WiredTiger can't use POSIX rwlocks or other system equivalents because our resources are connected to a session handle that can be passed between threads. In other words, we may lock a resource (e.g., when opening a cursor) as part of an operation in one thread, then that session can be used in a different thread when the resource is unlocked. Common read/write lock interfaces reserve the right to use thread-local storage internally (meaning the unlock has to happen in the same thread as the lock), regardless of whether all implementations need it.
Our existing rwlock implementation is subject to collapse when there is contention from many threads for a lock. There are two reasons: (1) when there is contention, threads yield and spin rather than waiting for a notification, and (2) the strict fairness in the current implementation means that there is only one thread that can enter the lock at a time, so we rely on the scheduler choosing the single "next" thread, even though all it can see are a whole lot of threads spinning.
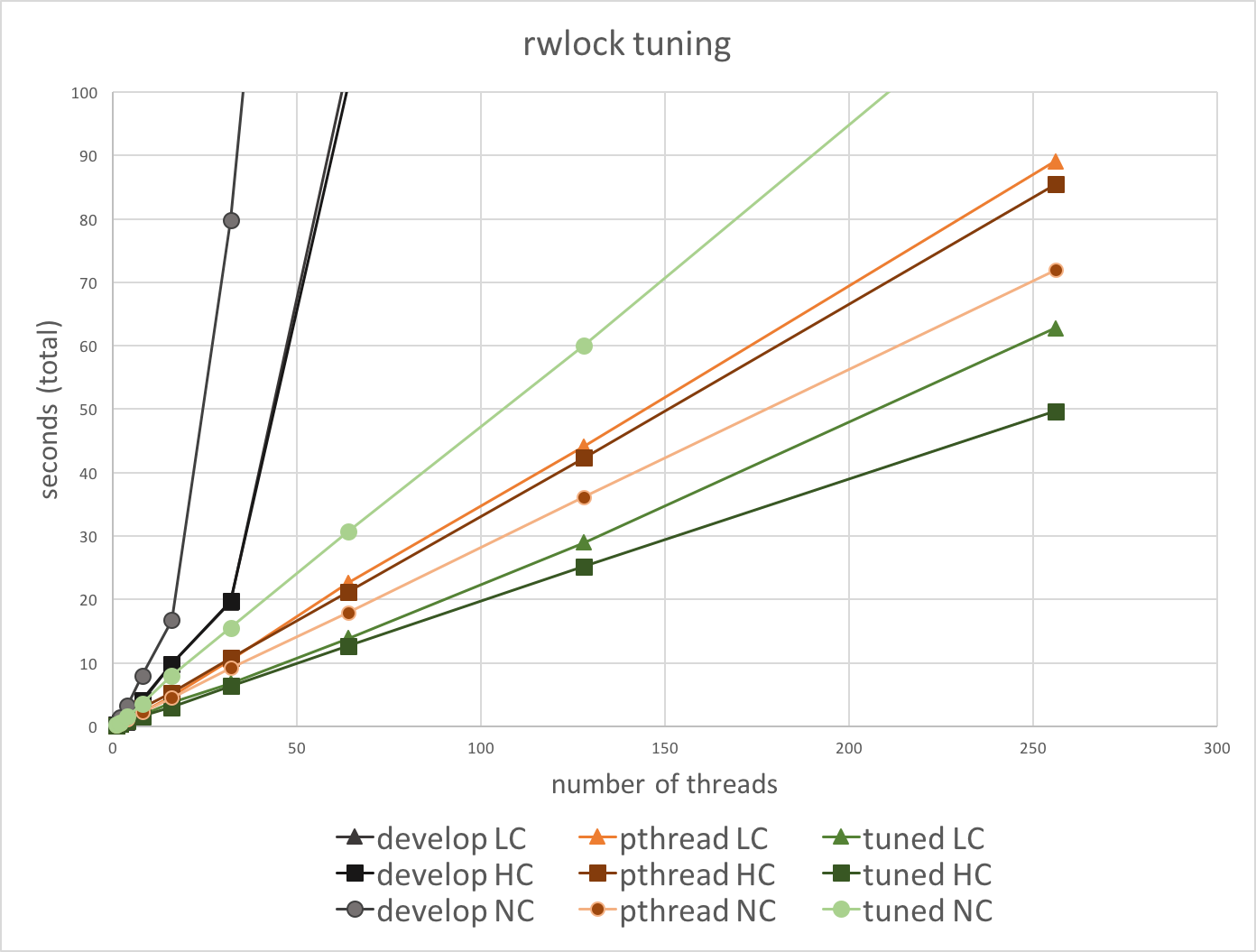
In this ticket, we added a workload to compare with POSIX rwlocks (even though we can't use the directly), and attempt to tune spinning and backoff behavior to improve scalability.
The workload is a very simple stress test of read / write locks that runs in three modes:
- NC is no contention, where all requests are read / shared locks and should never block;
- LC is low contention, where for each thread, 1 in 10K requests are for write / exclusive locks; and
- HC is high contention, where 1 in 100 requests are for write locks (so with over 100 threads, there is usually at least one write lock request active).
We compare "develop" (the existing WiredTiger implementation) with pthread rwlocks and a tuned version.



- related to
-
WT-3115 Change the dhandle lock to a read/write lock
-

- Closed
-