-
Type:
Task
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: None
-
None
-
3
-
Iteration Firenze
-
Not Needed
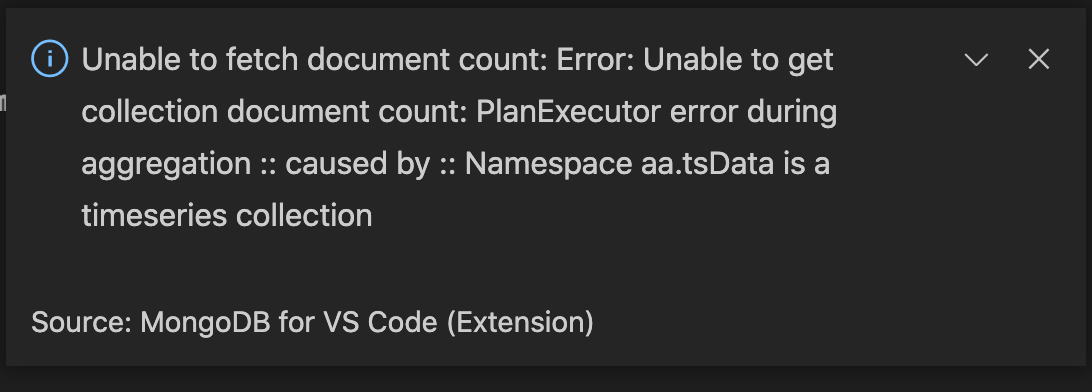
Currently we use `estimatedCount` to fetch the document count for time-series collections. Currently this fails for these collections (screenshot of error attached). We should probably just fail silently for these collections if we cannot fetch the count without doing a full scan.