-
Type:
Bug
-
Resolution: Incomplete
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 4.2.8
-
Component/s: None
-
None
-
Environment:MongoDB v4.2.8
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
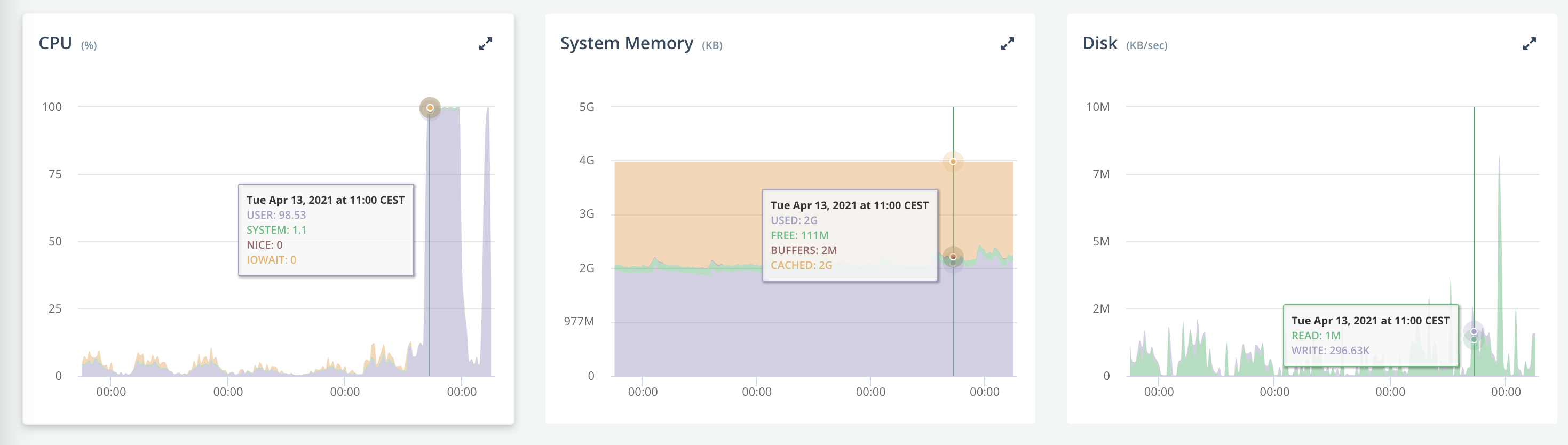
We ran into an issue we can't explain, when adding a covering index on a distinct query caused huge performance issues, and we observed the CPU of our instances going to 100%. Amongst other metrics, we weren't able to find anything that seemed to be correlated to the problem (swap, page faults, etc seemed as usual, but maybe we weren't looking at the right things)
Here is a sample event document. Note the nested properties.id field that we are performing a distinct() on
{
"_id"=>ObjectId('6076c00c63aa1f0968fa5240'),
"name"=>"Viewed profile",
"properties"=>{
"id"=>"5d31acbec00a89296d164e90",
"navigation_referrer"=>"WISHLIST",
"couple_id"=>"{hex}"
},
"time"=>"2021-04-14T10:12:27.752Z",
"ip"=>"195.83.xxx.xx",
"referrer"=>"{string}",
"visit_id"=>ObjectId('6076bef8ffdc312fe32aa6d2')
"user_id"=>ObjectId('5899d66584b2523570ec4993')
)
}
of a collection of about 20 million documents
We perform the following query
db.ahoy_events.explain().distinct("properties.id", {name: "Viewed profile", user_id: ObjectId("5899d66584b2523570ec4993")})
Previously, we had no covering index on this type of query, and the selected plan was
"winningPlan" : { "stage" : "FETCH", "inputStage" : { "stage" : "IXSCAN", "keyPattern" : { "name" : 1, "user_id" : 1, "time" : -1 }, "indexName" : "Event name with user ID by time", "isMultiKey" : false, "multiKeyPaths" : { "name" : [ ], "user_id" : [ ], "time" : [ ] }, "isUnique" : false, "isSparse" : false, "isPartial" : false, "indexVersion" : 2, "direction" : "forward", "indexBounds" : { "name" : [ "[\"Viewed profile\", \"Viewed profile\"]" ], "user_id" : [ "["ObjectId('5899d66584b2523570ec4993')", "ObjectId('5899d66584b2523570ec4993')"]" ], "time" : [ "["MaxKey", "MinKey"]" ] } } },
Using an index defined for other purposes (1)
{ "name" : 1, "user_id" : 1, "time" : -1 } # (1)
But the request was still fast to the extent or retrieving documents in <1sec
After creating the following index (2)
{ "name" : 1, "properties.id" : 1, "time" : -1, "user_id" : 1 } # (2)
the winning plan becomes
"winningPlan" : { "stage" : "PROJECTION_DEFAULT", "transformBy" : { "_id" : 0, "properties.id" : 1 }, "inputStage" : { "stage" : "DISTINCT_SCAN", "keyPattern" : { "name" : 1, "properties.id" : 1, "time" : -1, "user_id" : 1 }, "indexName" : "user_id by name properties.id and time", "isMultiKey" : false, "multiKeyPaths" : { "name" : [ ], "properties.id" : [ ], "time" : [ ], "user_id" : [ ] }, "isUnique" : false, "isSparse" : false, "isPartial" : true, "indexVersion" : 2, "direction" : "forward", "indexBounds" : { "name" : [ "[\"Viewed profile\", \"Viewed profile\"]" ], "properties.id" : [ "["MinKey", "MaxKey"]" ], "time" : [ "["MaxKey", "MinKey"]" ], "user_id" : [ "["ObjectId('5899d66584b2523570ec4993')", "ObjectId('5899d66584b2523570ec4993')"]" ] } }
And the request becomes very slow as shown in our graphs (the query can take up to several minutes when the server is loaded, and a dozen seconds when it is the only query)
Furthermore, we tried creating another index that matched exactly the query (3)
{ "name" : 1, "user_id" : 1, "properties.id" : 1 } # (3)
The result was that this index was still not selected as a winning plan, and mongoDB kept using the previous index with the extra "time: -1" in the multikey definition (index (2)).
After removing the index (2)
{ "name" : 1, "properties.id" : 1, "time" : -1, "user_id" : 1 }
our new index (3) is selected with a winning plan involving a DISTINCT_SCAN and works fast as expected
So several questions
- What could explain that the new index (2) was so slow despite covering the query ? Is it a bug ?
- What could explain why a more appropriate / shorter index (3) was not selected in favor of (2)