-
Type:
Improvement
-
Resolution: Gone away
-
Priority:
 Minor - P4
Minor - P4
-
None
-
Affects Version/s: 3.3.8
-
Component/s: Block Manager
-
Environment:Linux 5.4.0
-
35,756.468
-
None
-
None
Summary
I am using MongoDB on an NVMe SSD, the workload is write-intensive, and I configured mongod with "–journalCommitInterval 2" and others as default. I find the system performance is I/O bounded:
Motivation
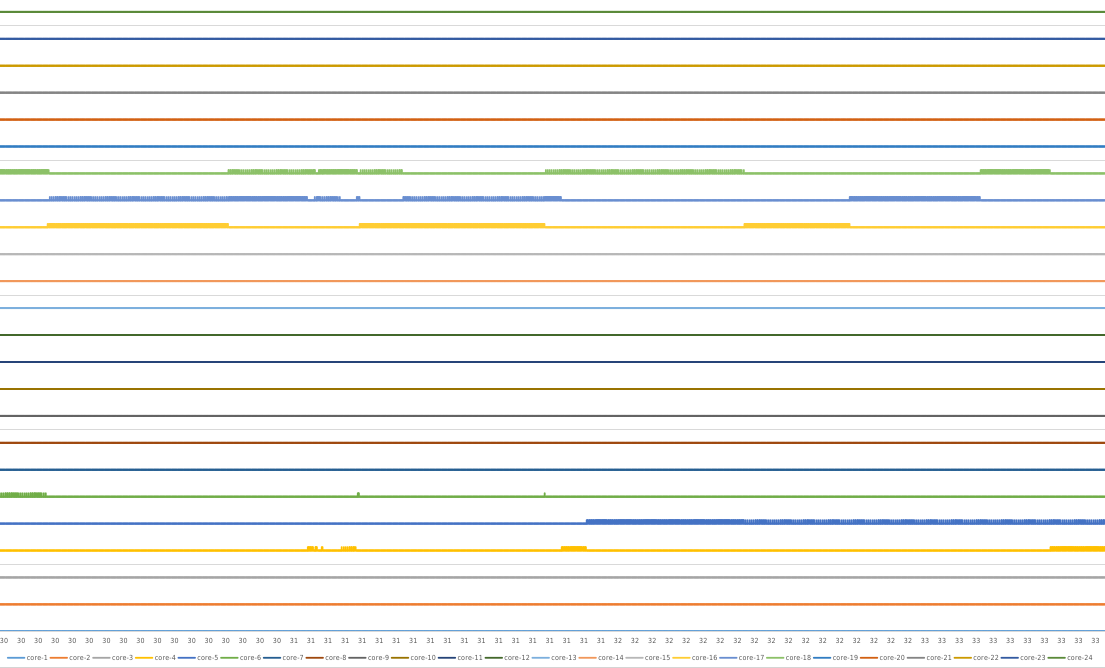
I dig into the nvme-driver queue to find out if the I/O requests are properly (efficiently) sent to the device but find nearly all the time, only a single queue is working busily. As shown in the following figure (X-axis: time in second. Y-axis: queue-depth per CPU core):

In this figure, the max io-depth is only 1. And the time-space (time when the queue is empty) between adjacent requests are sometimes very small (i.e., 23 us), which seems that the second request is intentionally waiting for the former one to compelete. But there is no barrier between them.
I think the reason behind this is that the writer process uses Linux sync I/O, write(2) in one process. While using "fio" to benchmark can find that async I/O (or multi-threaded sync I/O) is faster on my device.
Since storage devices are fast evolving, maybe it will be good for performance if we can better utilize the multi-queue mechianism of new devices?
Therefore, I suggest that WiredTiger can make the write async when possible. Or else, using multiple background writer processes/threads just like MySQL background-writers and PostgreSQL's re-thinking and re-designing of I/O engine.
Moreover, WiredTiger has already supported direct I/O to "avoid stalling underlying solid-state drives by writing a large number of dirty blocks". So why not step further to make it support async + direct I/O?
- Does this affect any team outside of WT?
N/A
- How likely is it that this use case or problem will occur?
N/A
- If the problem does occur, what are the consequences and how severe are they?
N/A
- Is this issue urgent?
not really, thinking and designing the I/O model should be careful, but I think it will very encouraging to see the improvement in some future versions.
Acceptance Criteria (Definition of Done)
- Testing
Performance improvement
- Documentation update
N/A
[Optional] Suggested Solution
io_uring + O_DIRECT + advanced buffering.
- related to
-
WT-6833 Implement asynchronous IO using io_uring API
-

- Closed
-