-
Type:
Task
-
Resolution: Unresolved
-
Priority:
 Major - P3
Major - P3
-
None
-
Affects Version/s: None
-
Component/s: Compaction
-
Storage Engines - Persistence
-
5,941.89
-
StorEng - Defined Pipeline
-
None
There have been multiple efforts to fix and improve the performance of compact, however, despite these fixes it still has dramatic impacts on performance, particularly during concurrent write workloads.
This ticket investigates the performance of compact during concurrent write workloads. I've attached a ctest main.c![]() that reproduces a very slow compact operation due to update operations running concurrently. The changes are also on the branch wt-14196-compact-investigation
that reproduces a very slow compact operation due to update operations running concurrently. The changes are also on the branch wt-14196-compact-investigation
Test
Parameters
- cache_size=20GB
The following are the default in MongoDB: - allocation_size=4KB
- leaf_page_max=32KB
- leaf_value_max=64MB
- memory_page_max=10m
- split_pct=90
Workload
- Populate phase
- Insert 1million k/v pairs of varying sizes. 512B < value < 4KB. This results in varying size blocks to increase fragmentation.
- On-disk size ~5GB
- Remove phase
- Remove every 3rd key to create fragmentation.
- Run 3 threads concurrently (compact, checkpoint, update ops)
- The compact thread triggers compact on the table.
- The checkpoint thread calls checkpoint periodically.
- The update thread continually updates the existing keys that were not previously removed with random values.
- Wait for compact to finish.
Observations
There are multiple aspects surrounding compact to cover here. The primary issue is the impact compact has on the throughput of the update operations and the time it takes to do a single pass of compact (walk of the btree). Why is this so slow? Profiling this test case gives us a flame graph that shows we're spending a significant amount of time in the function block_first_srch. This function is called during a write operation and linearly walks the offset extent list to find a hole (available extent) that the new block can fit into. When compact is running on a table it sets the block allocation mode to first-fit which tells the block manager to use this block_first_search method. Normally, allocation is based on a best-fit approach and walks the size-sorted extent skip list, quickly finding an appropriate extent offset. The problematic block_first_search is seen in both the compact thread and the eviction thread. block_first_search is called while holding the live_lock, as it accesses and modifies the extent lists. This is why both the compact thread and all other operations are slow.

Similarly, the checkpoint thread faces the same issue. This likely contributes to the "long checkpoints" we've previously observed while running compact.
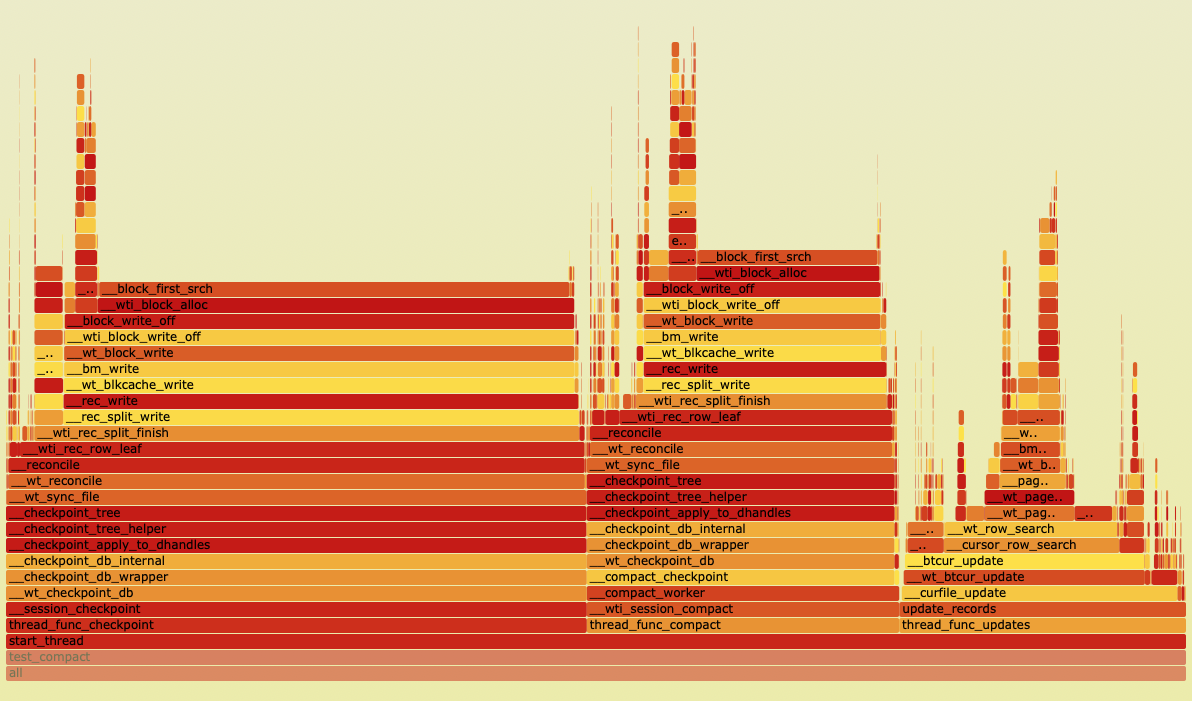
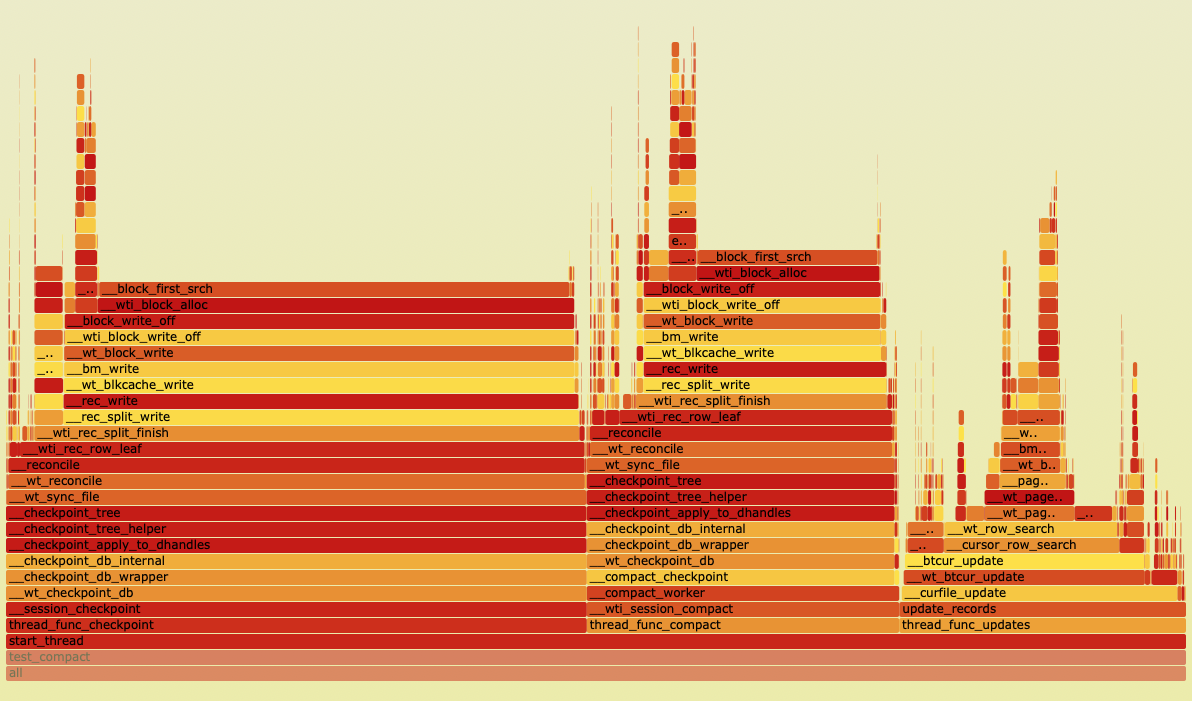
Another observation from profiling this test is that this problem continues to get worse over time while compact is running. The linear walk of block_first_search takes an increasing amount of time. This is because blocks are moved to the front of the file and the block_first_search walks the list in offset order. Further, the first-fit allocation method can worsen the fragmentation by creating many small extents in the list. This observation aligns with the increasing time checkpoint takes under compact in customer cases. Here is a flame graph profiled after running the test for 5 minutes:

Adding a metric to count the number of extents walked in this search also shows the extent list walk increasing:

Note: These observations were made after disabling the various checks compact uses to decide whether to proceed or not. There are now many cases where if it fails to enough work, it will bail.
Given this information, we should rethink the allocation methods for the compact algorithm.
As a more immediate investigation to answer questions in the field, we should answer how the parameters affect the behaviour of compact:
- small vs large cache_size
- can eviction parameters help?
- what happens if you change the default allocation size? (this would be an unlikely parameter to change in the real world).
We should also figure out what conditions in the workload exacerbate or alleviate the slowness:
- constant vs varied size values
- blocks/pages containing large single values. This can be up to leaf_value_max.
Since we often see customers observing slow compact we should also use this example to judge whether we're providing enough information in the logs. Are the current progress/estimation logs sufficient? The current estimation logs assume a consistent state of the file, however this changes under concurrent write workloads. We should clarify this if it's not already in the documentation or logs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- is related to
-
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
WT-13900 Investigate ways for improving compact efficiency
-
- Closed
-
- related to
-
WT-16682 Assess disk fragmentation in the fleet
-
- Open
-