@michaelcahill, @agorrod, @sueloverso:
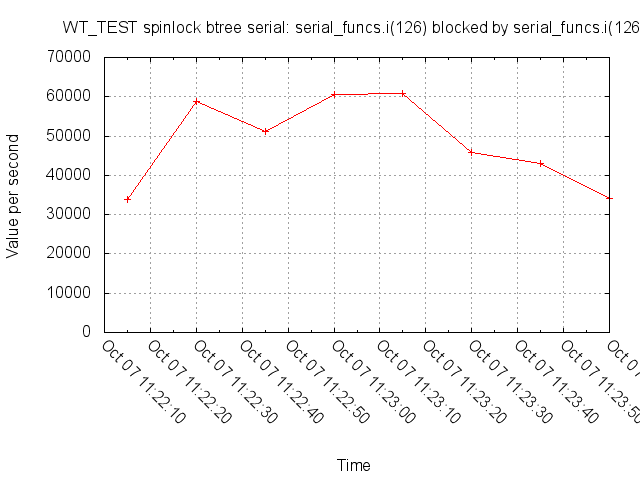
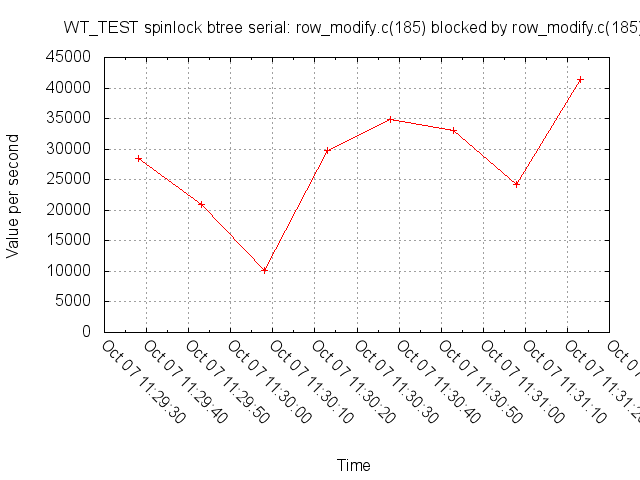
One of the things I was curious about with the mutex-logging branch was how much we were blocking ourselves in the serialization function – it turns out, there's some evidence we're doing it a fair amount. The following two graphs are wtperf, running with a modified update-lsm config:
--- a/bench/wtperf/runners/update-lsm.wtperf +++ b/bench/wtperf/runners/update-lsm.wtperf @@ -1,13 +1,13 @@ # wtperf options file: lsm with inserts/updates, in memory -conn_config="cache_size=1G" +conn_config="cache_size=500MB,statistics_log=(wait=15)" table_config="lsm_chunk_size=20MB,type=lsm" -icount=5000000 +icount=50000000 report_interval=5 checkpoint_interval=0 stat_interval=4 run_time=120 populate_threads=1 -read_threads=2 -insert_threads=2 -update_threads=2 +read_threads=6 +insert_threads=4 +update_threads=4 verbose=1
Here's the current code:

And here's a hacked up version that releases the serialization mutex more quickly:

Of course, these runs are in the spinlock logging branch, which makes things noticeably slower.
The original idea (IIRC), behind holding the serialization lock longer was two-fold:
First, we thought the various atomic instructions inside it (like updating the page and cache memory footprints) were less likely to collide if we put them inside of a bigger lock;
Second, there were some things we did that weren't atomic instructions, and some lock was required, might as well use the one we were already holding.
Over time, the second reason has gradually been eroded, there's only the first one left.
That said, just because we're no longer colliding as much on the serialization lock doesn't mean we're not now colliding all over the place on a bunch of other atomic instructions.
@sueloverso, is there a standard update- or insert-heavy test you could run before and after this branch that would tell us if shortening the length of time we hold the serialization lock translates into faster throughput?
The interesting changes:
I'm marking the page dirty after releasing the serialization spinlock.
I'm not incrementing the page's memory footprint until after releasing the serialization spinlock:
/*
* Increment in-memory footprint after releasing the mutex: that's safe
* because the structures we added cannot be discarded while visible to
* any running transaction, and we're a running transaction, which means
* there can be no corresponding delete until we complete.
*/
@michaelcahill, is that reasoning correct?
Finally, the reason I made this change off the cache-dirty-bytes branch is because it's the only branch where I trust the page/cache memory footprint behavior, which is kind of a requirement for this change. agorrod is still not yet happy with that branch, so there's a possible issue there.

- is related to
-
WT-699 Cache dirty bytes
- Closed
-
SERVER-36208 remove repairDatabase server command and shell helper
-

- Closed
-