-
Type:
Improvement
-
Resolution: Won't Do
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
Storage Execution
-
Execution Team 2023-03-06, Execution Team 2023-03-20, Execution Team 2023-04-03, Execution Team 2023-04-17, Execution Team 2023-05-01, Execution Team 2023-05-29, Execution Team 2023-06-12, Execution EMEA Team 2023-06-26, Execution EMEA Team 2023-07-10, Execution EMEA Team 2023-07-24, Execution EMEA Team 2023-08-07, Execution EMEA Team 2023-08-21, Execution EMEA Team 2023-09-04, CAR Team 2023-11-13, CAR Team 2023-11-27, CAR Team 2023-12-11, CAR Team 2023-12-25, CAR Team 2024-01-08, CAR Team 2024-01-22, CAR Team 2024-02-05, CAR Team 2024-02-19, CAR Team 2024-03-04
-
0
-
None
-
None
-
None
-
None
-
None
-
None
-
None
SERVER-60049 switched from SingleThreadedLockStats to AtomicLockStats to avoid data races detected by TSAN. At the time a perf run didn't find any regressions, but later on at least one BF found it to be a contributing factor.
The stat counters are only updated by a single thread, so we don't need such strong consistency guarantees. Using relaxed loads, increments and stores we can get the same CPU instructions without creating data races at the C++ memory level: https://godbolt.org/z/cPGT5ex5x
n.fetch_add(1); // vs n.store(n.load(std::memory_order_relaxed) + 1, std::memory_order_relaxed);
I ran a quick & dirty perf patch and there's some improvements and some regressions (can't really explain the regressions, worse instruction cache usage? GCC seems to emit more instructions than Clang in the relaxed case).
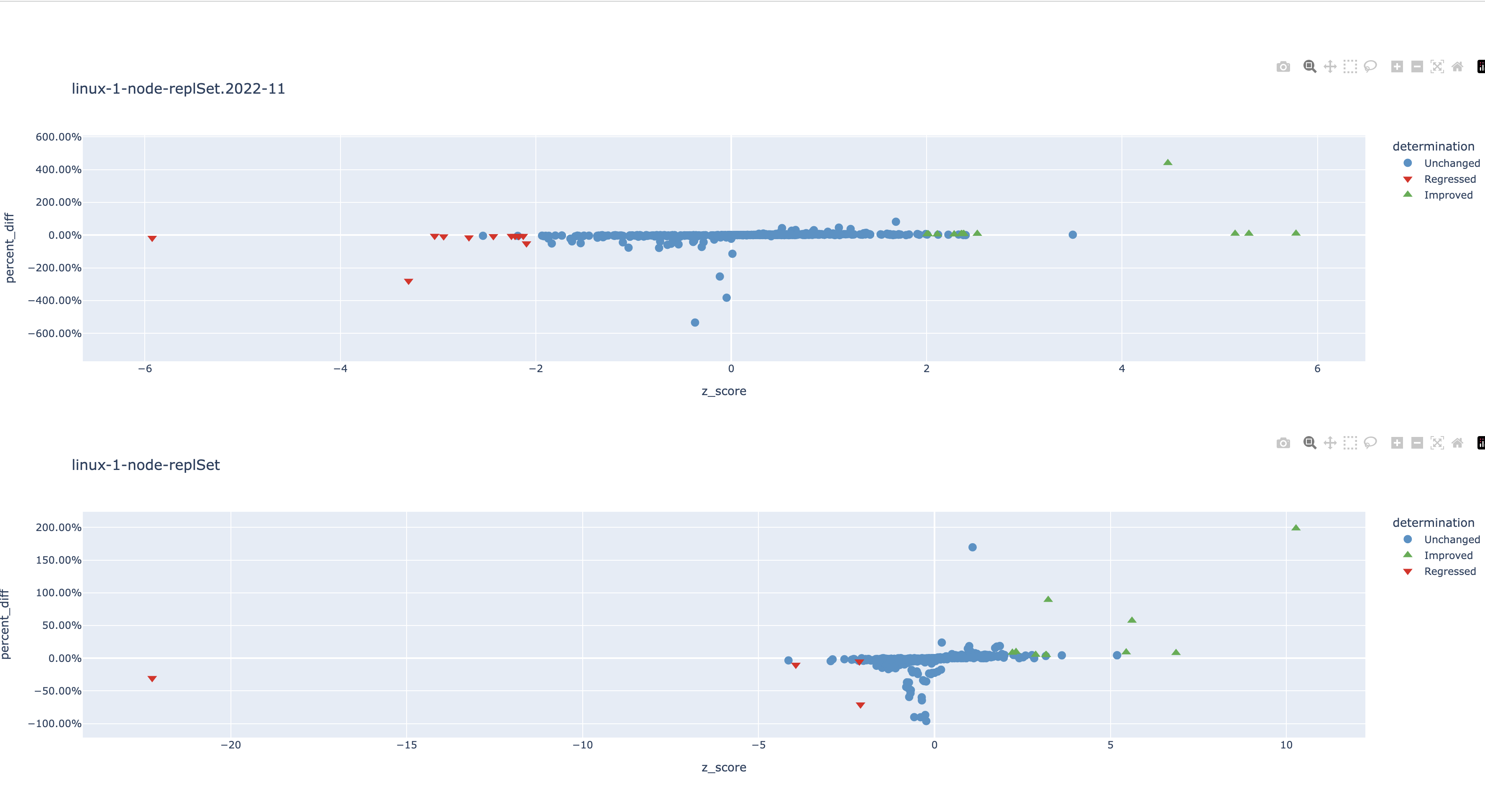
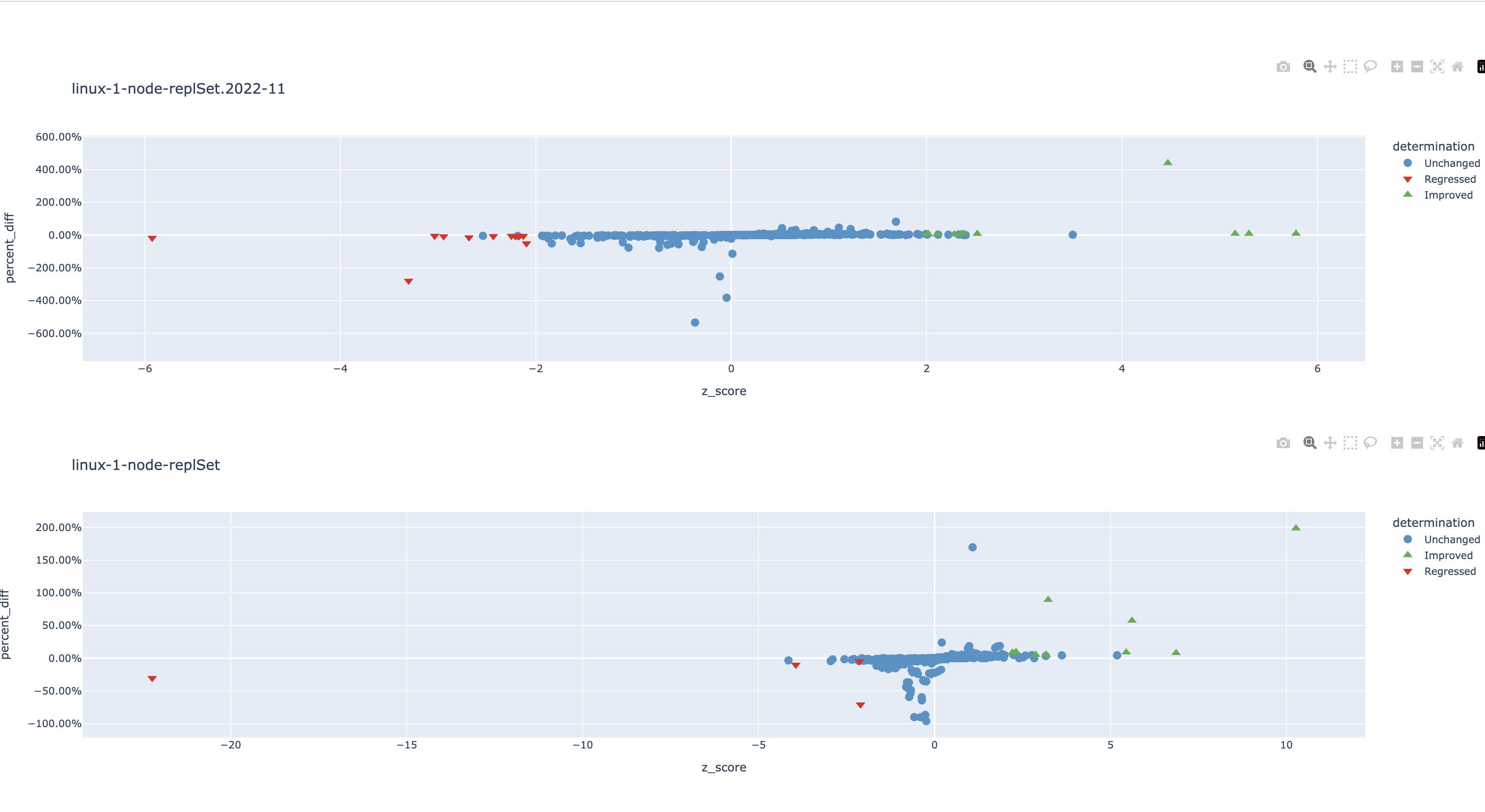{kind=link}