "Linux" , name: "PRETTY_NAME=" Debian GNU/Linux 9 (stretch) "", architecture: " x86_64 ", version: " Kernel 4.9.0-11-amd64 " }, mongos: { host: " mongo-hotel-01:27017 ", client: " 127.0.0.1:42800 ", version: " 3.6.13 " } }, $configServerState: { opTime: { ts: Timestamp(1584701649, 3098), t: 14 } }, $db: " mongodba" } numYields:0 reslen:288 locks:{ Global: { acquireCount: { r: 223917487, w: 223917487 } }, Database: { acquireCount: { w: 223917484, W: 3 } }, Metadata: { acquireCount: { W: 223917482 } }, oplog: { acquireCount: { w: 223917484 } } } protocol:op_msg 4880614ms
PRO [22:23][root@mongo-hotel01-01.db00.pro07:/home/kay.agahd]
Index Build started at 13:15:38 and finished at 17:58:25.
2020-03-20T13:15:38.654+0100 I - [conn39189395] Index Build (background): 2200/223918168 0%
...
2020-03-20T14:45:33.113+0100 I - [conn39232652] Index Build (background): 5407600/224961851 2%
2020-03-20T17:58:15.033+0100 I - [conn39266887] Index Build (background): 230800/1292208 17%
2020-03-20T17:58:18.003+0100 I - [conn39266887] Index Build (background): 529900/1292208 41%
2020-03-20T17:58:21.002+0100 I - [conn39266887] Index Build (background): 858200/1292208 66%
2020-03-20T17:58:24.006+0100 I - [conn39266887] Index Build (background): 1142800/1292208 88%
2020-03-20T17:58:25.451+0100 I INDEX [conn39266887] build index done. scanned 1292208 total records. 13 secs
The first 17% of the index build took nearly 5 hours while the rest took only a few seconds. Or was the index build killed by my command killOp or killSession, executed at 14:53:25 eventually?
2020-03-20T14:53:25.208+0100 I COMMAND [conn39249255] command admin.$cmd appName: "MongoDB Shell" command: killSessions { killSessions: [ { id: UUID( "81914921-f985-464d-ad3a-7ab007c2b895" ), uid: BinData(0, 4E5C22C0742A0A942E4361737D42A397DBF0E56F30DC26CB617A186C91FF4A48) } ], lsid: { id: UUID( "be3079b7-ffb7-435c-938e-262ca10da9a6" ) }, $clusterTime: { clusterTime: Timestamp(1584712403, 84), signature: { hash: BinData(0, A820811A96105BC4B5D4ADF5FBACAD96714937D2), keyId: 6796240667325497611 } }, $db: "admin" } numYields:0 reslen:268 locks:{} protocol:op_msg 231ms
At around 14:20 we remark that read and write ticket are out, so we increase it from 256 to 512:
2020-03-20T14:24:08.435+0100 I COMMAND [conn39247774] successfully set parameter wiredTigerConcurrentWriteTransactions to 512.0 (was 256)
2020-03-20T14:24:27.886+0100 I COMMAND [conn39247774] successfully set parameter wiredTigerConcurrentReadTransactions to 512.0 (was 256)
At around 15:00 we remark that replication got stuck on both secondaries.
At 15:19:41 we restart one secondary to see if replication will work again, but no success.
2020-03-20T15:19:41.790+0100 I CONTROL [main] ***** SERVER RESTARTED *****
At around 15:25 we shut down the 3 most heavily loaded routers (mongo-hotel-01, mongo-hotel-02, mongo-hotel-03), so that the DB does not get a load from their clients anymore.
At about 15:50 the first secondary is back in sync, therefore we stepDown the primary because we (wrongly) think it might be a hardware problem:
2020-03-20T15:52:11.954+0100 I COMMAND [conn39249255] Attempting to step down in response to replSetStepDown command
2020-03-20T15:52:11.973+0100 I COMMAND [conn39249255] command admin.$cmd appName: "MongoDB Shell" command: replSetStepDown { replSetStepDown: 60.0, lsid: { id: UUID( "be3079b7-ffb7-435c-938e-262ca10da9a6" ) }, $clusterTime: { clusterTime: Timestamp(1584715911, 226), signature: { hash: BinData(0, 0A644227C73C9075B61DF7053FB6C4B6A467F789), keyId: 6796240667325497611 } }, $db: "admin" } numYields:0 reslen:268 locks:{ Global: { acquireCount: { r: 2, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 10861 } } } protocol:op_msg 148ms
At about 17:20, we promote the stepped-down server to be Primary again because we don't think that's a hardware problem anymore.
Bug
 Major - P3
Major - P3