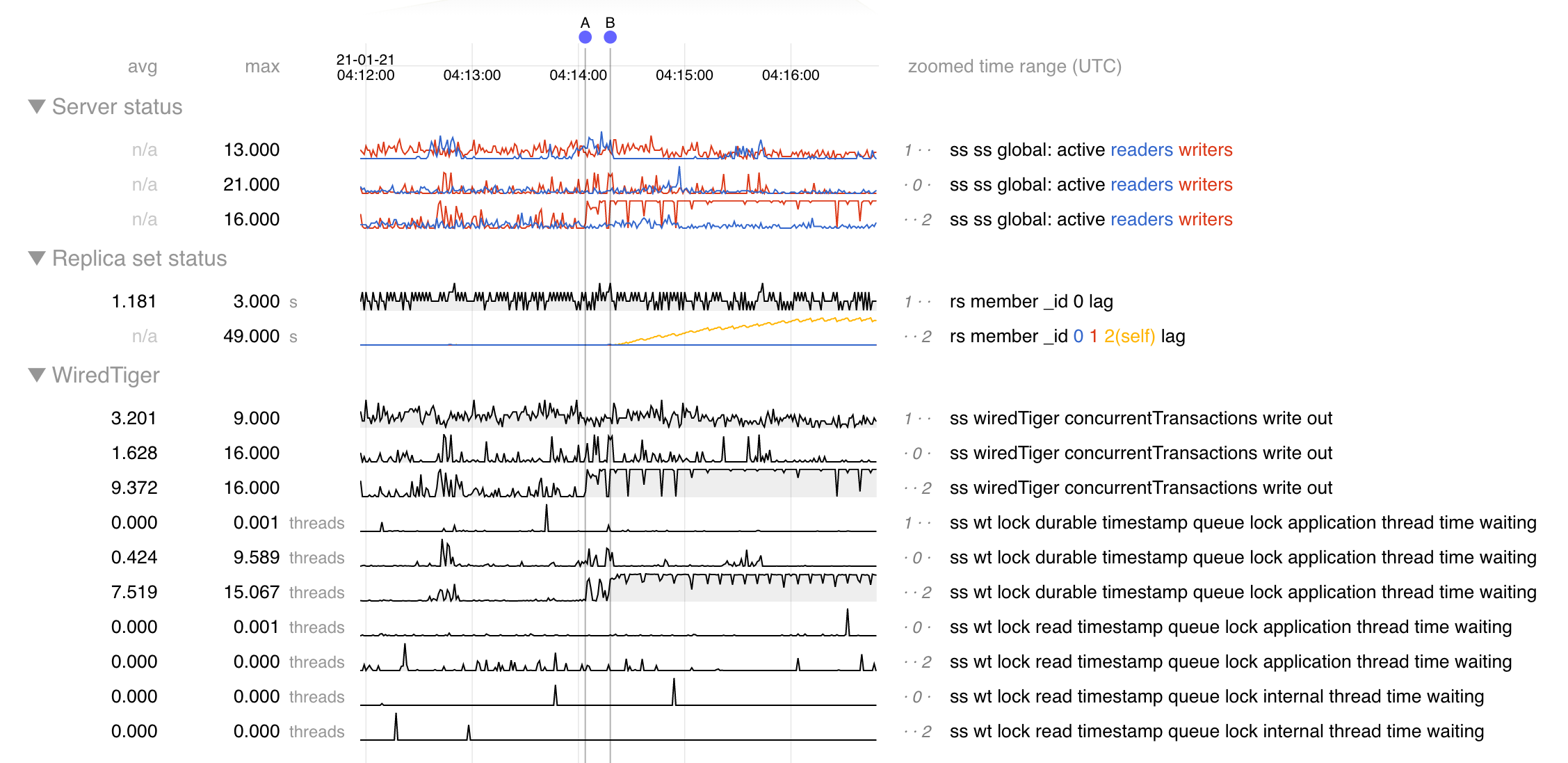
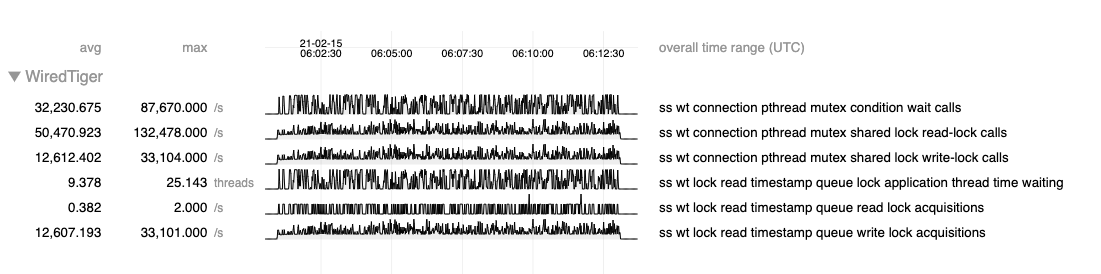
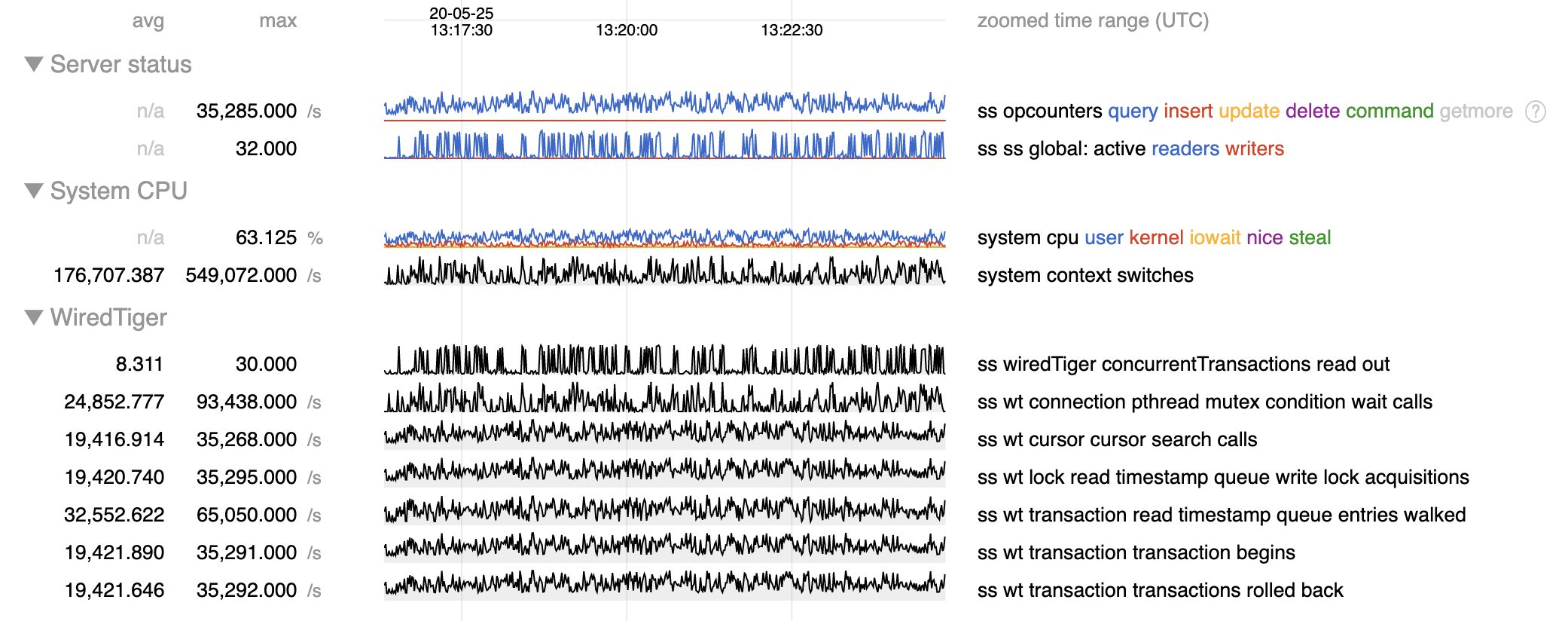
For high volumes of short-lived, timestamped reads, the global read timestamp queue does not handle excessive contention well.
From SERVER-51041:
The WT read timestamp queue leaves around old entries from inactive transactions. New readers (holding write locks on the read timestamp queue) are responsible for cleaning up old entries even if the queue has hundreds of thousands of inactive entries. This then blocks out other readers, which spin wait for a moment, then start context switching wildly. Once the queue shrinks down, thousands of new read requests come in, but the problem just repeats itself. This leads to very unpredicatable latencies and poor CPU utilization.
I would like to consider an investigation into improvements we can make into this data structure and the concurrency control around it to support high rates of read transactions. This is not necesarily a large numbers of concurrent transactions. Even with the MongoDB ticketing mechanism, the read timestamp queue can grow massively for large numbers of short-lived reads.
My suggestion:
1. Use a different data structure with non-linear lookup time like an ordered map. Read timestamps are rarely random or uniform. They cluster to many transactions reading at the same points in time. With secondary reads (lastApplied) and majority reads, thousands of transactions will all read at very similar or all the same timestamp.
New reads increment a counter for their read timestamp, and when they roll-back, they decrement a counter for that timestamp. If they are the last active reader at that timestamp, they remove the entry entirely.
2. Don't use a spinlock for this data stucture
Just removing the spinlock would be simplest way to alleviate the performance problems, but I still think the queue is problematic because it means readers can hold a mutex for an unbounded period of time.
- is related to
-
SERVER-51041 Throttle starting transactions for secondary reads
-

- Closed
-
-
SERVER-55030 Remove mutexes that serialize secondary and majority read operations
-
- Closed
-
-
-
- Closed
-
- related to
-
SERVER-55024 Complete TODO listed in WT-6709
-
- Closed
-