Summary:
WiredTiger has a number of collection and data source level statistics, these statistics are replicated WT_SLOT_COUNT times. The intention is that a different session will increment a different slot which should result in a reduced number of false or true collisions.
A true collision occurs when two threads running on different cores update the same counter and their session ids happen to hash into the same slot.
A false collision occurs when different threads are updating different statistics in the same array (if their session ids hash to the same value).
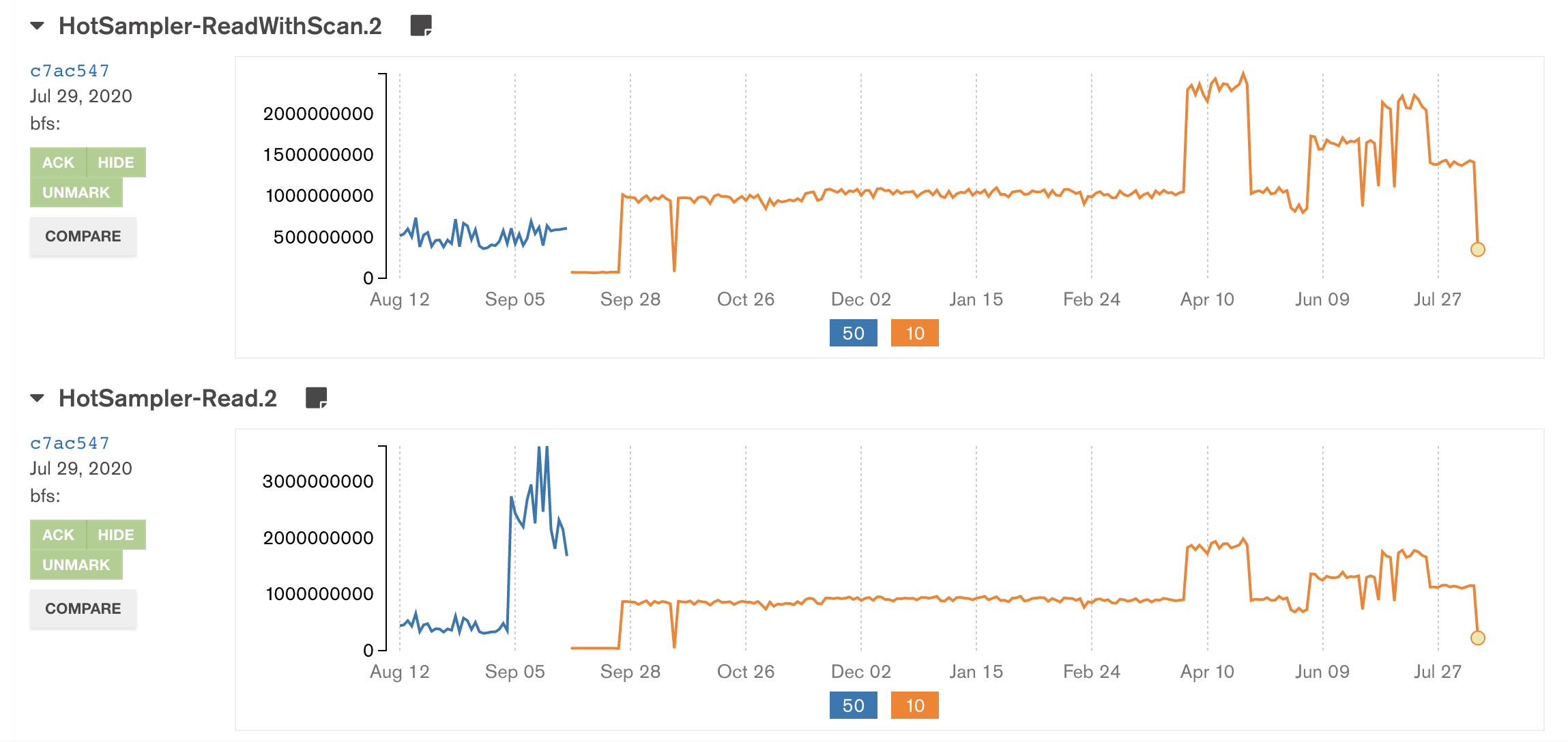
The current layout of statistics doesn't take into account the likely hood of that statistic being incremented at the same time as a statistic within its 8 statistic group. As such upon adding a statistic in WT-6444 we saw a read performance regression.
Next steps:
The next step is to call sched_getcpu() in place of using the session id per thread to see if that removes the regression seen, additionally if that doesn't fix it outright we can try incrementing the slot count. If sched_getcpu() works but ends up being not that performant its possible we can determine cpu id using a slightly faster method. e.g. linux restartable sequences.
If we do intend to increase the slot count in WiredTiger we will need to pair that with work to reduce the overall number of statistics to reduce the memory overhead.
Additionally prior to doing the sched_getcpu() I will quickly collect what session IDs are doing what to see why we are getting collisions. Certain there are only 10 genny actor threads in the workload but I suspect they're translating to 100 or so mongodb threads.
Additional solutions:
Another quick fix suggested is to randomly sort the statistics structure which would likely result in no collisions of hot statistics.
A separate solution looks at trying to define a hot statistic vs a cold statistic, a hot statistic being one that is incremented frequently. A cold statistic is one that is incremented infrequently. There are two basic ways to do this:
We can simply try to categorise them manually, this is relatively easy for a large number of statistics. However for things like eviction statistics, hot vs cold status is workload dependent so it's difficult to say which way they should be categorised. We could do data analysis across some workloads in evergreen however that isn't a priority as of yet.
Once we've categorized the statistics we can lay them out within the connection stats structure such that we reduce probability of collision, interleaving them with cold statistics, and if we don't have enough cold statistics, padding left over hot statistics.
However padding introduces a memory overhead so we'd want to avoid doing too much of that.
There was a suggestion to use perf counters to see which statistics results in cache line contention and then using that information to learn hot vs cold statistics and then separate them. However it's likely too difficult to do that at runtime without a lot of manually tooling so for now that suggestion will be put down.
Future work:
Finally a separate piece of work came out of this to reduce the overall number of statistics where possible, that work will likely not be undertaken as part of this ticket however is worth mentioning. The difficulty there is determining what makes a statistic interesting, e.g. utilized to solve a bug in the past.
Note:
This ticket is created as follow on from BF-18215, and some of the detail can be found there.