-
Type:
New Feature
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 1.1.0, 2.0.0
-
Component/s: None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
The default Partitioner strategy ignores the aggregation pipeline completely, causing a lot of empty partitions that slow down the Spark application.
There should be a Partitioner strategy that is able to create partitions based on the aggregation pipeline that will be executed.
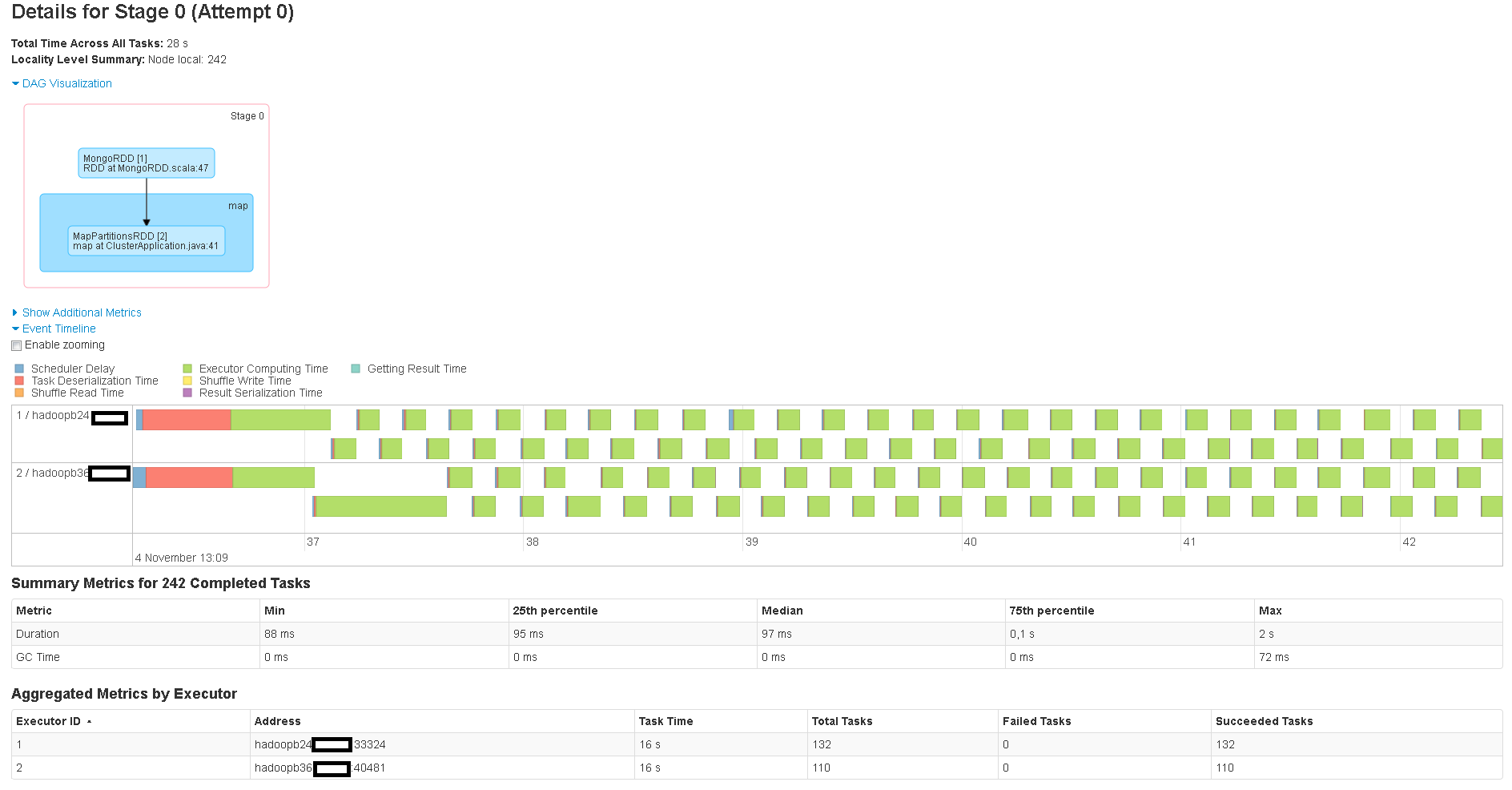
In the Spark WebUI of my application, I can see a lot of partitions being created and processed eventhough they are completely empty. My aggregation is trimming down the expected count of documents from several hundred millions to just hundreds. The current default partitioner seems to ignore this and builds 242 partitions. See the attached images for clarification:
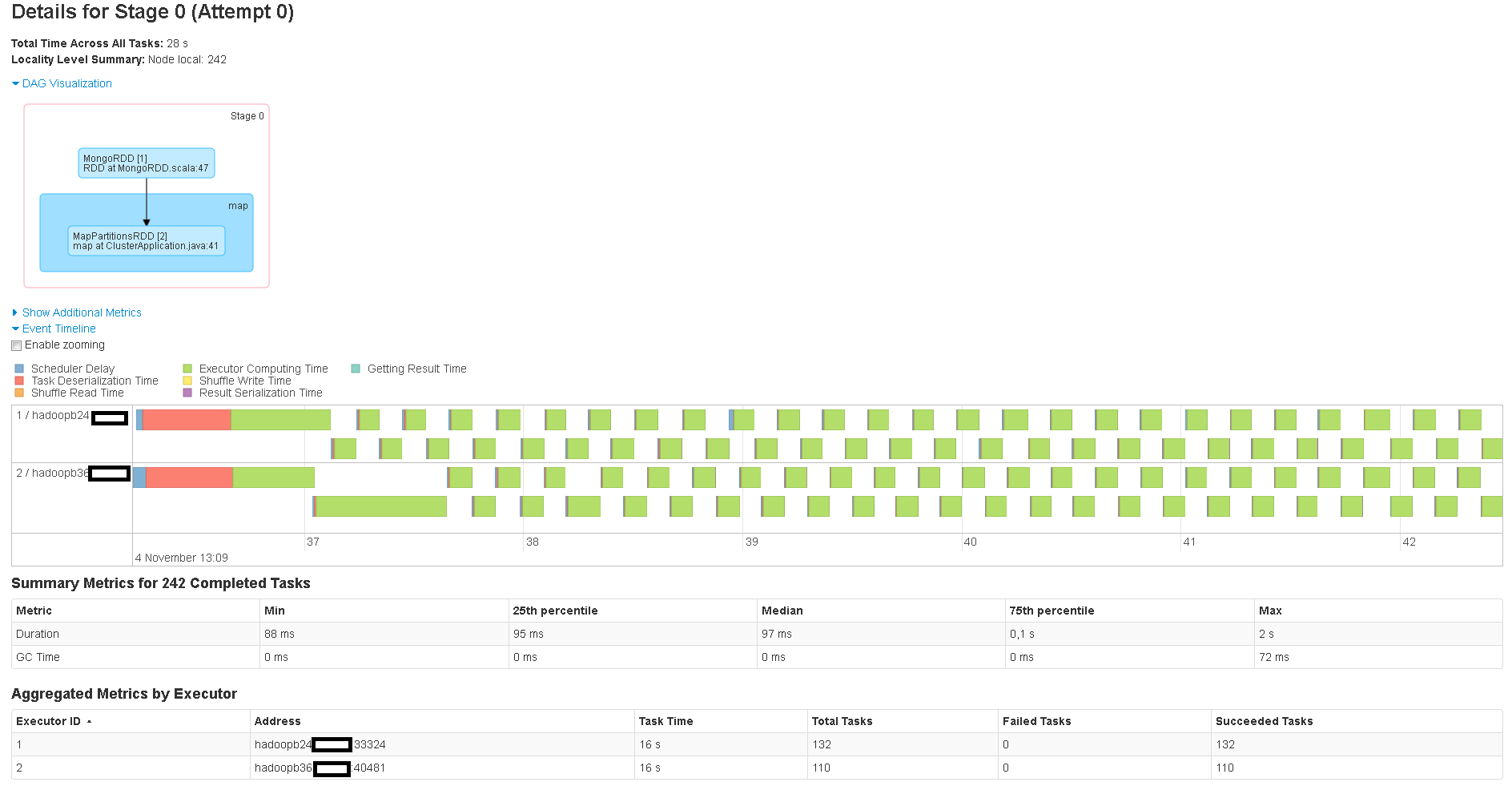
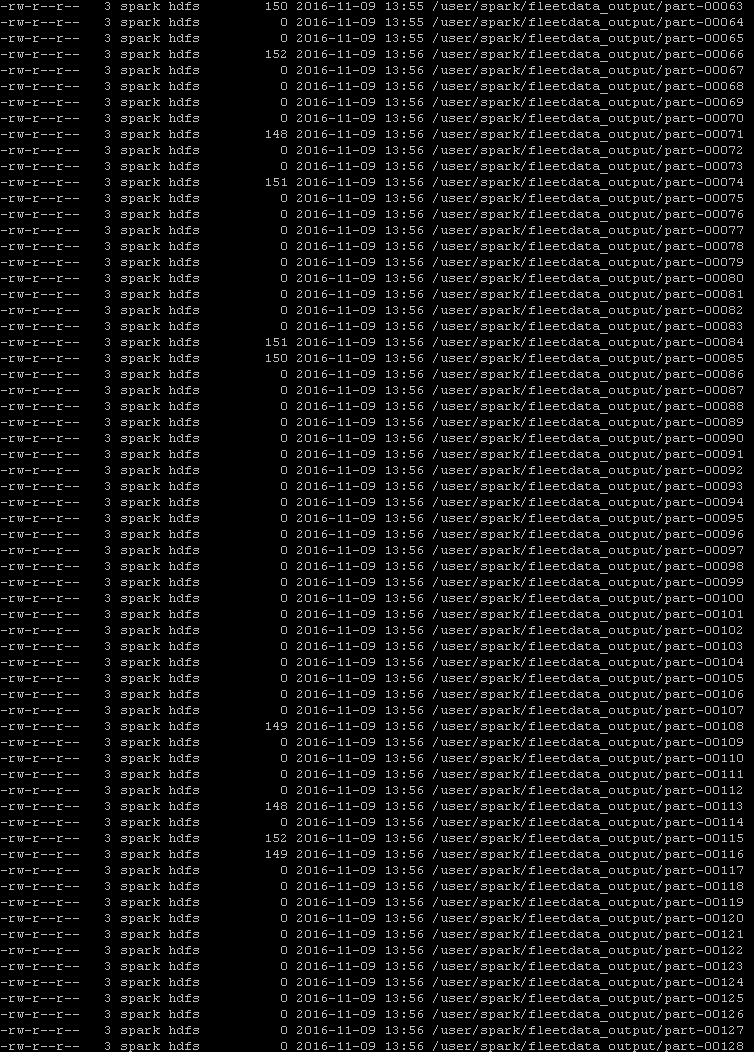
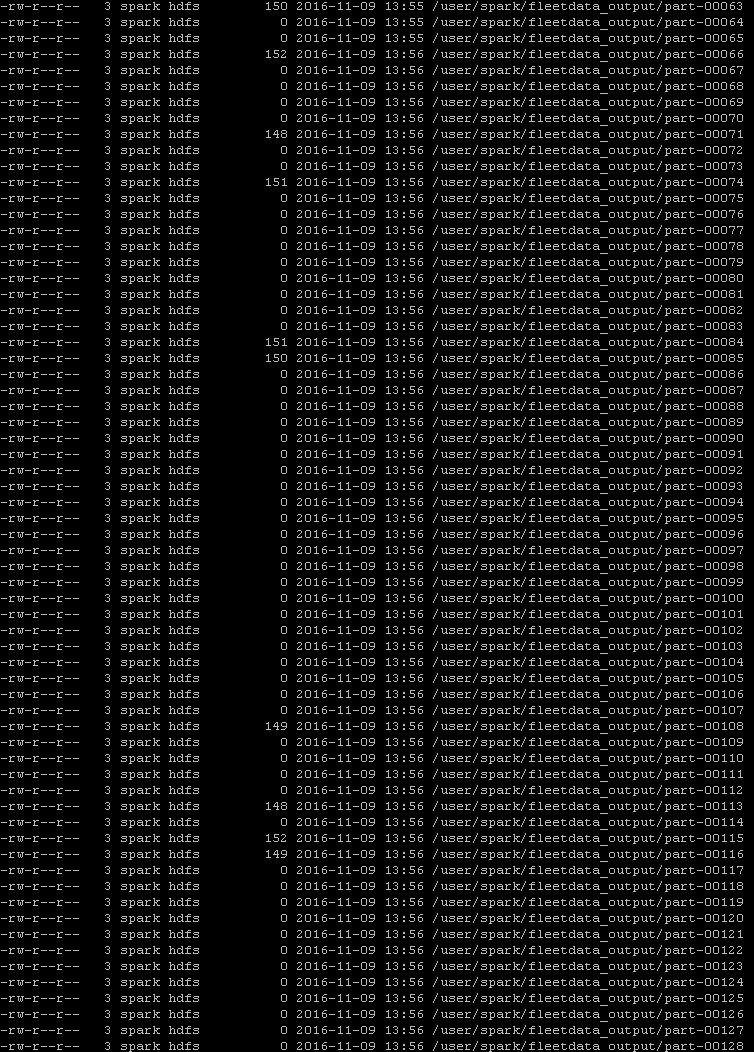
After calling saveAsTextFile on the RDD, I can see a lot of these partitions were in fact empty:
I am using the SparkConnector version 1.1.0 because we run Spark 1.6.1, but this feature is also not available for 2.0.0.
- related to
-
SPARK-101 Add support for partial collection partitioning for non sharded partitioners.
-
- Closed
-