-
Type:
Improvement
-
Resolution: Done
-
Priority:
 Major - P3
Major - P3
-
Affects Version/s: None
-
Component/s: Aggregation Framework
-
None
-
Fully Compatible
-
Query 2018-01-29, Query 2018-02-12, Query 2018-02-26, Query 2018-03-12
-
(copied to CRM)
-
0
-
None
-
None
-
None
-
None
-
None
-
None
-
None
In the case of an aggregation framework query the first batch of results asked from the mergerPart to the shards are done asynchronously, however when it needs to get a second batch to fullfill the query it is virtually mono-threaded as the call to getNext is synchronous.
I think it would be good to be able to overcome this limitation and make all subsequent fetches to be done in the background.
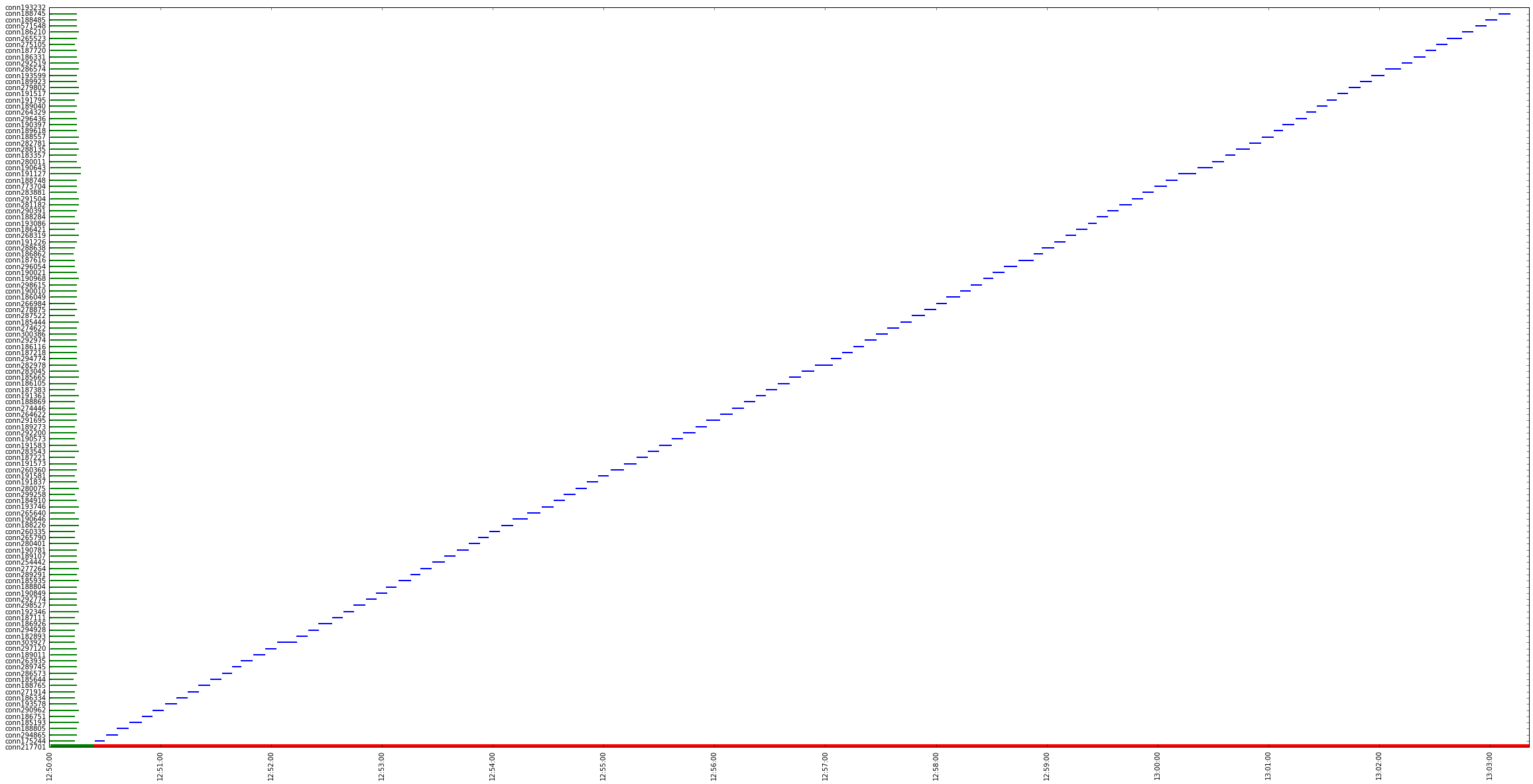
You can see here (https://github.com/ahom/jupyter-notebooks/blob/master/mongo_cs32044/notebook.ipynb) a representation of this behavior.
On the Y axis are the shards, on the X axis is the time. Starting from second batch seems is completely synchronous.
Cheers,
Antoine
- depends on
-
SERVER-33660 Once getMores include lsid, sharded aggregations with $mergeCursors can hang
-
- Closed
-
-
SERVER-32307 Make AsyncResultsMerger kill sequence issue killCursors without waiting for outstanding batches
-
- Closed
-
- is depended on by
-
-
- Closed
-
-
-
- Closed
-
- is duplicated by
-
-
- Closed
-
- related to
-
-
- Closed
-