The issue was initially reported as an unusually long load phase in py-tpcc workloads. The issue appears intermittently as a few inserts in the load phase will get stuck for more than a few hours. Related PERF and HELP tickets have more information on the history of the issue.
bruce.lucas has come up with a standalone reproducer, attached to the ticket.
Issue:
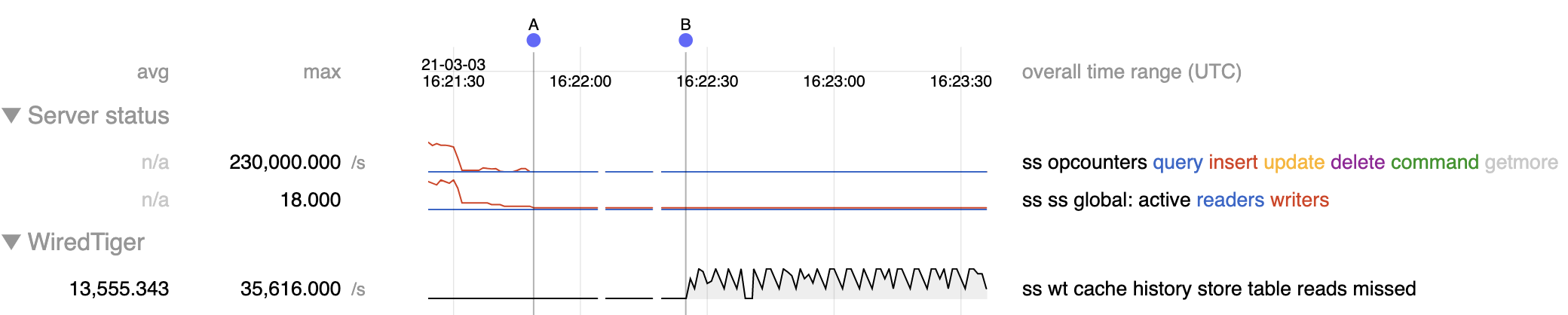
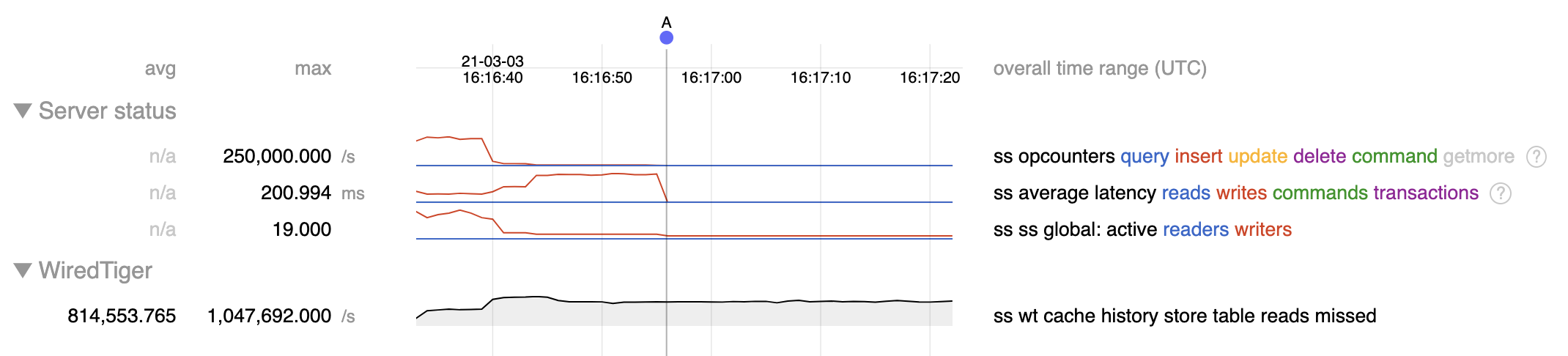
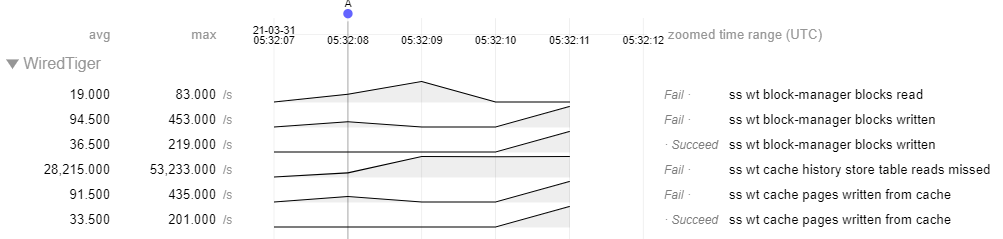
When inserting into a unique index, there is potential to get stuck repeatedly searching history store, ie calling __wt_hs_find_upd. We see a very high history store table reads missed statistic in these runs, which convey that these searches through history store are not returning anything. A callgraph that reflects this situation:

Observed behaviour with the repro script:
- Observed behaviour in 4.4 is that insert rate is erratic, and a couple of the threads typically seem to get stuck apparently indefinitely with a high rate of missed history store reads with stacks like the above.
Acceptance criterion:
- With the repro script: Expected behaviour (same as observed in 4.2) is that insert rate should be steady and each thread should complete at about the same time
- py-tpcc load phase should not get stuck
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- causes
-
SERVER-58936 Unique index constraints may not be enforced
-

- Closed
-
-
 WT-8070
Remove discrepancy between prefix_key and prefix_search
WT-8070
Remove discrepancy between prefix_key and prefix_search
-

- Closed
-
- depends on
-
WT-7912 Fix prefix search near optimisation to handle scenarios where the key range is split across pages.
-
- Closed
-
- is depended on by
-
-
- Closed
-
-
SERVER-56509 Wrap unique index insertion _keyExists call in a WT cursor reconfigure.
-
- Closed
-
- is duplicated by
-
-
- Closed
-
- is related to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- related to
-
-
- Closed
-
-
-
- Closed
-