-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Low
Low
-
None
-
Affects Version/s: None
-
Component/s: mongodump, mongorestore
-
None
-
(copied to CRM)
Steps to reproduce:
To reproduce the problem follow these steps
- Start a replica set (so we can dump the oplog)
- Create an index
db.doc.ensureIndex({accountNumberId:1}, {unique:true}) - Create an initial set of documents
for (var i = 0; i < 300000; i++) { db.doc.insert({accountNumberId:i}); }
- Start a standalone mongod to send the restore to
- Start walking through the documents removing and inserting
for (var i = 0; i < 300000; i++) { db.doc.remove({accountNumberId:i}); db.doc.insert({accountNumberId:i}); }
- While this is running start a dump and restore
mongodump --host localhost:31000 --oplog ; mongorestore -h localhost:27018 --oplogReplay --drop --directoryperdb --journal
The restore fails
dump/test/doc.bson
going into namespace [test.doc]
dropping
Progress: 514500/10544030 4% (bytes)
(... more progress removed)
Progress: 10269000/10544030 97% (bytes)
Creating index: { key: { _id: 1 }, ns: "test.doc", name: "_id_" }
Creating index: { key: { accountNumberId: 1 }, unique: true, ns: "test.doc", name: "accountNumberId_1" }
ERROR: Error creating index test.doc: 11000 err: "E11000 duplicate key error index: test.doc.$accountNumberId_1 dup key: { : 3155.0 }"
Aborted
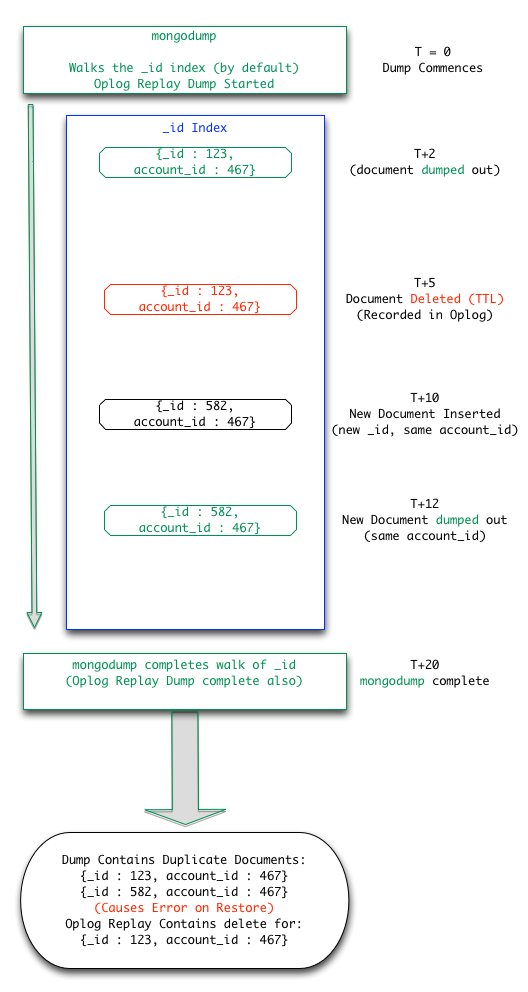
Doing a backup using mongodump --oplog and verifying the backups by running a restore --oplogReplay causes a unique key violation, either during index build or inserts/oplog-replay. This is due to the fact that multiple points in time of the unique index (not _id index which is used as the default index during backup traversal = snapshot mode) are combined during restore. In replication this happens in recovery mode which changes unique index constraints until the oplog can replay to a consistent point in time.
A reproduction does the following:
- running remove/insert with the same accountNumberId, but different docs
- running mongodump --oplog
Then:
- mongorestore --oplogReplay
Depending on if the restore is done from an empty collection (or with --drop) or not will determine where the error occurs during restore (either index will not be built correctly, or bad/wrong data will exist for documents depending on the duplicates – based on the unique index). If the index has the dropDups options then the index creation will not fail but the documents deleted may not be correct in comparison to the orig. data.
adamc put together the attached diagram.
- depends on
-
-

- Closed
-
-
-

- Closed
-
- duplicates
-
-
- Closed
-
- is duplicated by
-
-
- Closed
-
- is related to
-
-
- Closed
-
-
TOOLS-852 mongorestore --noDataRestore
-
- Low Priority
-
-
SERVER-19618 Allow applyOps to ignore unique index constraints
-
- Closed
-
- related to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- links to