-
Type:
Bug
-
Resolution: Gone away
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: 3.6.13
-
Component/s: None
-
None
-
Fully Compatible
-
ALL
-
(copied to CRM)
-
None
-
None
-
None
-
None
-
None
-
None
-
None
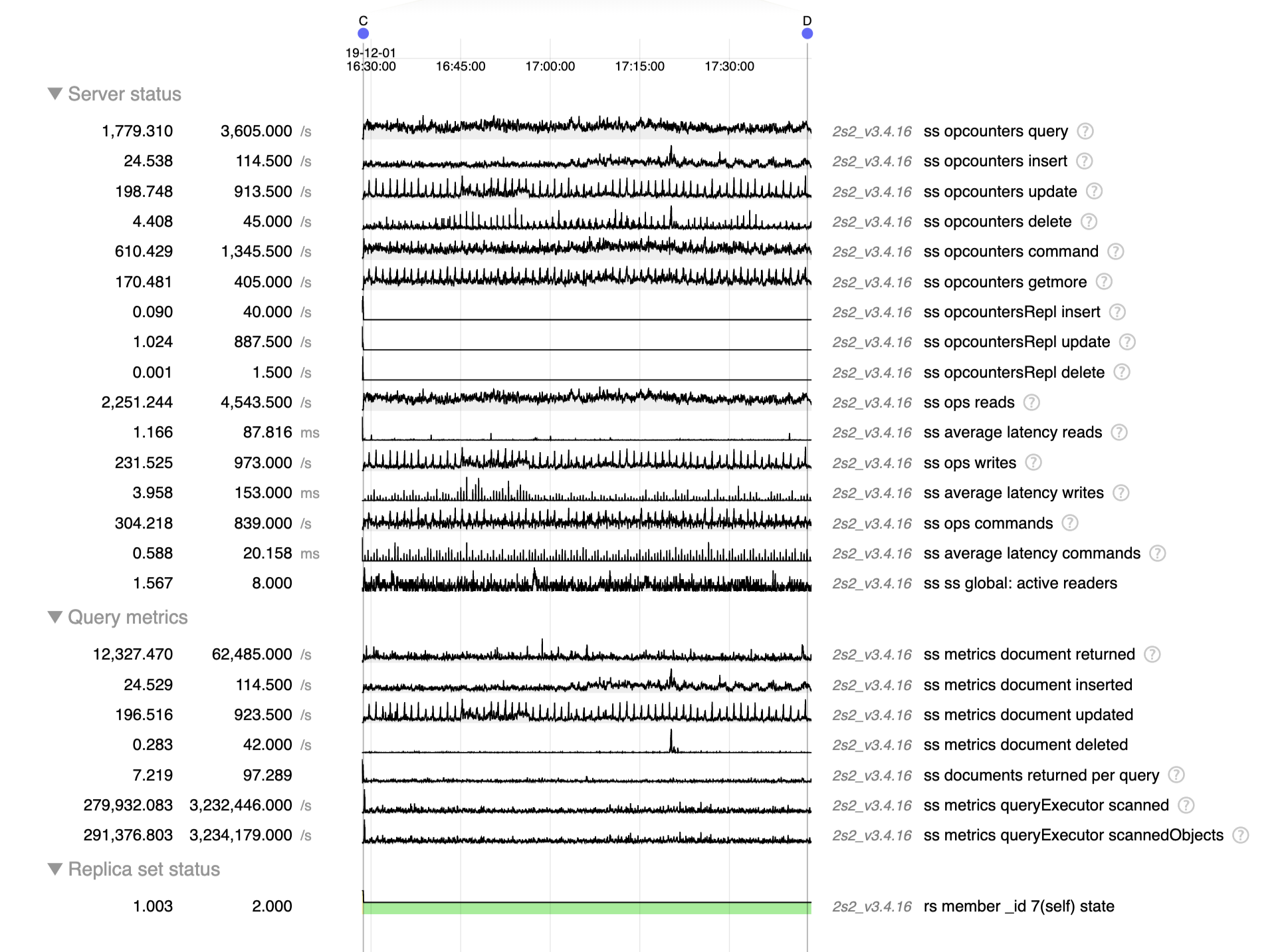
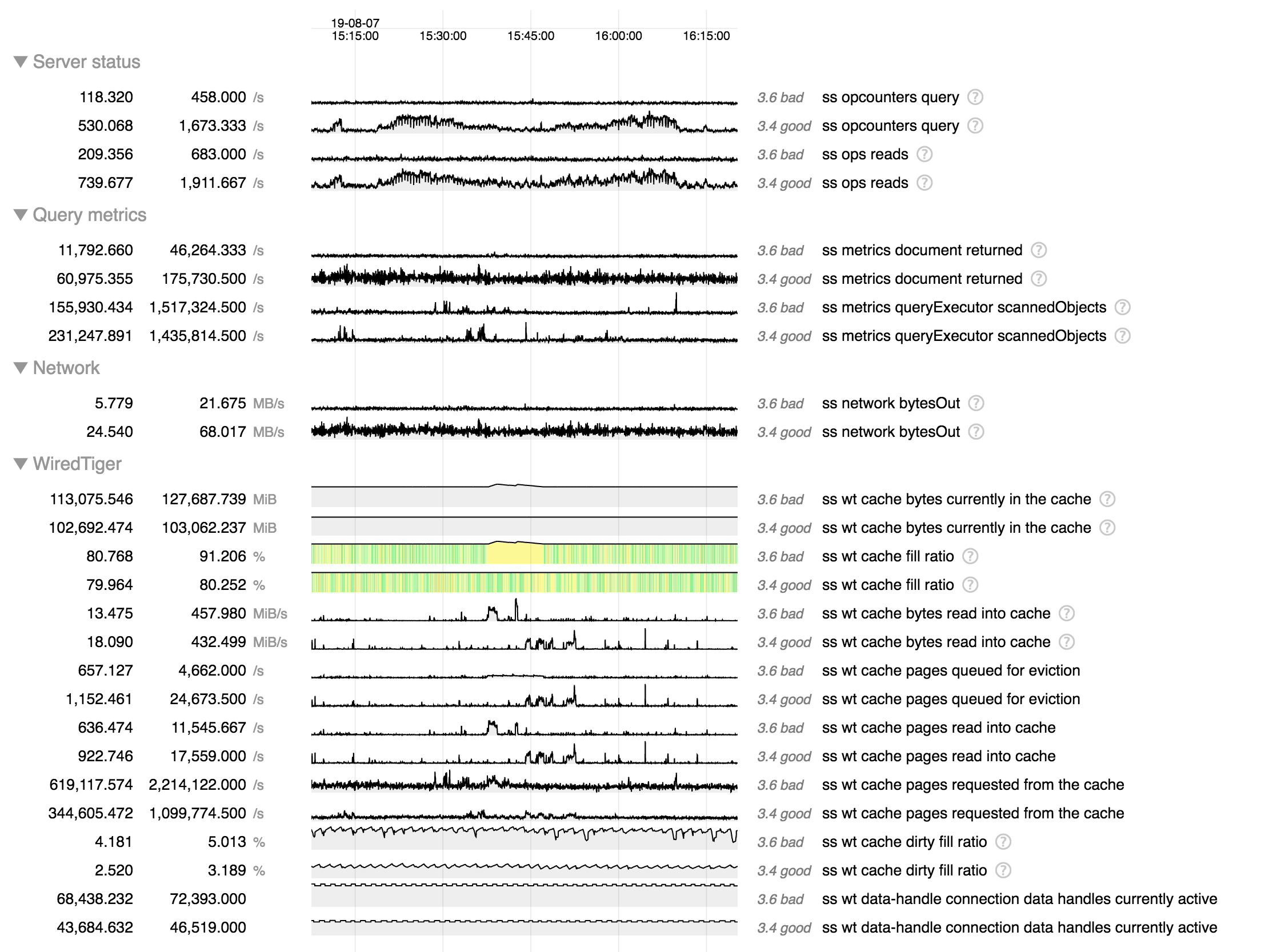
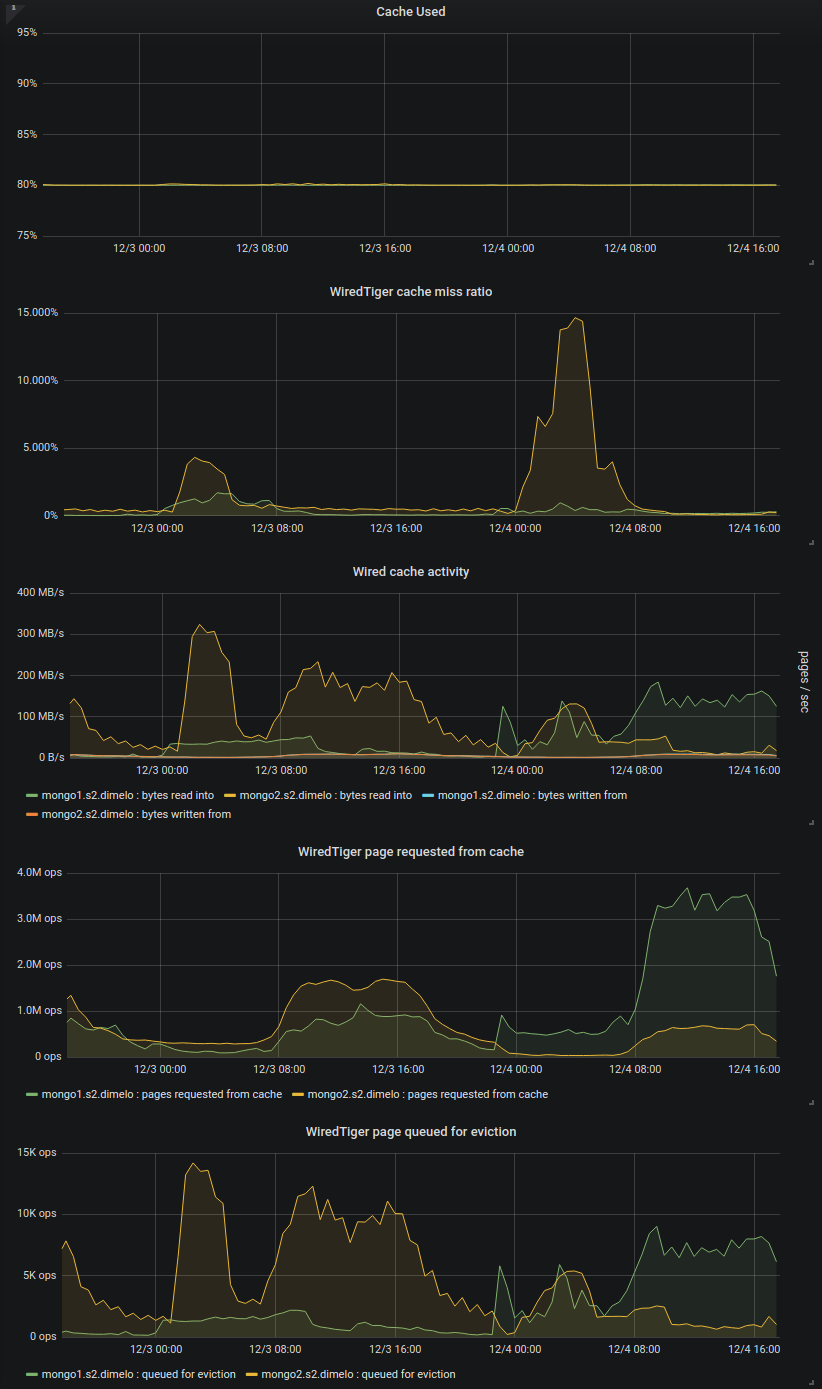
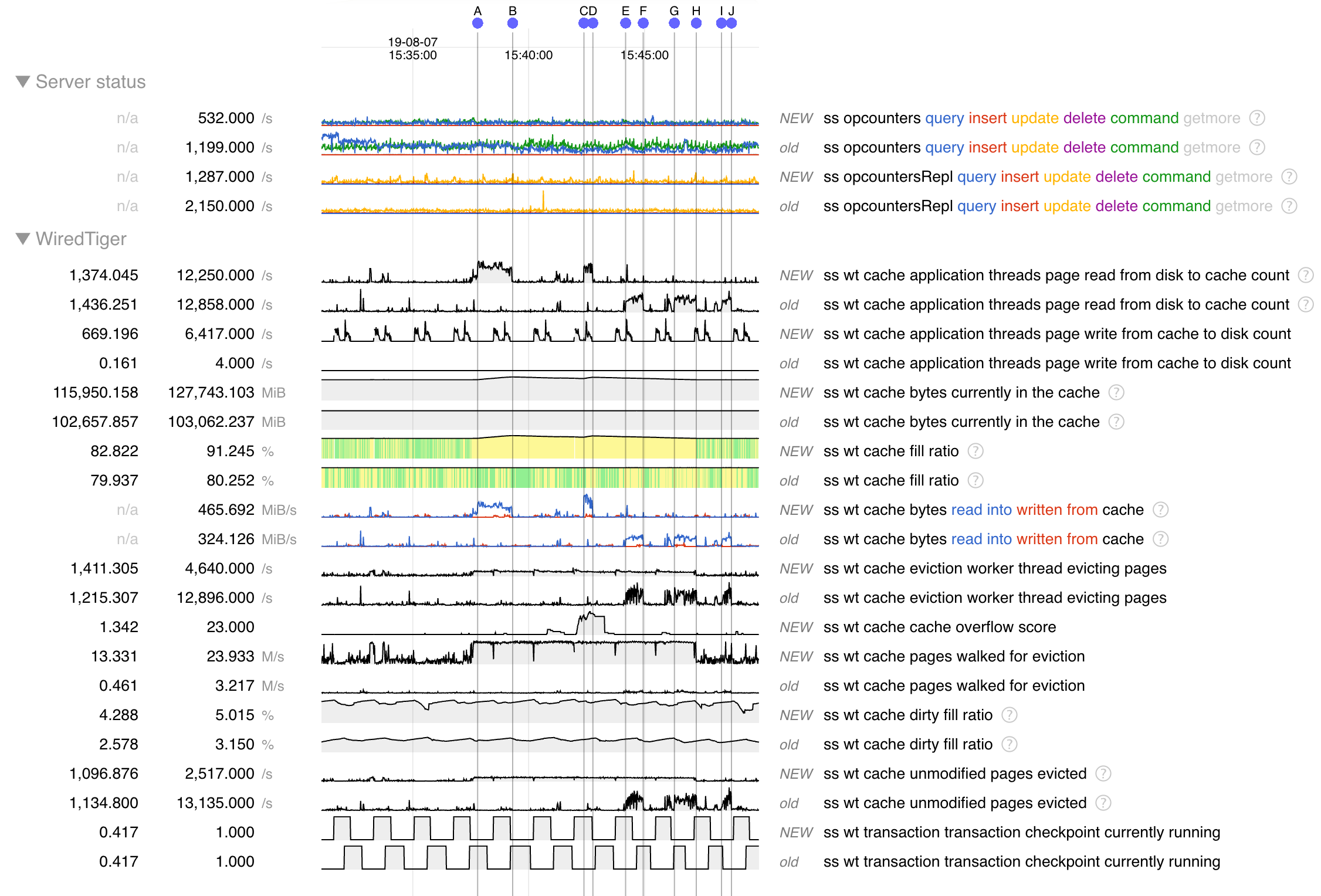
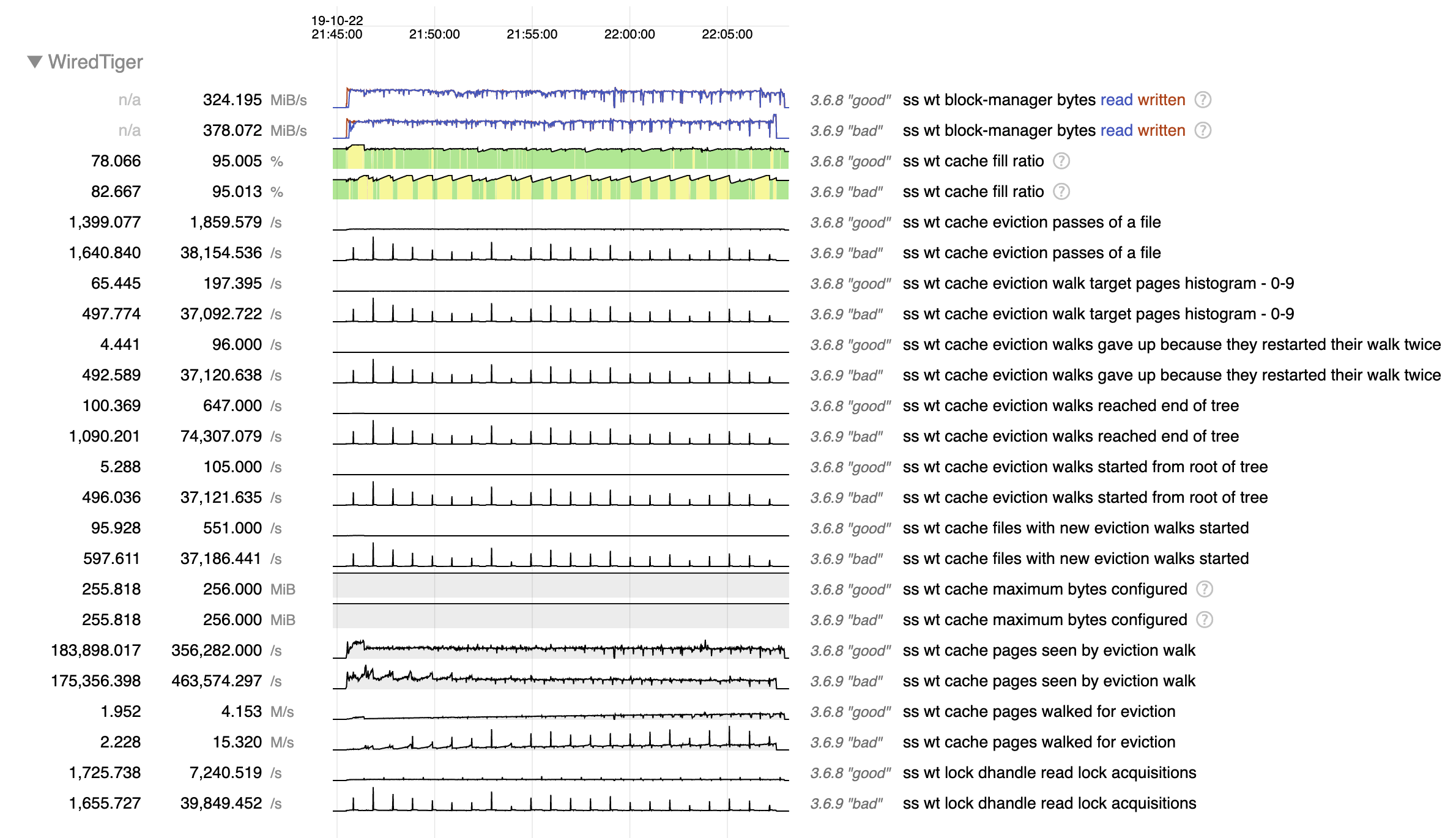
While investigating SERVER-42256 we tried 3.6.13 as suggested (only secondary for now) and so far we noticed some memory leak (SERVER-42662) and some huge cache eviction server performance regression (we think).
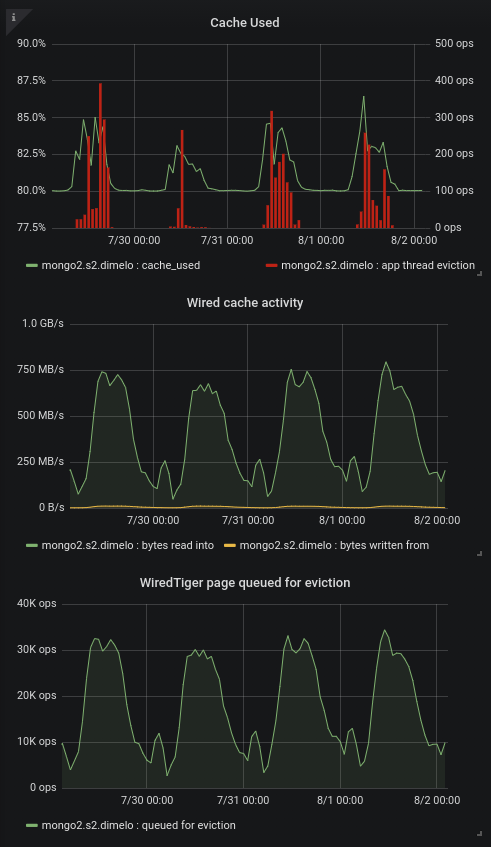
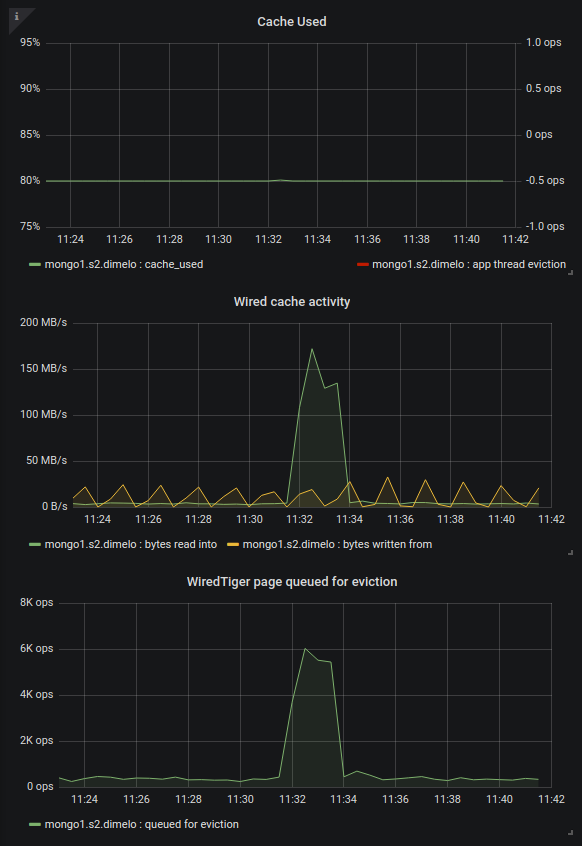
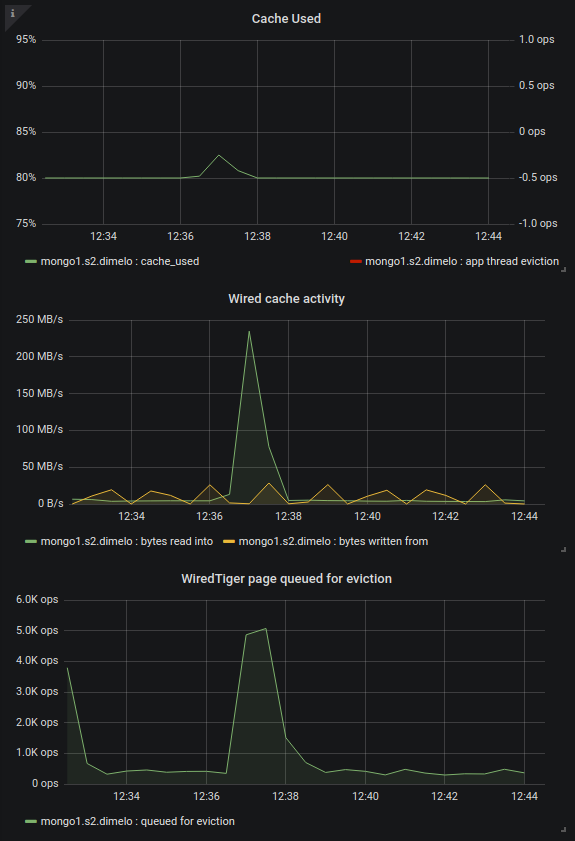
We added some charts to our monitoring about this since we're hitting the limits of the eviction server (the single threaded one filling the queue apparently). On one of our primary in 3.4.13 we regularly hit 30k+ page queued for eviction per second, and at this point it's pretty much saturated and can't fill up the queue any more, increasing cache usage to 95% and generating app thread evictions (this is SERVER-42256):
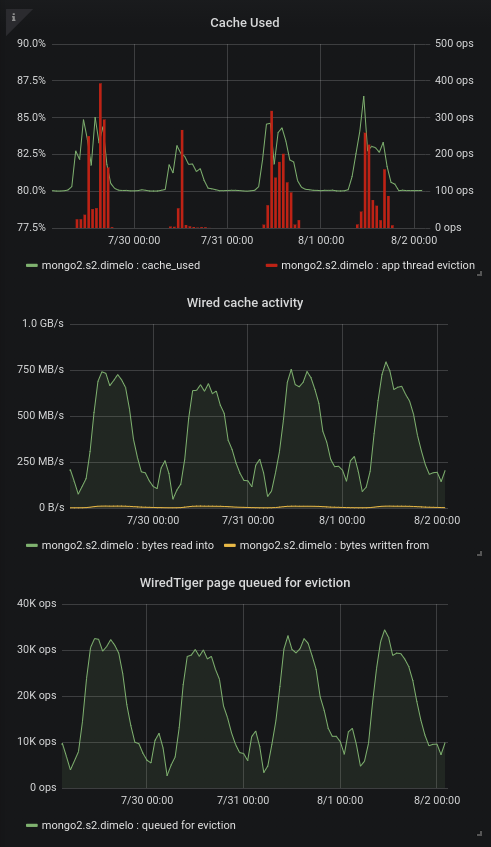
So then we put a secondary on 3.6.13, nothing bad so far except that we already see some big cache used spikes with almost no traffic (only mongodump) as mentioned in https://jira.mongodb.org/browse/SERVER-42256?focusedCommentId=2354831&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-2354831
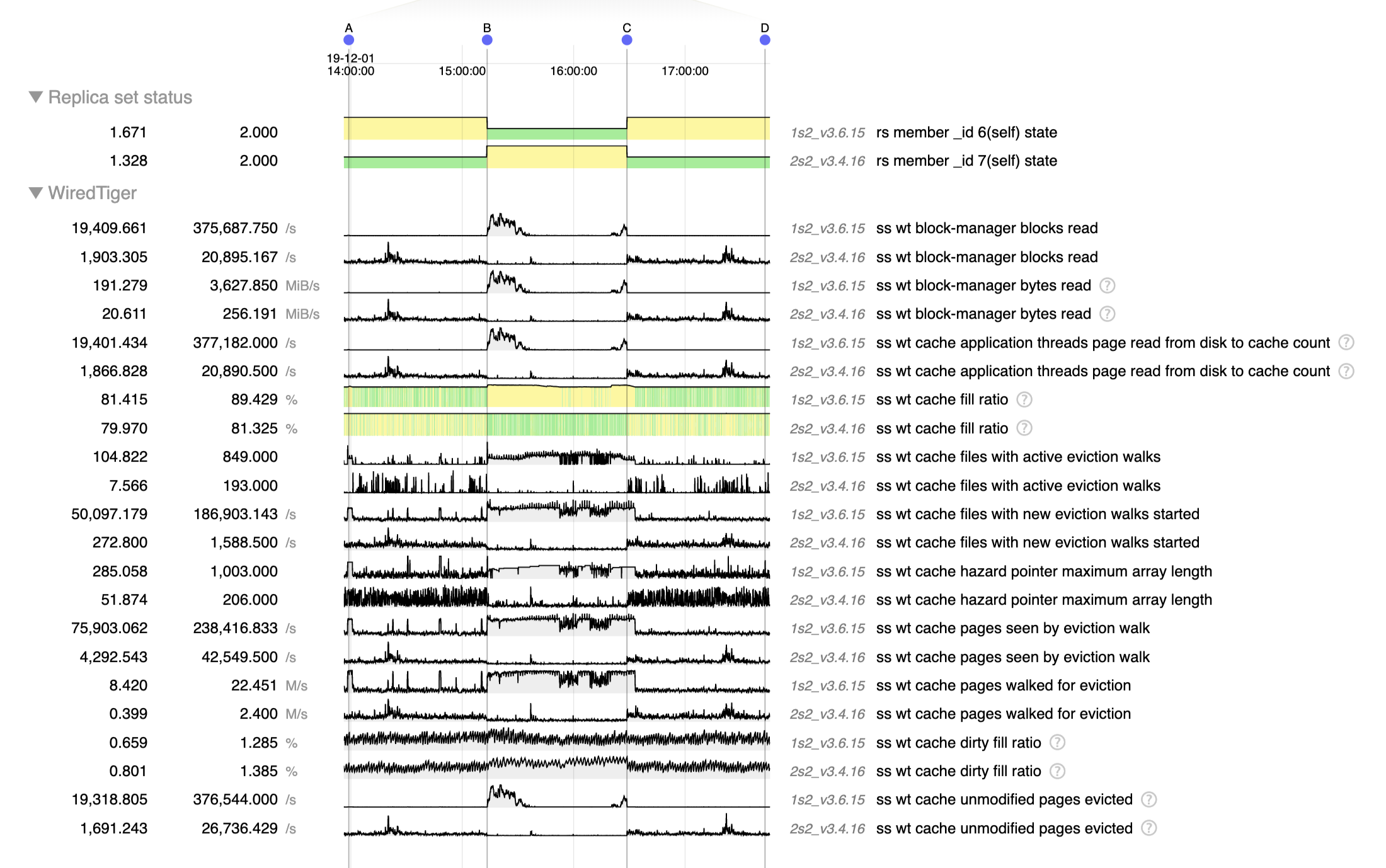
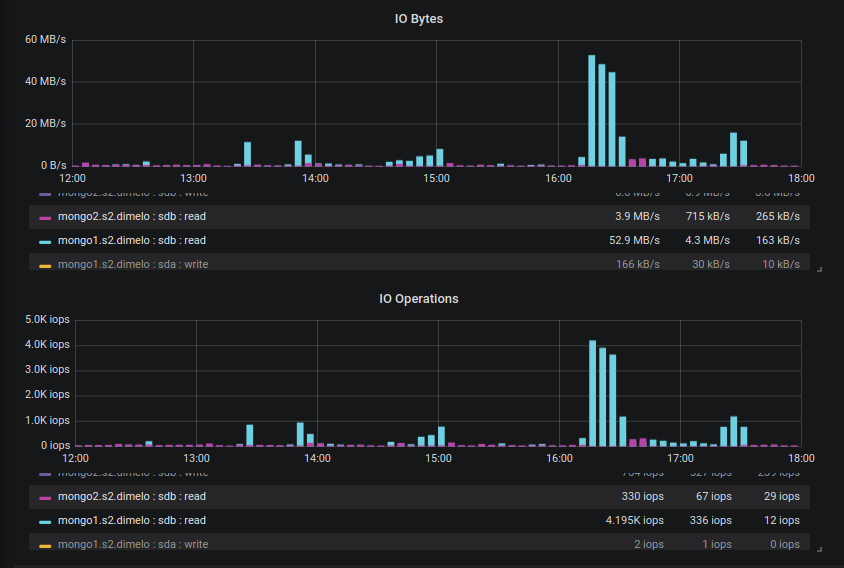
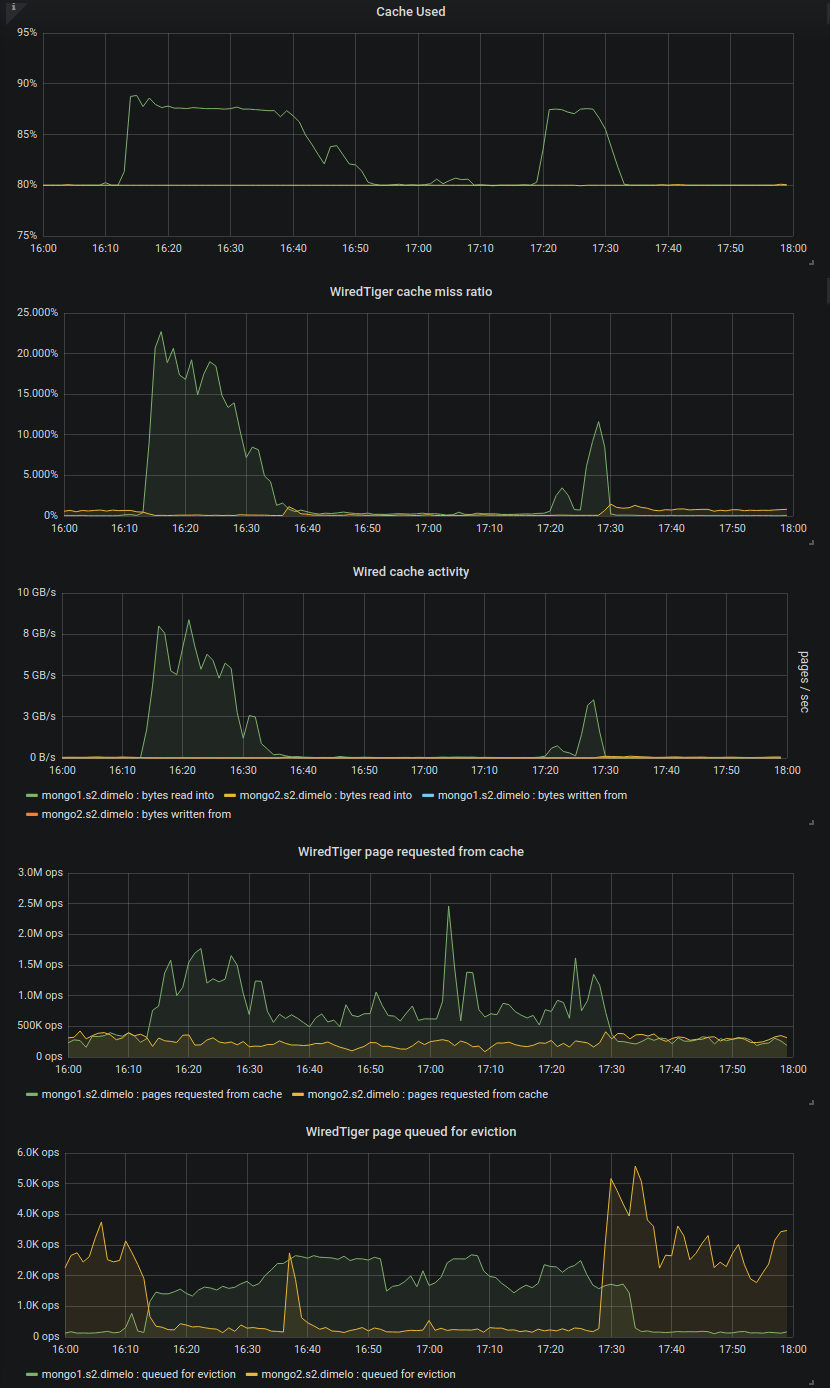
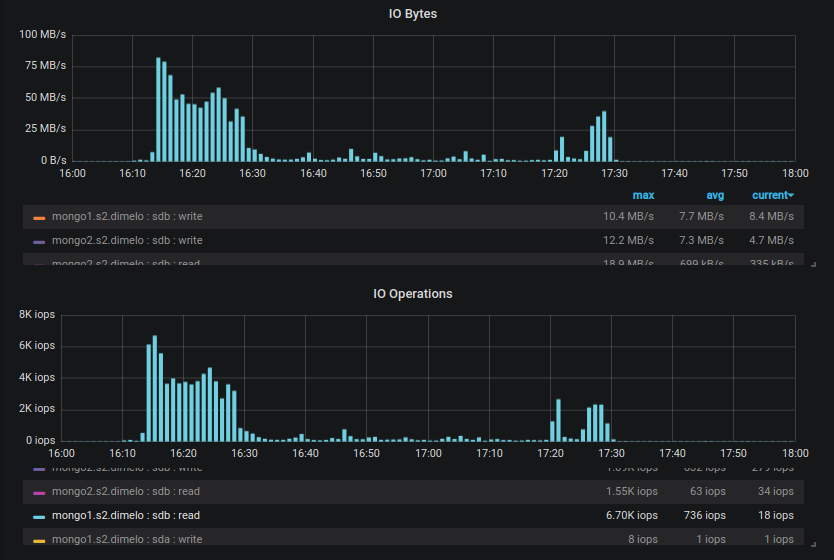
But then more recently we started creating new indexes on our 2 RS (one is 3.4.16 only, and the other has the secondary on 3.6.13) and that's when the disaster came in, basically the 3.6.13 secondary was queuing page for eviction more than 10 times slower than that (looks capped at 3k pages/sec) even though the pressure generated by the index creation is bigger, meaning 95+ cache use pretty quickly whereas the 3.4.16 secondary was performing correctly.
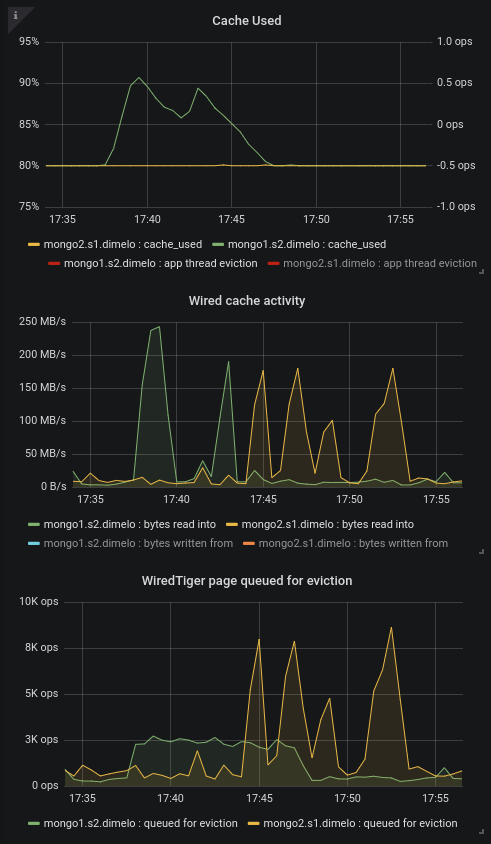
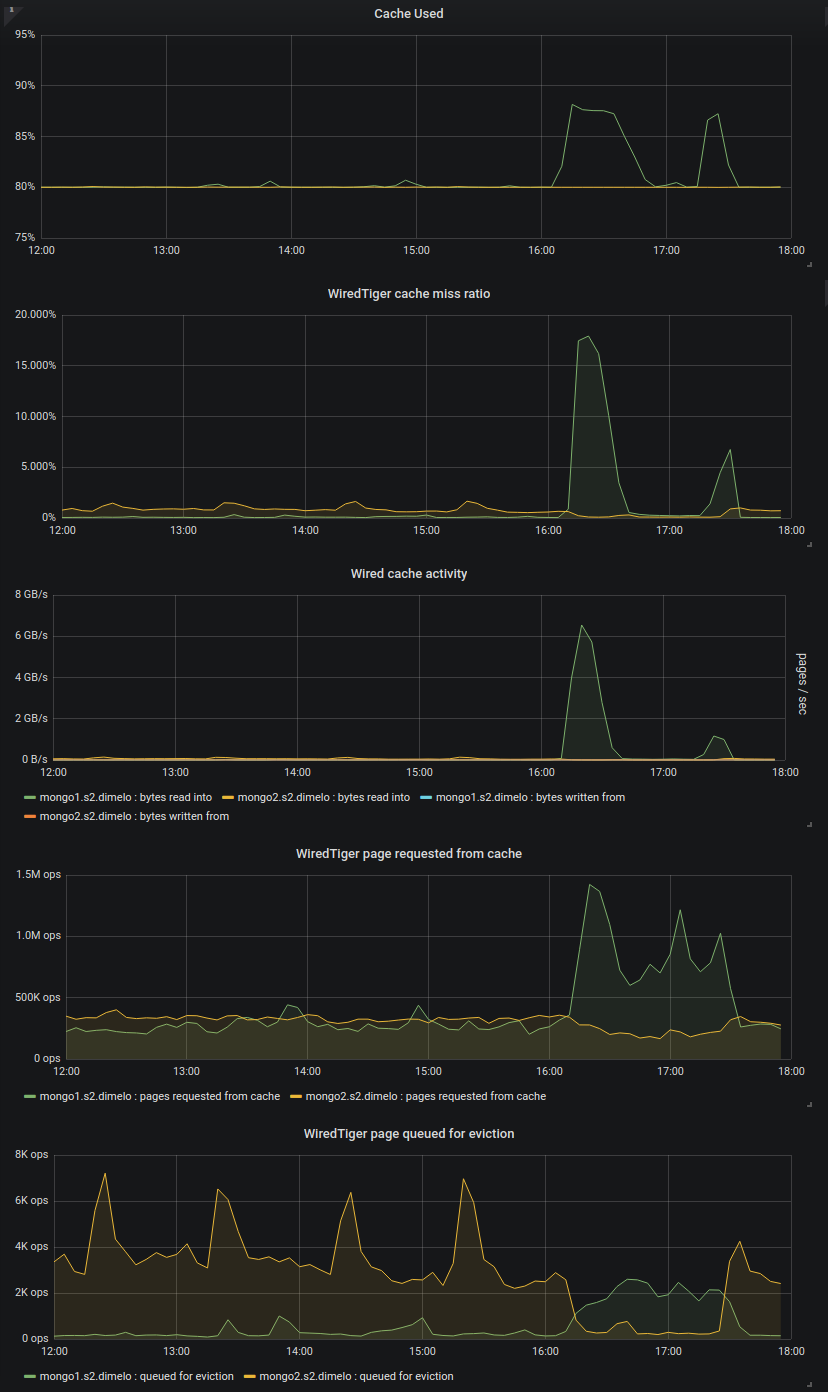
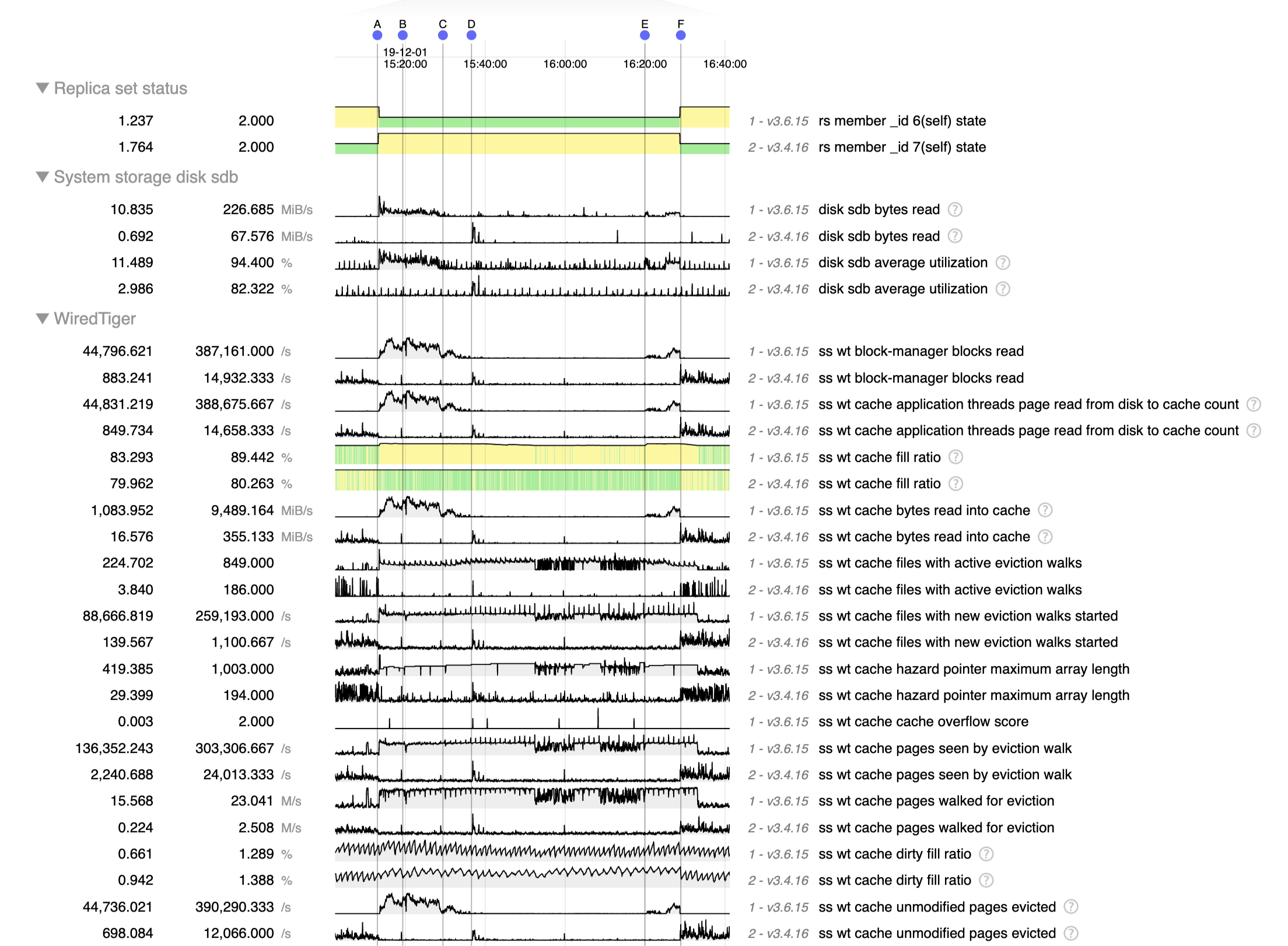
We can see this well on this chart where we tried creating a couple indexes one by one on 1 RS then the other:
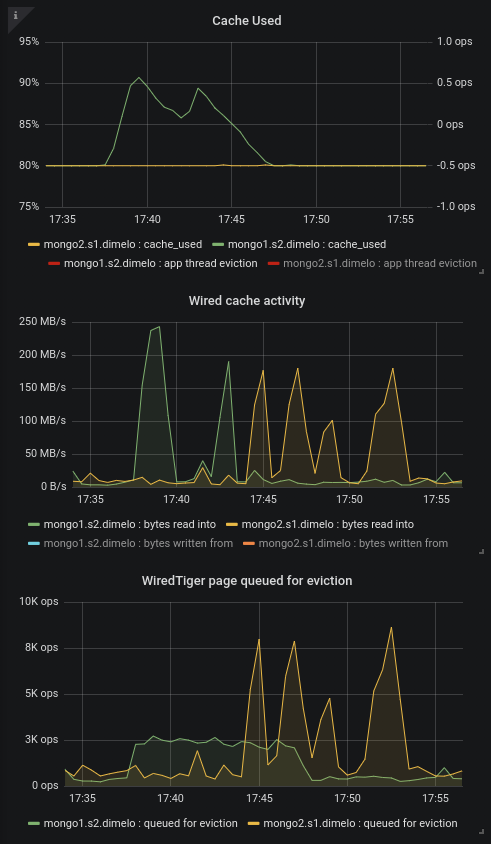
Here we can see in green the 3.6.13 secondary and in yellow the 3.4.16 secondary.
At 17:43 and 17:45 for example we created 2 identical index on similar collections, generating approximately the same pressure on the cache (in MB/s read), and we can see that 3.4.13 managed to queue pages for eviction at the same speed and thus keep the cache at 80% without trouble, whereas the 3.6.13 server looks capped at ~3k page/sec and this evict much slower than the cache fills up.
This clearly looks like a huge performance regression to me, and it also mean we can't even risk putting 3.6.13 in production as it'll probably die the second we do it don't you think?
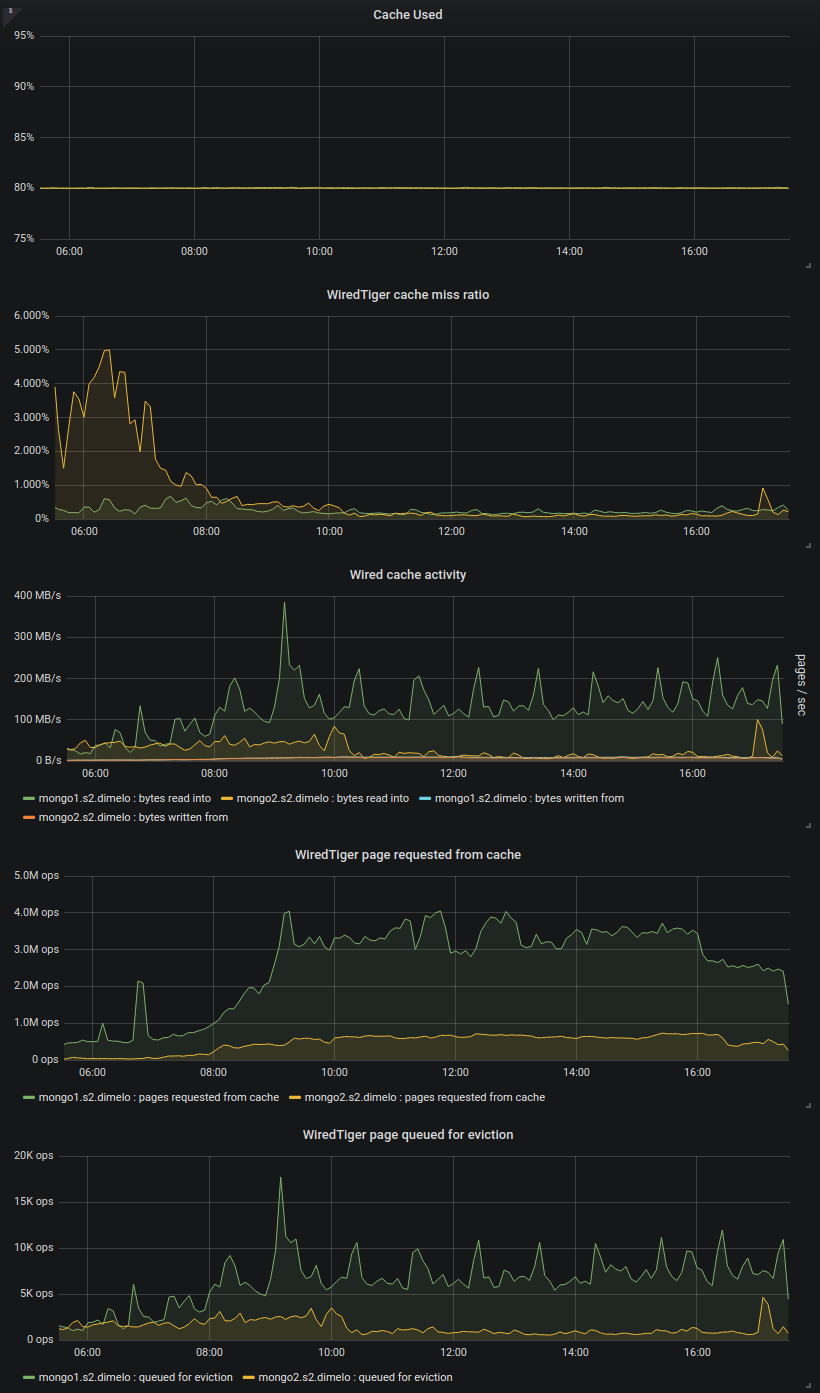
You have the diagnostic.data already uploaded for these 2 servers during this operation in SERVER-42662, it was yesterday (August 7th) at 17:40 UTC+2
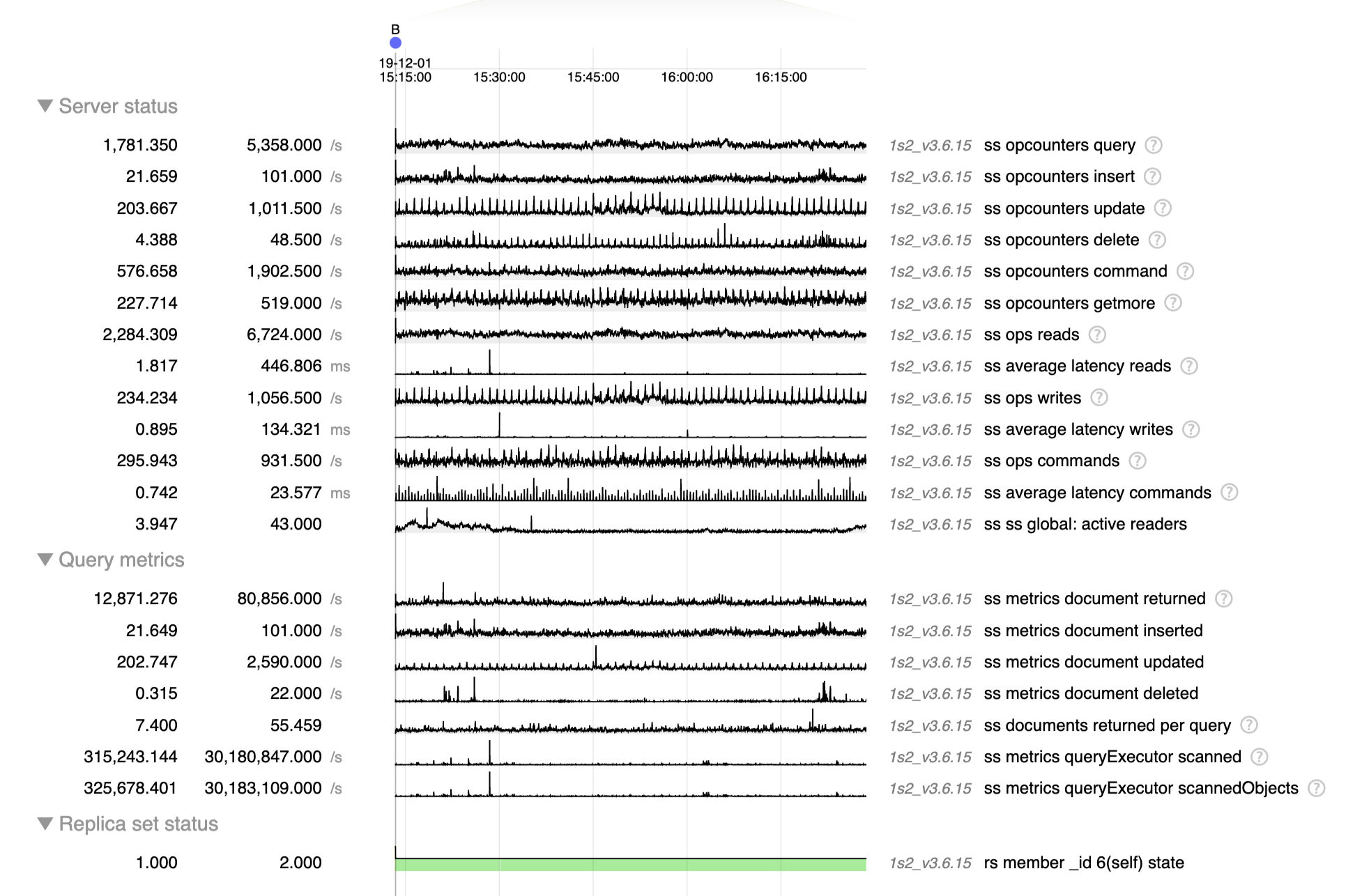
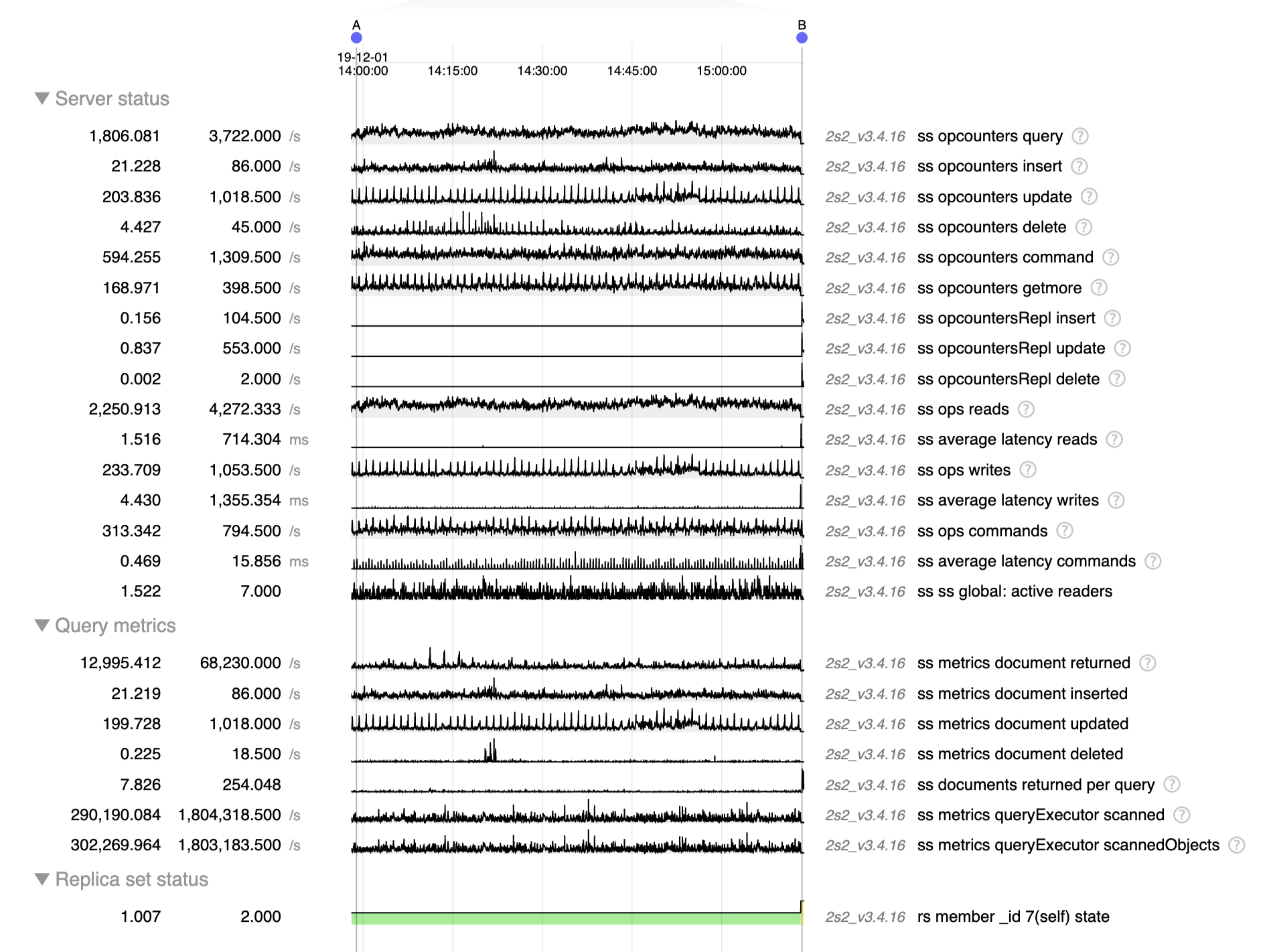












- related to
-
-
- Closed
-