-
Type:
Bug
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: 2.8.0-rc1
-
Component/s: Storage
-
Fully Compatible
-
ALL
-
None
-
None
-
None
-
None
-
None
-
None
-
None

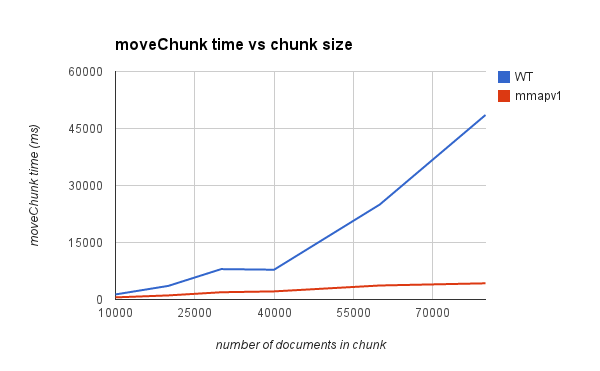
- Looks like possibly quadratic behavior.
- Logs and profile show most of the time is spent in deleting the old chunk, so this seems possibly related to
SERVER-16247andSERVER-16296, and may have to do with having to scan past deleted btree entries. However this case is a little different: the profile below shows this is related to deletes from the index, and the test is constructed so that these deletes are not from the beginning of the index btree. - The deletes also make some other operations, specifically a lookup of a non-existent _id, slow, and they remain slow after the chunk delete completes.

- Graph at top graph shows rate of repeated lookups of a non-existent _id that was continually running throughout the test.
- (1) moveChunk begins
- (2) data has been copied to other shard, now deletion begins on this shard
- the performance of the lookups of the non-existent document (top graph) begin to decline.
- (A) deleteRange is spending most of its time in __wt_btcur_next, similar to
SERVER-16296, but in this case inside IndexCursor::locate. - (B) the lookups of the non-existent _id increasingly also spend their time in __wt_btcur_next as those lookups get slow, also inside IndexCursor::locate.
- (3) the deletions have finished, but the performance of the lookups (top graph) remains low.
Instructions to reproduce:
Start mongod/mongos:
mongod --dbpath ./s0r0 --logpath ./s0r0.log --logappend --port 30000 --storageEngine wiredtiger --fork mongod --dbpath ./s1r0 --logpath ./s1r0.log --logappend --port 31000 --storageEngine wiredtiger --fork mongod --configsvr --dbpath db/c --logpath db/c.log --logappend --fork mongos --port 27017 --configdb localhost --logpath db/ms0.log --logappend --noAutoSplit --fork
Set up:
sh.addShard('localhost:30000') sh.addShard('localhost:31000') // turn on sharding for collection test.c printjson(['enableSharding', sh.enableSharding('test')]) printjson(['shardCollection', sh.shardCollection('test.c', {_id: 1})]) // we'll do the chunk moving manually printjson(['setBalancerState', sh.setBalancerState(false)]) // manually create two chunks: _id<0 and _id>=0 printjson(['split', db.adminCommand({split: 'test.c', middle: {_id:0}})])
Start an asynchronous thread continuously searching for non-existing document with _id:-5. This will get slower once the deletes for the chunk move start.
function find() {
every = 1000
var t = new Date()
for (var i=0; ; i++) {
db.c.find({_id:-5}).count() // search for a non-existent document
if (i%every==0 && i>0) {
var tt = new Date()
print(new Date(), 'find', i, Math.floor(every / (tt-t) * 1000))
t = tt
}
}
}
Here's the main part of the test. Insert one document into chunk _id<0, and lots of documents in chunk _id>=0, then move the large chunk from shard0000, where it starts out, to shard0001. By inserting a document with _id:-10 we ensure that the deletes of the chunk _id>=0 when we move it are not from the beginning of the _id index (nor from the beginning of the collection). Profile above was obtained with count of 70000.
function test(count) {
// insert one document in chunk _id<0
// this ensures deletes when we move the other chunk below
// are not from beginning of _id index, nor beginning of collection
db.c.insert({_id:-10})
// insert lots of documents in chunk _id>=0
print('=== chunk insert')
every = 10000
var t = new Date()
for (var i=0; i<count; ) {
var bulk = db.c.initializeUnorderedBulkOp();
for (var j=0; j<every && i<count; j++, i++)
bulk.insert({_id:i})
bulk.execute();
tt = new Date()
print(new Date(), 'insert', i, Math.floor(every / (tt-t) * 1000))
t = tt
}
info('test.c')
// move the chunk _id>0 now from shard0000 (where it starts out) to shard0001
print('=== chunk move')
printjson(db.adminCommand({moveChunk:'test.c', find:{_id:0}, to:'shard0001', _waitForDelete:true}))
info('test.c')
}
function info(ns) {
db.getSiblingDB("config").chunks.find({"ns" : ns}).sort({min:1}).forEach(function (chunk) {
var db1 = db.getSiblingDB(chunk.ns.split(".")[0])
var key = db.getSiblingDB("config").collections.findOne({_id:chunk.ns}).key
var size = db1.runCommand({datasize:chunk.ns, keyPattern:key, min:chunk.min, max:chunk.max, estimate:true});
print('id', chunk._id, 'shard', chunk.shard, 'min', chunk.min._id, 'max', chunk.max._id, 'size', size.size, 'objects', size.numObjects)
})
}

- related to
-
-
- Closed
-
-
-
- Closed
-