-
Type:
Question
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Our production sharded cluster is facing issues for a while now where wiredtiger cache of primary nodes of each shard are using application threads to evict pages from cache, resulting in read and write failures. This happens when the update bytes breaches 10% of the cache size. We already tried increasing the eviction thread count to 20 and cache size to 70% but didn’t notice any improvements in cache evictions.
Recently one of our nodes auto recovered from this issue and since then the update bytes percentage of that node is under the limit (constantly within 2.5% - 3%). The following are the observations that we made after the auto recovery,
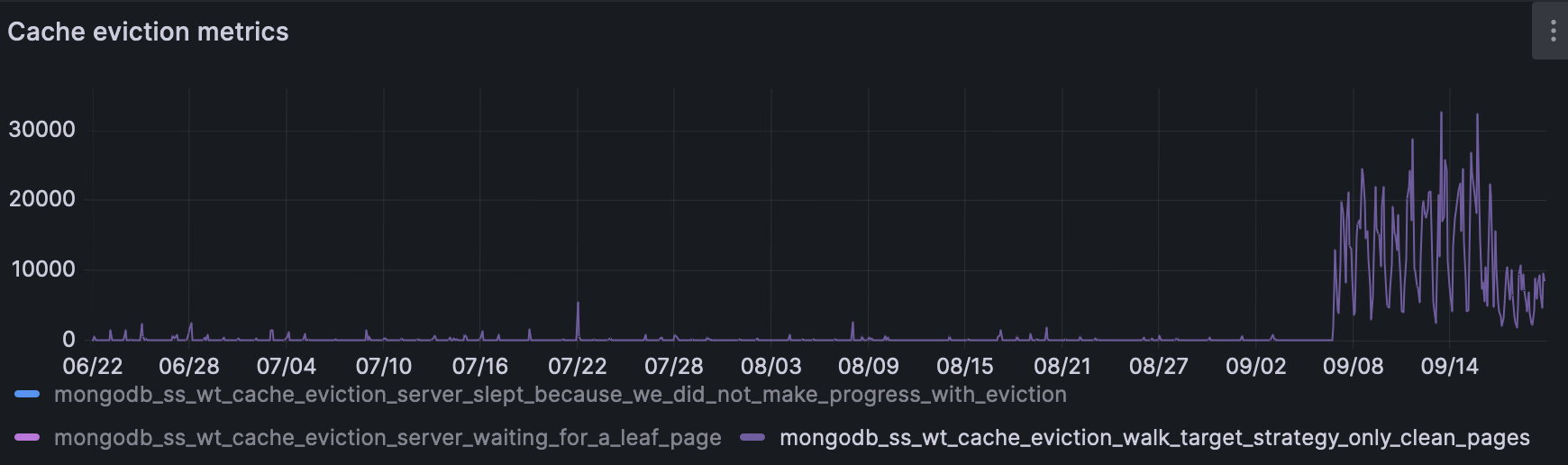
- Decrease in checkpoint blocked page evictions.
- Decrease in cache eviction gave up due to detecting an out of order tombstone ahead of the selected on disk update.
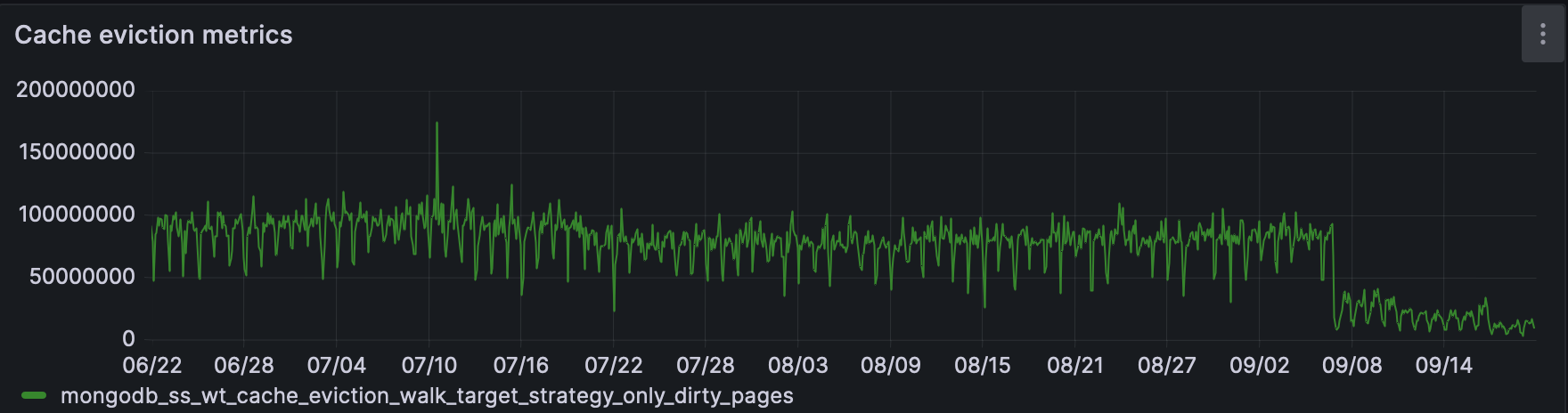
- Change in eviction walk strategy - before the recovery the strategy was only dirty pages. Currently it’s only clean pages.
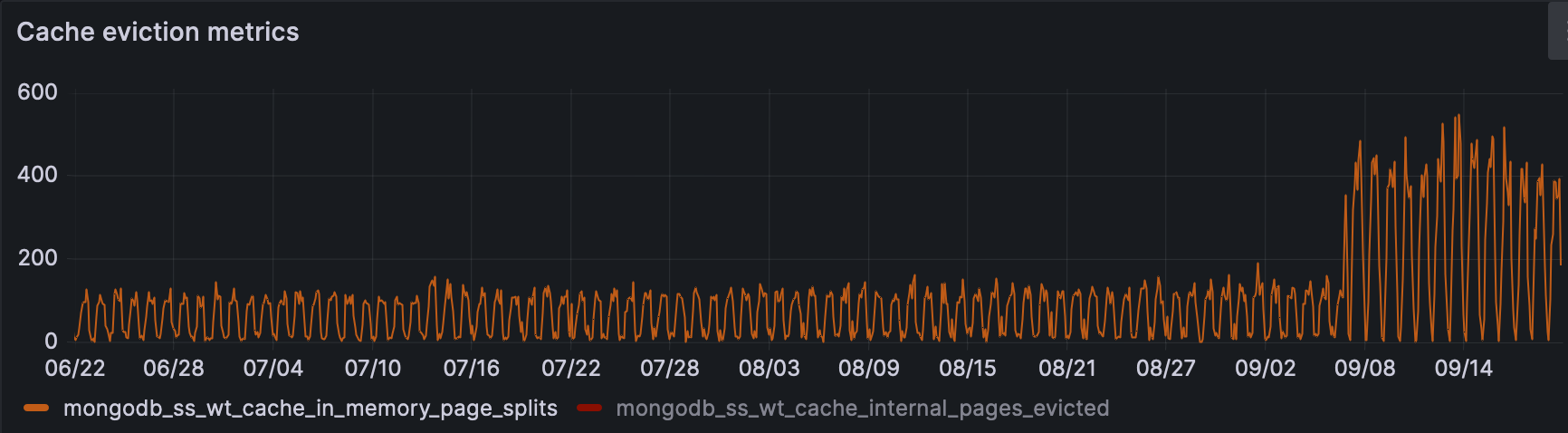
- Decrease in eviction failures due to failure during reconciliation.
- Increase in pages read from disk to cache
We also restarted the mongo process on few of the nodes after which we see the update bytes are within the limit. It would be great to have your suggestions or views regarding this issue which would help us to understand the issue better and fix it.
Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}