-
Type:
Bug
-
Resolution: Duplicate
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.0.7, 3.2.0
-
Component/s: Replication, WiredTiger
-
None
-
Storage Execution
-
Fully Compatible
-
ALL
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
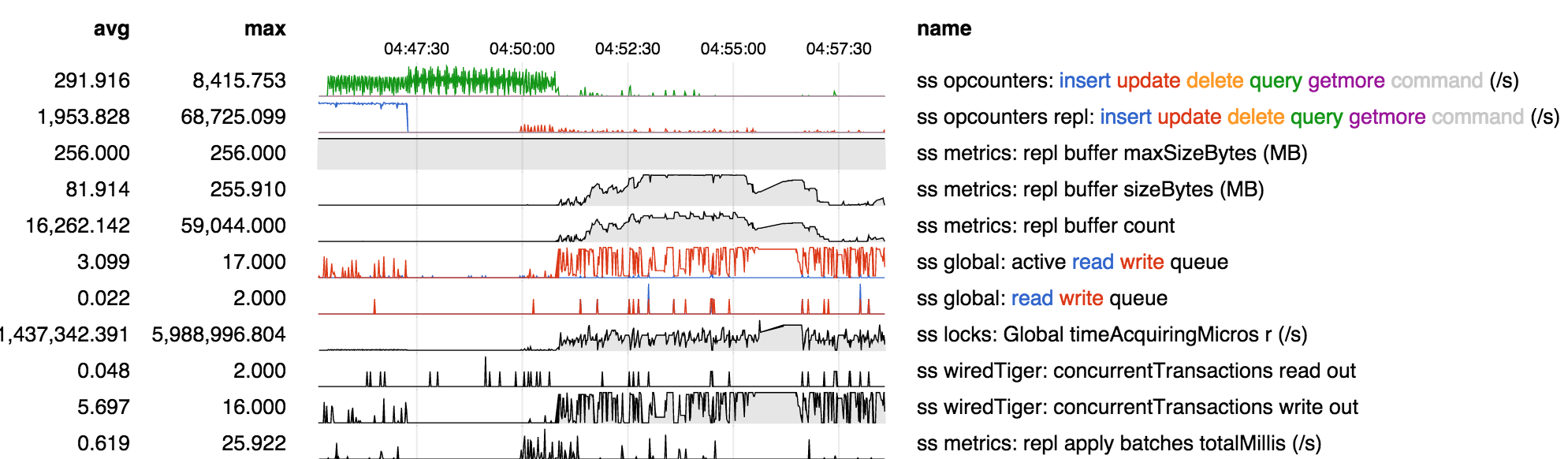
Under an update only workload on the primary it is possible to starve out readers on a secondary and cause large replication delays.
Workload:
On Primary:
- 1000 small updates (integer sets, increments and an unset)
- 10 massive (500kb) updates
On Secondary:
- 10000 findOne's
- duplicates
-
SERVER-20328 Allow secondary reads while applying oplog entries
-
- Closed
-
- is related to
-
-

- Closed
-
-
SERVER-18983 Process oplog inserts, and applying, on the secondary in parallel
-
- Closed
-
-
SERVER-31359 when large inserts into mongo, lots of global lock occur
-
- Closed
-