-
Type:
Task
-
Resolution: Done
-
Affects Version/s: None
-
Component/s: None
-
108,029.034
-
None
-
None
I've been profiling a workload that runs regular checkpoints while pounding away with reads and inserts. The workload runs for a long time, has 20 threads doing inserts, 20 threads doing reads and checkpoints running every 20 seconds.
After the system has been running for a while, I get to the point where it takes between 500 and 1000 seconds for each checkpoint to complete.
When I look at stack traces I see quite a lot of waiting on the block->live_lock. I've included a pmp output that includes all threads that are in the block subsystem below. I've realized that I don't understand much about that code, would you mind walking me through the code on the phone next week?
At first I wondered whether the skip lists were growing large enough that operations were slowing down, but it doesn't look like it. I added the following change:
--- a/src/block/block_ckpt.c
+++ b/src/block/block_ckpt.c
@@ -542,6 +542,10 @@ __ckpt_process(
live_update:
ci = &block->live;
+ fprintf(stderr, "block_checkpoint lists:\n\t avail entries: %" PRIu64
+ "\n\tdiscard entries: %" PRIu64
+ "\n\talloc entries: %" PRIu64 "\n",
+ ci->avail.entries, ci->discard.entries, ci->alloc.entries);
/* Truncate the file if that's possible. */
WT_ERR(__wt_block_extlist_truncate(session, block, &ci->avail));
The outputs from it are:
block_checkpoint lists: avail entries: 1 discard entries: 0 alloc entries: 1864 block_checkpoint lists: avail entries: 1 discard entries: 0 alloc entries: 1 block_checkpoint lists: avail entries: 0 discard entries: 0 alloc entries: 215950 block_checkpoint lists: avail entries: 1 discard entries: 0 alloc entries: 2 block_checkpoint lists: avail entries: 0 discard entries: 0 alloc entries: 446437 block_checkpoint lists: avail entries: 1 discard entries: 0 alloc entries: 1
So.. The skip lists are growing, but they shouldn't contain enough elements to cause our depth of 10 to be a problem.
6 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_write_off,__wt_block_write,__wt_bt_write,__rec_split_write,__rec_split_finish,__rec_split_finish,__rec_row_leaf,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_search,__curfile_search,worker,start_thread,clone
4 pwrite64,__wt_write,__wt_block_write_off,__wt_block_write,__wt_bt_write,__rec_split_write,__rec_split_finish,__rec_split_finish,__rec_row_leaf,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_insert,__curfile_insert,worker,start_thread,clone
4 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_search,__curfile_search,worker,start_thread,clone
3 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_insert,__curfile_insert,worker,start_thread,clone
2 pread64,__wt_read,__wt_block_read_off,__wt_block_read_off,__wt_bm_read,__wt_bt_read,__wt_cache_read,__wt_page_in_func,__wt_page_swap_func,__wt_row_search,__wt_btcur_insert,__curfile_insert,worker,start_thread,clone
2 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_write_off,__wt_block_write,__wt_bt_write,__rec_split_write,__rec_split_finish,__rec_split_finish,__rec_row_leaf,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_insert,__curfile_insert,worker,start_thread,clone
1 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_write_off,__wt_block_write,__wt_bt_write,__rec_split_write,__rec_split_fixup,__rec_split,__rec_row_leaf,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_search,__curfile_search,worker,start_thread,clone
1 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__wt_sync_file,__wt_bt_cache_op,__wt_conn_btree_apply,__checkpoint_apply,__wt_txn_checkpoint,__session_checkpoint,checkpoint_worker,start_thread,clone
1 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__wt_page_in_func,__wt_page_swap_func,__wt_row_search,__wt_btcur_insert,__curfile_insert,worker,start_thread,clone
1 __lll_lock_wait,_L_lock_927,__pthread_mutex_lock,__wt_spin_lock,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__evict_lru,__evict_worker,__wt_cache_evict_server,start_thread,clone
1 __block_off_srch,__block_ext_insert,__wt_block_off_remove_overlap,__wt_block_off_free,__wt_block_free,__rec_write_wrapup,__wt_rec_write,__rec_review,__wt_rec_evict,__wt_evict_page,__wt_evict_lru_page,__wt_cache_full_check,__cursor_enter,__curfile_enter,__cursor_func_init,__wt_btcur_search,__curfile_search,worker,start_thread,clone
For completeness, the wtperf workload I'm running is:
# wtperf options file: small btree multi-database configuration # Original cache was 500MB. Shared cache is 500MB * database_count. conn_config="statistics=[fast,clear],statistics_log=(wait=20),cache_size=10GB,log=(enabled=false),checkpoint_sync=false" database_count=1 table_count=1 table_config="os_cache_dirty_max=200MB,leaf_page_max=4k,internal_page_max=16k,leaf_item_max=1433,internal_item_max=3100,type=file" # Likewise, divide original icount by database_count. icount=50000 populate_threads=1 random_range=100000000 checkpoint_interval=20 checkpoint_threads=1 report_interval=5 run_time=2400 threads=((count=20,reads=1),(count=20,inserts=1)) value_sz=250 verbose=1 warmup=20
Based on the develop branch (I was seeing similar behavior on new-split).
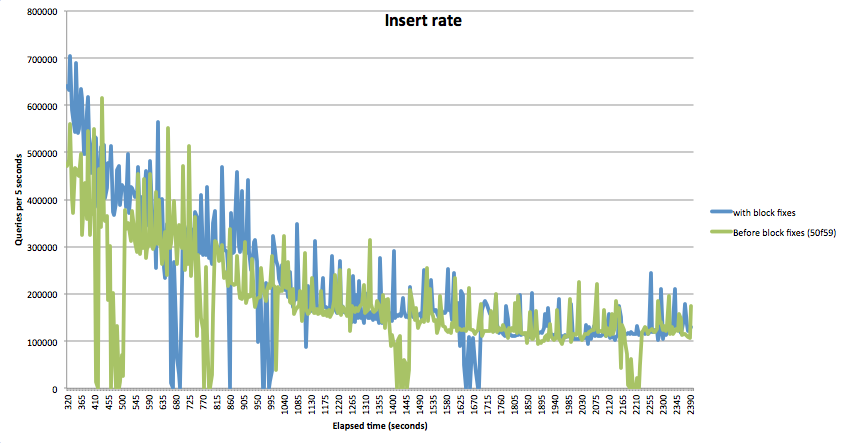
- is related to
-
- Closed
-
- Closed
- related to
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed
-
- Closed