-
Type:
Task
-
Resolution: Works as Designed
-
Priority:
 Unknown
Unknown
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
None
-
None
-
None
-
None
-
None
Hi Team,
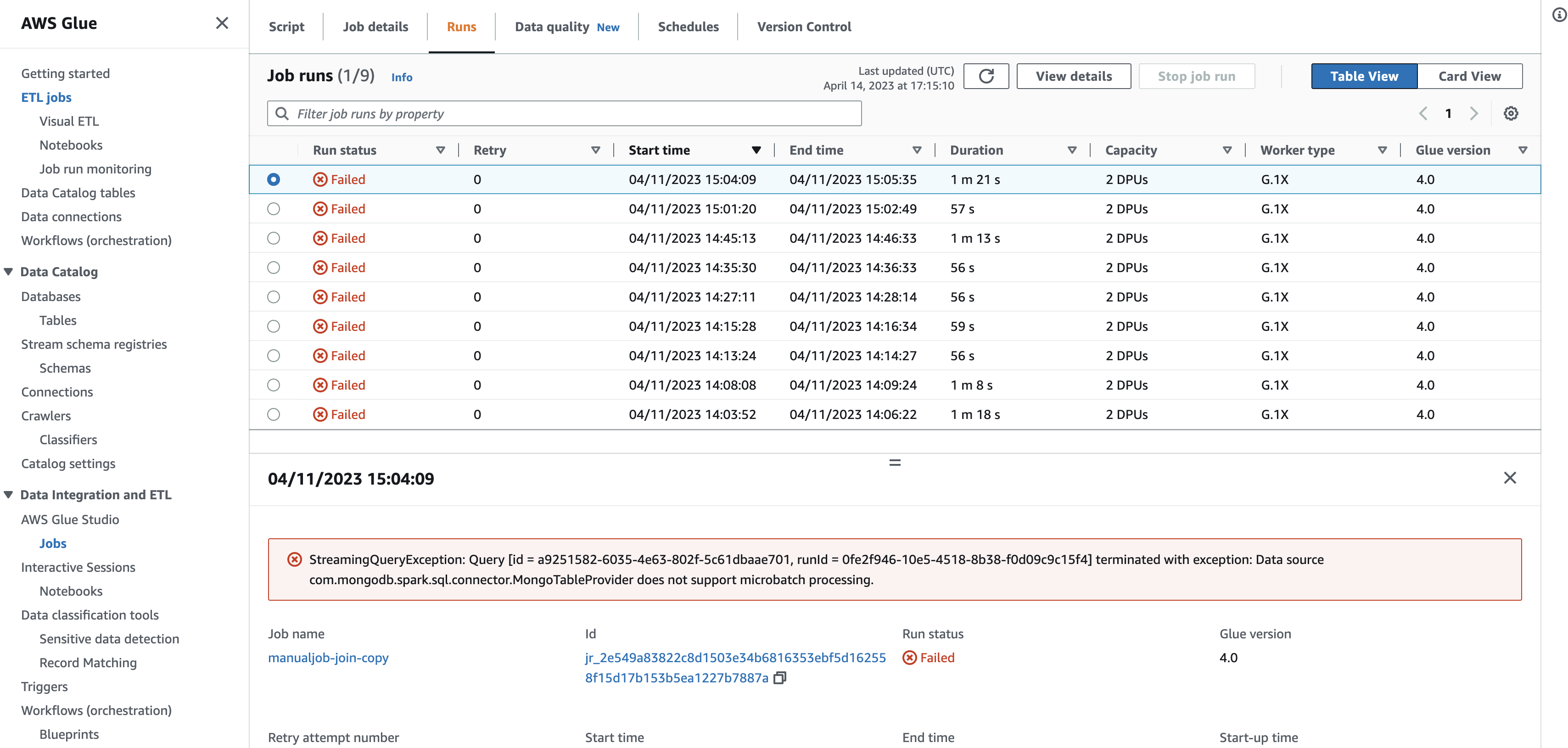
We are trying out the AWS Glue --> Pyspark connector for MongoDB Atlas. While trying out the spark streaming, we are getting the following error.
Error: Data Source com.mongodb.spark.sql.connector.MongoTableProvider does not support microbatch processing.
Let us know, if you need any further details.
Appreciate your support.
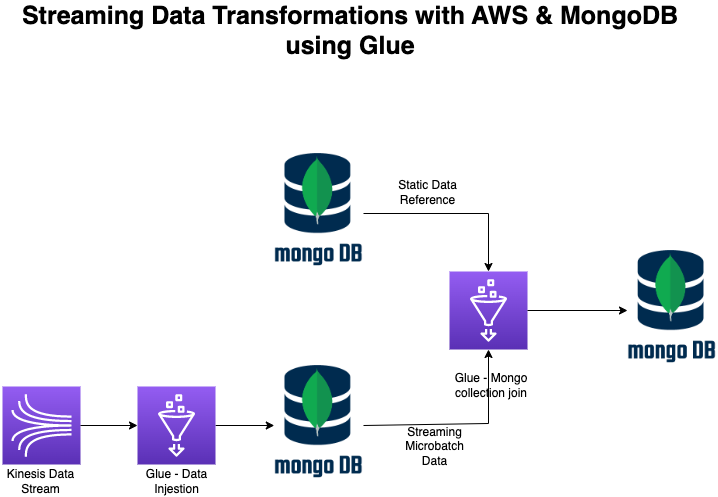
Attached is the error screenshot, the Pyspark code used for streaming, and a high-level flow diag.
{kind=link}
{kind=link}